
Editor’s Note: This text course is an edited transcript of a live webinar. Download supplemental course materials.
Wendy Cheng: Good afternoon. My name is Wendy Cheng, and I am President of the Association of Adult Musicians with Hearing Loss (AAMHL). One of the biggest challenges our members face is that while audiologists are experts in amplification, they may not have training or knowledge about music performance, and how music as a signal is optimized with hearing aids and cochlear implants. For this reason, I would like to thank AudiologyOnline for hosting the webinar series on amplification and music.
We are honored to have Dr. Marshall Chasin presenting the webinar today. Dr. Chasin, thank you in advance for your time and expertise – at this time I’ll turn the microphone over to you.
Marshall Chasin: Thank you, Wendy. Today’s presentation is not necessarily about musicians and hearing aids; it is more about music and hearing aids. The topic of music and hearing aids is not a software issue, but more of a hardware issue. For further reading on this topic after today’s webinar, I encourage you to visit www.musiciansclinics.com and search the Articles section.
Music Versus Speech as an Input to Hearing Aids
There are four differences between music as an input to hearing aid and speech as an input to the hearing aid that I will discuss today: 1. shape of the spectrum; 2. phonemic versus phonetic requirements; 3. differing sound levels or intensities; and 4. crest factors.
1. Speech and Music Spectra
First, if we look at the spectrum or the shape of the energy of speech, it is no surprise that the long-term average speech spectrum (LTASS) is well-defined. This is true whether the speech is English, Portuguese or Chinese. Adults have a vocal tract that is roughly 17 to 18 centimeters long, closed at the end of the vocal chords and open at the other (at least for vowels and other sonorants). The anatomy is complicated but well defined, and includes the lips, soft palate, hard palate, and nasal cavity, etc. The long-term speech spectrum is well defined and used in the calculation of targets for hearing aid gain and output.
In contrast, a music spectrum is highly variable. It may come from stringed instruments, brass instruments, percussive instruments, and voices. In short, there is no such thing as a long-term music spectrum. If you look at the LTASS in one-third octave bands, they are close to the critical bandwidth, and speech falls off at six or seven dB per octave. Music can be very similar. The pink line in the graph below (Figure 1) is the LTASS from Cornelisse, Gagnńe, & Seewald (1991). Over that, I put the violin in blue. It is a little bit louder, but, like speech, most of its energy is in the lower frequency range and falls off for the higher frequencies. However, when we add percussion into it, there is no similarity at all (dark black line).
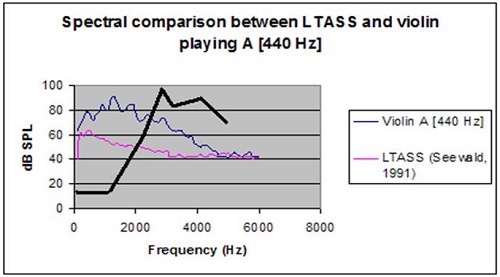
Figure 1. Spectral comparison between LTASS (pink) and violin (blue). Percussion overlay is represented by the thick black line.
2. Phonemic/Phonetic Requirements
The second difference between speech and music is what I refer to as phonemic versus phonetic requirements. First, we know that speech has most of its energy in the sonorants, which are lower-frequency vowels, nasals, and liquids. The least amount of energy resides in the higher frequencies consonants. While this is straightforward, one of the challenges with fitting amplification is that clarity (for English) depends on the areas of the spectrum that have the least amount of energy. In other words, according to the Speech Intelligibility Index (SII) most of the intelligibility of English comes from the mid to high frequencies with very little intelligibility in the lower-frequency vowel region.
Perceptual requirements for music depends on many factors. For example, when I say, “That is a wonderful violin sound,” I am referring to the magnitude of the third or fourth harmonic relative to the magnitude of the fundamental. That defines one of the differences between a Stradivarius versus a student violin model. The perceptual requirement of a violinist is broadband- in the lower frequency range, it’s the fundamental; and in the higher frequency range, it’s the harmonic structure.
I am a clarinet player, and when I say it is a great sound, I am referring to the inter-resonant, lower-frequency breathiness. Despite the fact that my clarinet can generate an almost identical spectrum to the violin in terms of the bandwidth, I only need to hear the sounds below 1000 Hz. I do not pay attention to anything above 1000 Hz to know it has a great sound.
Despite having similar output spectra (similar phonetic representation), the underlying cues that are important for optimal perception (the phonemic representation) can be quite different.
