
Learning Outcomes
After this course, participants will be able to:
- State two ways the environmental classification is used in hearing aids.
- State one reason why the accuracy of environmental classification in hearing aids is important.
- Name one type of background noise sound that might cause an environmental classifier to classify the environment differently than a listener would.
Introduction
All modern hearing aids with any kind of automatic functionality use analysis of the acoustic environment. The most basic is the compression system, which uses level detectors to determine how much gain should be applied to the input signal according to the amplification scheme. However, when speaking of environmental classification, what we usually mean is the system by which the hearing aid decides what sort of listening situation it is in. This information is used by the hearing aid for two purposes. One purpose is to provide the hearing care professional with a picture of the types of listening situations the user is exposed to. It does this by counting the time spent in different, pre-defined environments, saving this information, and uploading it to the fitting software to be displayed when the hearing aid is connected. Along with information about hearing aid usage, this makes up the datalogging feature of modern hearing aids. The other purpose of environmental classification is to control different features of the hearing aid, such as directional microphones and noise reduction, to provide optimum benefit in any given listening situation without necessitating manual changes by the user.
On the surface, this would seem rather simple. However, consider that the number and characteristics of acoustic environments in the real world are infinite. Hearing aid manufacturers must break these down into a small number of manageable, idealized acoustic environments. These idealized environments are not standardized. Each manufacturer defines the categories into which an environmental classifier sorts the input. However, all systems will at least try to identify environments that are quiet, ones that contain speech, and ones that contain noise. Some may also attempt to further characterize types of noise or to identify music. Besides the definition of environments, manufacturers also develop their own system for analysis. In other words, the method by which any one manufacturer identifies “speech” or any other environmental characteristic may be unique, and is in any case proprietary. Algorithms, or methods, for the identification of different types of sounds have been described in the literature, and reported to be accurate for identifying different types of noise classes, speech and music (Kates, 1995; Büchler, Allegro, Launer, & Dillier, 2005).
Because hearing aid features are often steered by the output of environmental classifiers, it is of interest to explore the accuracy of classification in different hearing aids. This article describes a study that tested how six hearing aids classified five prototype environments.
Methods
Since there are no standardized environments, we started by identifying sound files that we thought listeners would show a high level of agreement in labelling. The idea was that subjective naming of a number of prototypical listening situations/sounds should be the gold standard to which we could compare the output of the classifiers when exposed to these sounds. If a hearing aid algorithm is designed to adjust a particular parameter when the user is wearing the hearing aid in “speech-in-noise”, then it is important that the user and the hearing aid agree on what constitutes “speech-in-noise”.
Once a library of sound files representing various prototypical environments was determined, we looped those sound files and exposed hearing aids to them in a testbox for periods up to 22 hours, and subsequently read out the datalogging from the hearing aids. This allowed us to validate whether the different hearing aids classified the sounds consistently with the subjective classification. The agreement between the hearing aid classification and the subjective classification was interpreted as the accuracy.
Subjective Classification
As mentioned, all hearing aid classification systems have in common identification of environments containing “noise”, “speech”, “speech-in-noise” and “quiet”. Several also identify “music”. However, the technical definitions of these environments and methods for analyzing the acoustic input are proprietary. Since these terms are common, they were used for subjective classification in order to see how actual listeners would apply them. While some systems further break down environments by type of noise or sound level of the environment, this is not universal and therefore not included in the study.
The subjective evaluation was done in two phases. First, listeners were presented with a sound sample via the Otometrics Aurical REM speaker and asked to describe the listening environment in their own words, using a maximum of 3 or 4 words. They were instructed to use generic terms; for example, if they were presented with a Frank Sinatra song, they were instructed to use words such as “music” or “singing” rather than “Frank Sinatra singing”. Next, they heard the same sound samples, and were asked to describe the listening environment using up to 3 of the following words in any combination: quiet, speech, noise, music. The listeners were 9 normal-hearing adults who were naïve regarding hearing aid classifiers, and they were told that the purpose of the study was to investigate how listeners label different sounds. The evaluation was carried out in an office with an ambient noise level of 60 dB SPL (c-weighted). There was periodic sound from a computer fan and the HVAC system in the office.
The 10 sound files that were evaluated are part of the sound library of the Otometrics Otosuite software. The names of the sound files and the presentation levels were as listed below. The sound files labeled “Scene” consist of a conversation between a male and female, and take place in different noise backgrounds as described. “Voices only” is the same two speakers having a conversation with no background noise. In addition, listeners were asked to listen with no sound played from the Aurical. This was meant to represent a quiet environment.
Scene - café 75 dB
Scene - party 75 dB
Scene - station 75 dB
Scene - supermarket 75 dB
Hand mixer: 75 dB
Babble: 75 dB
Noise white: 75 dB
Voices only: 65 dB
Music – pop 65 dB
Music – classical 65 dB
Results
Open-ended descriptions
The words used in the listeners’ own descriptions of each sound file are presented in Table 1.