3. Differing Sound Levels
The third difference between speech and music is the sound level. We know that conversational speech at 1 meter is about 65 dB SPL, plus or minus 12 dB. It ranges from the quiet interdental fricative “th” (as in ‘thing’) at 53 dB SPL, to about 77 dB for the low back vowel “ah” (as in ‘father’). Loud speech can reach levels of 80 dB to 85 dB SPL. It is difficult to have conversational speech in excess of that figure. However, even quiet music can reach levels of 105 dBA, with peaks in excess of 120 dBA.
4. Crest Factor
The fourth difference is the crest factor. We deal with this every day. For example, we set a hearing aid to reference test gain in order to test frequency response, distortion, or internal noise measures. But what is reference test gain? It is the output sound pressure level (OSPL) 90 - 77 dB. Why 77 dB? Well, 77 dB is 65 dB average speech plus 12 dB. Why 12 dB? This is the crest factor. The crest factor is the difference between the average or root mean square (RMS) of a signal and its peak. It turns out that speech has a crest factor of about 12 dB, hence the 77 dB. Musical instruments, though, have less internal damping. There are no soft cheeks, soft lips, soft palate, nasal cavity, or narrow nostrils with violins, clarinets, and guitars.
In speech, the peaks are highly dampened. They are only about 12 dB more intense than the average. With music, however, the crest factor can be upwards of 18 or 20 dB. This means that the peaks can be 18 to 20 dB higher than average for music. In summary, speech is about 65 dB at 1 meter; music can well be over 100 dB. Speech has a 12 dB crest factor, and music has an 18-20 dB crest factor. Speech rolls off at about 6 dB per octave after 500 Hz, but music can have variable slopes. We have a well‑defined SII for speech and well‑defined fitting targets. However, we have no such Music Intelligibility Index (MII?) and no target. Additionally, speech has context in conversation. With music, we are very hesitant to miss out on anything because there is really no context. Even if I sing, “La, la, la, la, ___, la” in a rising scale, when I skip a predictable note in the sequence, we cringe. We do not allow ourselves to tolerate any missing information with music. With speech, we can, and do, fill in the blanks.
Hearing Aids and Musicians
What about hard-of-hearing musicians or the 75‑year‑old patient with presbycusis who likes to listen to music on occasion? The peak input limiting level is by far the most important element. This is true of cochlear implants, and also true of hearing aids; any amplifier that has an analog-to-digital (A/D) converter, or any digital device. You will not find the peak input limiting level on a hearing aid spec sheet. It is not part of ANSI S3.22, which is standard for testing hearing aids. After all, that standard is a testing standard, or quality control standard. If we say that a hearing aid is made of chocolate and distorts at 100%, and we see that in the spec sheet, then that hearing aid passes, because it meets the standard; never mind if it is made of chocolate. We do not have any performance standards in our field of how it should function; just how to report the electro-acoustic behavior.
Think of the parameter, “peak input limiting level” as the ceiling. Hearing aid microphones can handle 115 dB SPL with no problems and this has been true since 1988. Then, after the microphone, we have the A/D converter. Therein lies an element that is poorly designed. As part of the A/D converter is the peak input limiter. It could be a compressor or peak clipper, but it has a ceiling. We colloquially call this the “front end of the hearing aid”. In the 1930s and 1940s, we had a peak input limiting level built into hearing aids to limit any sound inputs over 85- 90 dB SPL. After all, it was not speech. This peak input limiter was a rudimentary noise reduction technique. Sounds in excess of 90 dB could not get through, because the peak input limiting level was set to 90 dB.
In the 1980s, the ceiling went up a little bit, and that was fine because we had amplifiers that did not distort. In fact, the K‑AMP in 1988 allowed for a peak input limiting level of 115 dB- the limit of the microphone (which is also the case today). With modern technology, we are dealing with a 16-bit A/D converter, and, at the best of times, it has a dynamic range of only 96 dB. As long as we are dealing with 16-bit systems, that is a limit or a ceiling. This is fine for speech but can be problematical for music.
The peak limiting occurs after the microphone. We sometimes refer to it as overloading the “front end”, because it is placed before any software adjustments, even before the sound has been digitized with the A/D converter. Once something is distorted early on, no software programming later on will fix it.
There are several analogies we can use to describe the effects of low hanging ceilings. This is like a low-hanging bridge. Imagine a plane coming up to it, and unless the bridge raises up or the plane dives down, we are going to be in big trouble. That is one technology that is now available in our field. We will be talking about it shortly. Another analogy is a low-hanging bridge. If you are in London, England on a double decker bus going through the countryside with low hanging bridges, sit on the bottom part, not the top. A low bridge would chop the top right off. The same is true in a hearing aid with a limited input dynamic range. Sound, like a chopped off double decker bus, would not be able to be improved.
Mead Killion, Russ Tomas, Norm Matzen, Mark Schmidt, Steve Aiken and I took to building our own hearing aid. We created a hearing aid where the only thing that changed was the peak input limiting level; not the gain, not the bandwidth, not the compression, and not the output. With a control, I was able to reduce it from 115 dB SPL, the limit of modern microphones, to 105, to 96 to 92, and then back to 115. The audio files showing progressively greater distortion as the peak input limiting level is dropped from 115, 105, 96, 92, and back to 115 dB SPL, can be found at www.chasin.ca/distorted_music.
Once it sounds this bad, do not waste your time with software. The conclusion is that the peak input limiting level should not be 85, 90, or even 92 or 96 dB. It should be at least at 105 dB, if not higher.
You will see an abundance of marketing related to frequency-response changes in the manufacturers’ software. Depending on the manufacturer, some of these changes have low cuts; some of them have high cuts; some of them increase the high-frequency bandwidth; some of them decrease the mid-range bandwidth. For all combinations of software changes, none work well. It is not that they are of minimal use; it is that they are of no use. If you can get a broadband response in the high frequencies for speech, there is no reason to increase it for music. If you can get it at all, you should use it for speech too. These software changes are for marketing purposes only. Unless you take care of the front-end problem, nothing you do later on in the hearing aid processing circuitry, will be better.
Clinical Strategies
Let's talk about four clinical strategies. What if we have a patient who loves their hearing aid for speech, but wants to have improvement for music? We do not want to sell them another hearing aid. What can we do for our clients and patients to help them hear music?
1. Lower the Volume, Increase the Gain
Lower the volume on the input and increase the gain on the hearing aid. In other words, lower what is coming into the A/D converter, and then if necessary, turn up the volume control, which occurs later on in the processing of the software. It is like ducking under the bridge. If one is in the car, turn down the car radio and turn up the volume of the hearing aid. It is not perfect, as there might be car noise that will also be amplified, but it is better than the converse, where the radio would be turned up causing distortion in the front-end of the processing in the hearing aid.
2. Use FM as Input
The second strategy is to use an assistive listening device, such as an FM system that has volume control, and hook it into the direct audio input or inductive (NFMI) coupling. Each route in to a hearing aid has their own A/D converter. Using a non-microphone route will not solve the problem. You can use the FM or assistive listening device to reduce the volume, plug it in, and then, if necessary, turn up the volume on the hearing aid. Again, this is ducking under the bridge.
3. Use Creative Microphone Attenuators
Use creative microphone attenuators. I use Scotch tape. I tell my patients to take four, five, or six layers depending on the gauge of the tape, and place it over the microphones. It decreases the microphone sensitivity by 10 or 12 dB. If the listener is going to a concert, have them pre-measure four or five layers of tape. While they are in the concert, have them put the tape over the microphones and listen. Usually this lowers the input level to a point that the A/D converter can transduce it without any distortion, and then after the concert, take it off. It is low tech, but it works really well.
4. Take off the Hearing Aids
Lastly, take off the hearing aids. Since music is at a higher sound level than speech, perhaps removing the hearing aids would be the best thing.
We know that soft-level inputs for hearing aids for a person with a 60 dB loss might require 20 or 30 dB of gain. For higher levels, it may be less, and for very high levels where music is, which is higher than speech, you might not require any amplification. One strategy is to take off the hearing aid. Figure 2 is a chart made from the information in Fig6 (Killion & Fikret-Pasa, 1993). Let’s say this patient has a 60 dB sensorineural loss and they require about 28 dB gain at a 65 dB input. For very loud speech, or 80 dB, which is relatively quiet music, the gain is 15 dB. Average music, which is 95 dB or loud speech, it might only be 2 or 3 dB. Realistically for music, which is inherently louder than speech, the listener might not even require amplification.