Sound file | Words used by at least 8 of 9 listeners (similar words are grouped) | Other words used (number of listeners) |
Scene – café |
|
|
Scene – party |
|
|
Scene - station |
|
|
Scene – supermarket |
|
|
Hand mixer |
|
|
Babble |
|
|
Noise white |
|
|
Voices only |
|
|
Music - pop |
|
|
Music - classical |
|
|
No sound played |
|
|
Table 1. Listeners’ open-ended descriptions of the sound files.
In all cases, the listeners were in agreement in describing the basic components of each environment, such as whether there was some kind of speech or talking, or whether they thought the sound was a noise. However, many listeners further qualified the environment with specific terms that described the place (e.g. “restaurant”, “supermarket”), the quality (e.g. “harsh”, “soft”, “staccato”, “annoying”) or identified the sound source (e.g. “mixer”, “guitar”, “small motor”).
Closed-set descriptions
Table 2 presents how listeners applied the 4 words they were asked to select from to describe each sample. The number in each cell is the number of listeners who used the given word to describe the sound.
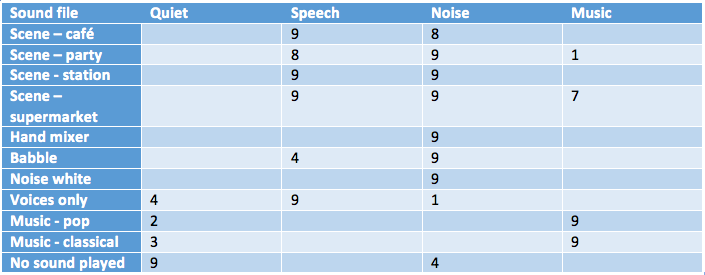
Table 2. Listeners’ descriptions of the sound files using up to 3 of 4 closed-set terms.
There was a very high level of agreement among listeners when using the specified terms. Because they could use up to 3 words to describe each sound, there were instances where the listeners added words to provide a more detailed description of the environment. For example, in the “Scene – supermarket”, there is music playing in the background. Although all 9 listeners described this scene using the words “speech” and “noise”, 7 of them also chose to include “music” in describing this scene. Likewise, when no sound was played, all listeners used the word “quiet”, but since there was soft ambient noise in the room, 4 chose to include “noise” in their descriptions as well.
In summary, regardless of whether the listeners described the sound samples in their own words or whether they selected from a closed set of descriptors, there was a high level of agreement on the “generic” nature of each sound. Thus it was concluded that the selected sounds could be used to represent prototypes of 5 listening environments (Table 3). Several sound files that were labelled as the same type of environment were used in the subsequent evaluation of the hearing aids in order to represent different types of sounds falling into the same category, and to minimize bias that might favor one classifier over another.
Sound files | Prototype environment |
Scene – café, Scene – party, Scene – station, Scene – supermarket
| Speech-in-noise |
Handmixer, Babble, Noise white | Noise |
Voices only | Speech |
Music – pop, Music – classical | Music |
No sound | Quiet |
Table 3. Sound files that were used to represent 5 prototype environments.
Hearing Aid Classification
ReSound LiNX 3D hearing aids and premium hearing aids from 5 other manufacturers that showed environmental classification in their datalogging were placed in an Otometrics AURICAL test box and exposed to all sound files for periods of 2 to 22 hours. The shorter exposure times were for sound files of a static nature (e.g. no sound input, white noise). After the exposure period, the hearing aids were connected in the respective fitting software module, and the datalogging was read from the hearing aid. For Hearing Aid B, the output of environmental classification is not shown directly in the software. Rather, the time spent in automatic programs is shown. In this case, the automatic programs were used as a proxy for environmental classification. Because the hearing aid switching algorithm for this hearing aid may be triggered by direction of speech as well as presence of speech, it is possible that our methodology could misrepresent the environmental classifier accuracy.
Results
When the datalogging was read from each hearing aid, it was found that all systems identified quiet, speech, and white noise with a very high degree of accuracy. At least 96% of the hours of exposure in these environments were classified correctly across manufacturers. Some differences were noted for the speech babble and hand mixer noises, as shown in Figure 1. One system identified 60% of the hours exposed to the hand mixer noise as “speech-in-noise”, while another classified 96% of the hours exposed to speech babble as music.