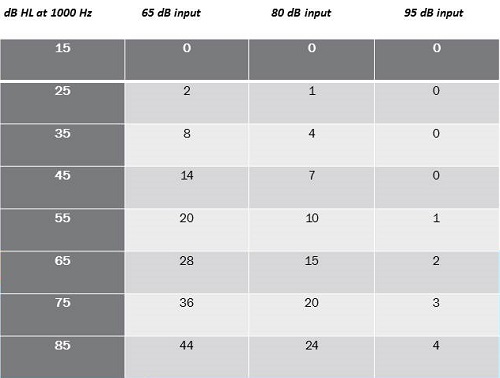
Figure 2. Input at 65, 80 and 95 dB and subsequent gain requirements for differing levels of hearing loss.
Let’s look at the crest factor for a moment (Figure 3). Remember that the crest factor is 12 dB for speech, and 18 dB for music. This was all measured historically at 125 milliseconds or 1/8th of a second. That started in 1940 by Dunn and White, and was again verified by Cox and Moore in 1988. The bottom line is that can be erroneous. Let's think about why. They all use a 125 millisecond window of analysis when they calculate the crest factor. Well, 125 milliseconds happens to be one of the temporal time constants of a cochlea. We simply cannot integrate sounds shorter than 1/8th of a second, or 125 msec. Phonemes have to be longer than that, and 125 seconds makes perfect sense for speech. However, we are not dealing with the input to the cochlea. We are dealing with an input to a microphone and the A/D converter. This is long before the signal gets through the hearing aid, and certainly long before it gets to the individual. We are not limited by the same cochlear constraint of 125 milliseconds.

Figure 3. Analysis window (msec) and measureable crest factor for speech.
When you do measure in a 125 millisecond window, you get 12.46 dB in this example (Figure 3). But when you have a smaller window at 100, 50, or 25 milliseconds, that number changes to almost 17 dB. It could be that the crest factors, in reality, are higher than what we think they are. What does this mean? Dunn and White (1940) and Cox and Moore (1988) both measured speech to be 65 dB at 1 meter. However, average conversational speech at the level of my own ear if I am a hard‑of‑hearing person might be 84 dB SPL. Add 12 dB for the crest factor, and that is 96 dB. This is close to the peak input limiting level.
What if the crest factor is 16 or 17 dB? That is far in excess of what modern hearing aids can handle. This is something that music is teaching us about speech. Some of the technologies to improve music can be technologies to improve the quality of a hard-of-hearing person's own voice. A hard‑of‑hearing person has a distorted sound of their own voice at the level of the microphone because of its high sound level, and that is problematic. It is not just for music.
Technical Innovations
Let's talk about four technical innovations and how the hearing aid industry has responded. Four things come to mind.
First, we have a -6 dB per-octave low-cut microphone. Second, we are able to shift the dynamic range upwards. The dynamic range of a 16-bit system is 96 dB between the quietest and highest levels. No one said it had to be between 0 dB SPL and 96 dB SPL. It can be 15 dB to 111 dB SPL. This is a technology based on definition of dynamic range. Third, we can have front-end compression prior to the A/D converter. Today, we do have an analogue compressor that ducks below the bridge so to speak, compresses the signal, puts it through A/D converter, and then digitally expands to the other side. Fourthly, we can use post 16-bit architecture. Integrated circuits are available that are 20- and 24-bit systems that would resolve this issue.
1. -6 dB/Octave Low-Cut Microphone
We routinely fit patients with non‑occluding behind the ear hearing aids (BTEs) when they have normal hearing up to 1000 Hz but fall off after that. However, we still encounter problems, because non‑occluding BTEs use a broadband microphone, meaning there is equal sensitivity at 200 Hz and 6000 Hz. Because of the broadband microphone, the lower frequencies will still go into the hearing aid, unless the microphone is less sensitive in the lower frequencies. Because of the non‑occluding nature of the fitting, the low frequencies escape back out, and you are not aware of it. Unfortunately, you still hear the higher frequency distortion components that are caused by the primary low‑frequency signals that get through and leak out the ear canal. The distortion stays in the ear canal, and that can be quite audible. Instead of using a broadband microphone for these high-frequency emphasis fittings, why do we not have one that has reduced sensitivity of -6 dB at 500 Hz and -12 dB at 250 Hz? This low-cut (- 6 dB/octave) microphone has been commercially available for many years.
That is what I mean by using a desensitized microphone, such that the high level, low‑frequency sound energy does not overdrive your system. Unitron has done this, which says something about their company, but any manufacturer can do it. One of the reasons some manufacturers did not want to do this was because of the internal noise level.
The pink line in Figure 4 shows an increase of output in the lower frequencies. It is a low-cut microphone that is less sensitive in the lower frequencies. As you can see, there is a much higher internal noise level. Many manufacturers threw their hands in the air when considering how to handle this.
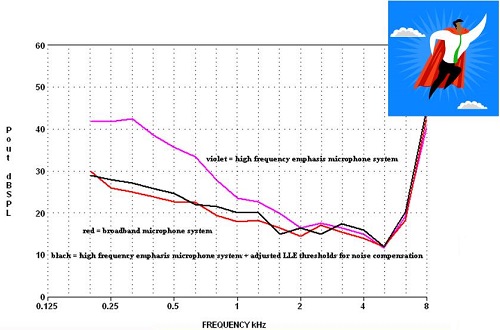
Figure 4. Comparisons between high-frequency emphasis microphone system (pink), broadband microphone system (red), and high-frequency emphasis microphone system compensated by expansion (black).
However, the superhero is expansion. If you maximize expansion, the internal noise level drops down, shown as the black line in Figure 4, to what it would have been had you used a broadband microphone. If you maximize expansion using this technique, there are no deleterious effects.
Figure 5 shows the frequency response of a broadband microphone to music at differing inputs: 95 dB is yellow, 100 dB is blue, 105 dB is gray, and 110 dB is black. You can see how the distortion skyrockets with the increase in intensity. What happens if you use Unitron’s low-cut, desensitized microphone? The distortion goes away (Figure 6). This low-tech alternate microphone technique resolves the problem. The intense low‑frequency sounds have been reduced and sent to through the hearing aid.
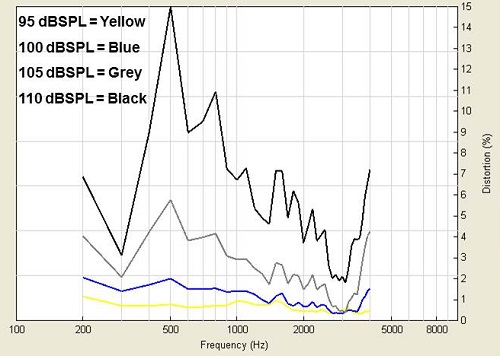
Figure 5. Frequency response of a broadband microphone to music at 95 dB (yellow), 100 dB (blue), 105 dB (gray), and 110 dB (black).
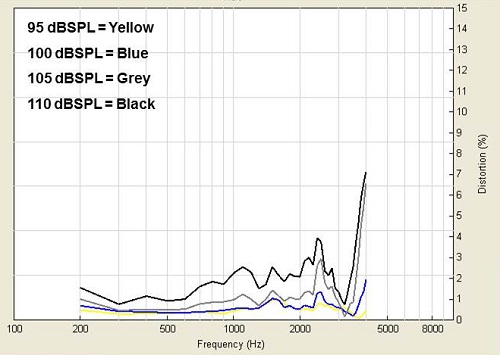
Figure 6. Frequency response with a low-cut, desensitized microphone to music at 95 dB (yellow), 100 dB (blue), 105 dB (gray), and 110 dB (black).
2. Shifting the Dynamic Range Upwards
Bernafon uses a technique called Live Music Plus to shift the dynamic range upwards. You can go to their website and read the article on this by Hockley, Bahlmann, and Chasin (2010). Bernafon has understood the definition of dynamic range in their 9-series hearing aids. Instead of it being 0 to 96 dB SPL, it is 15 to 111 dB SPL, which is a region that is much better suited to music and also the human voice for hard‑of‑hearing people. The dynamic range is still 96 dB but it is now in a range that is better suited to music.
3. Reduce the input before the A/D converter
Another approach comes from Widex, who recently introduced a product called Dream. I wrote an article in January 2014 for Hearing Review about this. The Dream uses a transformer effect by doubling the voltage, such that it is akin to ducking under the bridge with the plane. Whether it is technically ducking under the bridge or being transformed by some other technique, the signal is getting passed to the A/D converter in a region that it can handle and is distortion free. It is very useful. It is like using a compressor prior to the A/D and then expanding digitally afterwards.
In the article (Chasin, 2014), I compared the Dream to Widex’s old technology, Clear. These two hearing aids are essentially the same, except for the new innovation in the Dream. With high-level inputs, the preference of users in the study (n=10) was statistically significant for the Dream, as opposed to the older technology. With lower level inputs like speech, there was not a big difference in preference for the Dream or the Clear.
4. Post 16-Bit Architecture
There are many circuits now with 20- and 24-bit systems. Sound Design, which used to be Gennum, was acquired by ON Semi-Conductor, and they have both the Wolverine (from Sound Design) and the Ezairo 5900 (from ON Semi-Conductor); I understand that a new 7000 model is coming out shortly. These post-16 bit architecture circuits have a 121 dB dynamic range rather than only a 96 dB range, which would be wonderful to use with hearing aids.
Everything Else
Let’s now talk about everything else, which is summarized in Figure 7. One thing that is not on the list is frequency response. If a person has a mild loss, then you should have the broadest possible bandwidth. This is true for speech and music. If a person has steeply sloping loss greater than approximately 60 dB, then a narrower frequency response may be better. This goes back to Brian Moore’s (2004) dead regions in the cochlea, namely the inner hair cells. For a milder loss, it is usually the outer hair cells that are affected and a loudness growth issue. This is true for speech and music.

Figure 7. Summary of extra considerations when programming hearing aids for music.
1. One Channel is Best
Let's talk about how one channel is best. This gets back to the perceptive (phonetic/phonemic) requirement. For stringed instruments, like the violin, the magnitude (or the height) of the fundamental frequency should have a certain relationship to the magnitude of the third, fourth or fifth harmonic. The difference between a wonderful sounding violin and poor sounding violin is that these magnitude differences are altered. Imagine a multi‑channel hearing aid that is wonderful for speech in noise- but perhaps not so great for music. One can have the fundamental in the lower frequency being treated differently in terms of gain than any of the higher-frequency harmonics. It would destroy the musical relationship. It would be ideal to have a single-channel hearing aid for music. The K‑AMP of 1988 was single channel but we do not have a wide selection of commercially available single-channel hearing aids today- actually the K-AMP is still available in certain markets such as the United States through www.GeneralHearing.com.
This is something for us to talk to the manufacturers about. For music, can we have a single channel? You might be able to bootstrap a single channel-like hearing aid by having similar compression and kneepoint characteristics for all channels, but that is not quite the same thing as having a single channel. If you are in a heavily stringed music listening situation, you may want to have a single channel. In an environment that is not heavy on the stringed instruments, you may get away with multi‑channel system using the same channel number and set-up, as speech in quiet.
2. Similar Compression
Compression has more to do with the person's damaged cochlea rather than the nature of the input signal. There is no inherent reason why it should be different depending on the nature of the input signal. The goal with compression is to reestablish normal loudness growth in the damaged cochlea. There is no inherent reason why compression for music should be any different than for speech in quiet. I wrote about that in 2004 with Frank Russo. However, Davies-Venn, Souza, and Fabry (2007) found empirically that that was the case.
3. Disable Advanced Features
For most forms of music, usually the signal‑to‑noise ratio is +40 or +30 dB. Music is so high compared to the environmental noise. A person cannot hear the microphone noise from their hearing aid, even if they have excellent acuity in the lower frequencies. For this reason, it is reasonable to disable any circuitry that reduces the internal (microphone) noise.
Disable the feedback system for music as well. Sometimes it is difficult for the hearing aid to determine whether the input is a harmonic or feedback. Sometimes you see cancellation of many of the harmonics of the sound. Also, if the music is classical, where it stops abruptly, the canceled signal can become audible for a moment and the listener will hear chirping. If you can disable the feedback system, do so.
I do want to mention a product in the marketplace from Etymotic Research. They have a personal sound amplification product (PSAP) called the BEAN. It is the K-Amp in disguise. The BEAN is an analog device, so there is no A/D converter to distort the signal. If you have a patient with a premium hearing aid and have not been able to satisfy their listening demands for whatever reason, a less expensive PSAP, such as the BEAN, would be perfect. To my knowledge, the BEAN is the only analog PSAP that also has a high peak-input limiting level that will not distort.
4. Frequency Transposition
A musician knows that a B on the music scale sounds like a B, and not a C or a D. They may have auditory training and adapt to this new sound in six months, but the musician wants their hearing aid now. If you implement some sort of frequency transposition, that hearing aid will be back in your office, not in a month, but in an hour. It is not something that is acceptable to musicians. The exception is if a child has successfully adapted to any frequency transposition or shifting in their own hearing aid for speech in noise. Then it is reasonable to have that same setting for the music as well. To my knowledge, that is the only exception.
You can also transpose the instrument. At the Musician Clinics of Canada, we would never recommend that a patient stop playing a musical instrument. I have never, in 35 years, said that to a hard-of-hearing musician. I have, however, suggested for them to change to a more bass instrument to access a region of their cochlea that is healthier. I have suggested a violin player switch to a viola. That is physically a little larger, a little lower frequency, and it is usually in a more audible and comfortable region. That is another strategy that you can use.
5. OSPL90 and Gain
Assuming that the use of compression is primarily because of the cochlear damage and has nothing to do with the input nature of the sound, whether it is music or speech, given similar compression characteristics between speech and music, the OSPL90 output should be 6 dB lower for a “music program”. Why? The crest factor for music is 6 dB higher. It is not the root mean square (RMS) that we want to prevent exceeding our loudness discomfort levels; it is the peak. If the peaks are 6 dB more intense for music than the speech (a crest factor of 18 dB versus 12 dB), we want to ensure that those peaks are not exceeding the loudness discomfort level. We have to reduce the overall OSPL90, by 6 dB; the difference between 12 dB and 18 dB. If you first set your speech-in-quiet program, your music program should be identical, except for disabling some of the advanced features and setting the OSPL90 6 dB lower. You should also set your overall gain 6 dB lower than the speech-in-quiet program. Again, music tends to be played and listened to at a higher sound level.
Conclusion
As I mentioned, in the Articles section at www.musiciansclinics.com, you can find information about music and hearing aids, hearing loss prevention with musicians, languages and hearing aids, acoustics, and some other things I have done over the years. Also, if you go to the FAQ section, you will find 30 frequently asked questions that are written on a 10th grade garage-band level. They are humorous, and it is a nice summary of the field, written for the younger population.
Finally, there is a weekly blog that is published Wednesday afternoons at www.hearinghealthmatters.org. You can hit the RSS feed and have it sent to your e‑mail. There are about eight or nine bloggers that write every week. Some are on economic issues by Holly Hosford-Dunn; international issues by Robert Traynor; central auditory issues by Frank Musiek. We have other people writing about vestibular and pediatric issues, and I write something called Hear the Music, which includes anything to do with music.
Questions and Answers
When I program the hearing aid for music, I usually make the settings more linear. Your and other’s research indicates compression characteristics should remain the same for live speech. What about gain, since inputs are louder, and what about the output?
Those are very good questions. Even with speech in quiet, I do not prefer compression overload. My compression ratio never exceeds 1.7:1. It is almost linear, and that is with an occluded situation. Most of my fittings are unoccluded, and when you look at the sound entering directly through the vent and calculate the true compression ratio with this vented situation, 1.7:1 may function more like 1.3 or 1.2:1. Francis Kuk is a brilliant researcher and has published on this in a Trends in Amplification issue. Indeed, my compression is quite linear.
One of the programming tricks I use when manually building a music program dates back to the 1970s from audio engineering. Stereo receivers from that era have a loudness button, which adds both low- and high-frequency emphasis for soft sounds to approximately compensate for human hearing equal-loudness contours. I accomplished this by adding gain for 65 dB SPL inputs for the lowest couple of frequencies in the highest frequency channel and adding more gain for 50 dB inputs. Any comments?
That is a good point. I usually do not play with this because the people that listen to music also have to listen to speech a moment later, if they are working musicians. They have to hear cues. I loathe increasing the lower frequencies, and in many cases, it is not occluding, so there will be no change in lower frequencies. More often than not, I am limited in the high‑end frequencies. I love to give them more high-frequency boost if I can, but I often run out of head room there.
Will you please repeat the slide about the third difference between music and speech? It is missing the PDF file.
The third difference between music and speech is the perception requirement. This harkens back to the fact that strings require almost the same audibility for the lower-frequency fundamental as the higher-frequency harmonic structure. Harmonics are always higher frequency, and some instruments, like strings, must hear those higher-frequency harmonics. The intensity of the higher-frequency harmonics relative to lower-frequency fundamental is crucial in the quality of the sound. That is a perceptive issue. As far as woodwinds are concerned, it is not a big issue at all.
The Association of Adult Musicians with Hearing Loss has a listserv that we can all view. Some of the comments from musicians are wonderful. There is a sub‑blog of audiologists within AAMHL, and you can share a lot of information there. Also they have a book out (Miller, C., Editor, 2011), to which Wendy referred at the very beginning. Contact the website, AAMHL.org. The final chapter is the most important part, as it covers the strategies that are used by musicians so they can hear better.
Could you review what happens to low‑frequency sound coming to standard hearing aid microphones and the distortion that low‑frequency causes under 200 Hz?
There is no inherent problem with microphones down to 200 Hz. There is typically no distortion associated with them, as long as you do not exceed the headroom of the system. But the question remains, “Do we need low‑frequency gain at all?” Middle C on a piano is 250-260 Hz. We do not even pay attention to the whole left side of the piano keyboard. My argument is that many of these fundamental sounds do enter unamplified in a non-occluded hearing aid. I know that there are some people arguing that we should have more low frequencies, but I disagree with them. I think the bandwidth that we use for speech in noise should be similar to the bandwidth we use for music. In a non-occluded situation, the person is receiving a lot of these long-wavelength, low‑frequency sounds unamplified. I think that is still the best way.
Will hearing aid companies ever allow more user access to the programming? Some of us musicians know what we want to hear and what to tweak.
One of my blogs spoke to that concern. I love to give control of my programmer to the musician. The one thing I do not give control over is the OSPL90, the maximum output of the hearing aid. I would set that. The worst thing the musician will do is come back with his tail between his legs in a couple days saying, “Can you please reprogram this?” Many musicians have wonderful experience with equalizers and compression. If you look at a composer, their screen has attack time, release time, and compression ratio, just like ours. Feel free to give them control over the programming, except for OSPL90. The worst case scenario is they come back and ask you to fix it.
Why did you prefer the K‑AMP?
The K-AMP had no A/D converter to distort sound. It was an analog hearing aid, and it also had a peak input limiting level of 115 dB. When Mead Killion built it in the late 1980s, he wanted a hearing aid that would not distort while he put his head into a grand piano and played loudly. It was a distortion-free hearing aid. The only reason it is not available is because of marketing. People prefer digital to non‑digital. Having said that, there are things like feedback management systems that are more common and useful with digital systems; it was more difficult to do with analog systems. If the K‑AMP ever came back again, and it has in the form of the BEAN, go for it. It is probably the best sounding hearing aid you will ever see, even with many modern digital hearing aids. The K-AMP is still commercially available from www.GeneralHearing.com in the United States.
If you have dead zones in the higher frequencies in excess of 100 dB, does it make sense to turn those frequencies off or all the way down in the hearing aid?
That is a good question. Usually I use a notch filter to see if that works. If not, I will roll off the high‑end frequencies with a low-pass filter. It usually is a high-frequency phenomena. Clinically, I do not do the TENS test, which is Brian Moore’s test for dead regions. I have a piano in my office, but you can buy a $20 Cassio piano and use that in your office. Have the musician play every note, white, black, white, black, and ask them to if two adjacent notes sound the same. If they do, then that is a dead region. Stay away from the region where 2 adjacent notes sound the same, whether you use notch filtering or high cut.
References
Chasin, M. (2014). A hearing aid solution for music. Hearing Review, January, 28-31.
Chasin, M., & Russo, F. (2004). Hearing aids and music. Trends in Amplification, 8(2), 35-47.
Cornelisse, L. E., Gagnńe, J. P., & Seewald, R. C. (1991). Ear level recordings of the long-term average spectrum of speech. Ear and Hearing, 12(1), 47-54.
Cox, R. M., & Moore, J. N. (1988). Composite speech spectrum for hearing aid gain prescriptions. Journal of Speech and Hearing Research, 31, 102-107.
Dunn, H.K., & White, S. D. (1940). Statistical measurements on conversational speech. Journal of the Acoustical Society of America, 11(1), 278-288.
Davies-Venn, E., Souza, P., & Fabry, D. (2007). Speech and music quality ratings for linear and nonlinear hearing aid circuitry. Journal of the American Academy of Audiology, 18(8), 688-699.
Hockley, N. S., Bahlmann, F., & Chasin, M. (2010). Programming hearing instruments to make live music more enjoyable. The Hearing Journal, 63(9), 30, 32-33, 36, 38.
Killion, M. C., & Fikret-Pasa, S. (1993). The 3 types of sensorineural hearing loss: Loudness and Intelligibility considerations. The Hearing Journal, 46(11), 1-4.
Miller, C. (2011). Making music with a hearing loss: Strategies and stories. CreateSpace Independent Publishing.
Moore, B. C. J. (2004). Dead regions in the cochlea: Conceptual foundations, diagnosis and clinical applications. Ear and Hearing, 25, 98-116.
Cite this content as:
Chasin, M. (2014, September). Programming hearing aids for listening and playing music, presented in partnership with the Association of Adult Musicians with Hearing Loss (AAMHL). AudiologyOnline, Article 12915 Retrieved from: https://www.audiologyonline.com