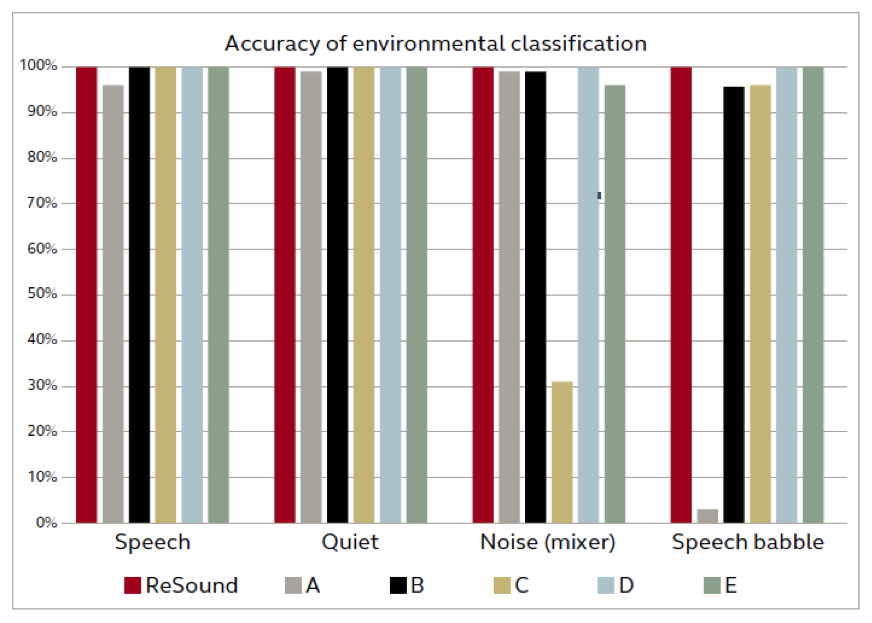
Figure 1. The environmental classification systems tested could accurately identify quiet and speech in quiet. Most could also identify different noises and speech babble as well, although some serious identification were observed.
The acoustic environments that present the greatest challenges for hearing aid users are those with background noise. Algorithms that control directionality aim to provide benefit particularly in situations where there is speech in a noisy environment. Real world environments can consist of all kinds of different background noise, and often speech is both the sound of interest as well as the competing noise. In each case, the “speech” was the same male and female voices having a conversation. Figure 2 presents the results combined for all four environments. The ReSound system was 98% accurate in identifying speech-in-noise, which was the highest degree of accuracy across the six systems tested. One other system also demonstrated high accuracy, with 91% of the hours exposed classified correctly. The other systems were less accurate, with 60% or fewer of the hours exposed classified correctly.
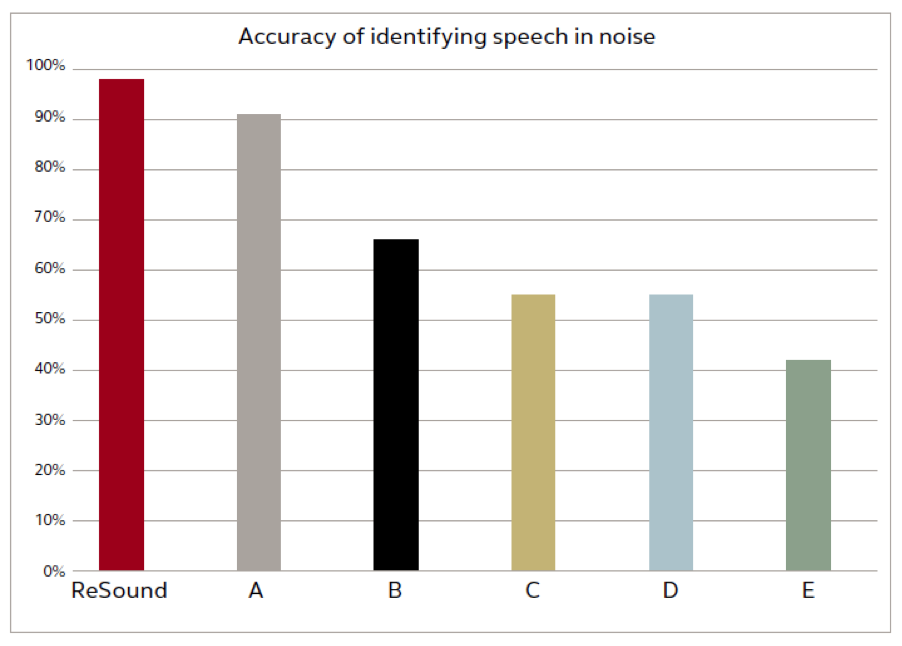
Figure 2. ReSound was 98% accurate in identifying speech-in-noise in varying noise backgrounds. No other system was as accurate, and noise backgrounds with music or highly modulated noises posed the greatest difficulty for these systems. Accurate identification of speech in noise and other environments is important in adjusting environmentally dependent parameters accurately.
An interesting finding was that the systems differed significantly in terms of which noise background caused them to be inaccurate in the classification. All were at least 75% accurate in identifying speech-in-noise for the “party” and “train station” background noise, while the “café” and “supermarket” background noise posed greater difficulties. The competing noise for both “café” and “party” is people talking in the background. However, “café” also includes the clinking of cups and saucers as would be typical in this environment. The classification mistakes that were made in this environment were to assign many of the hours to the “speech” category. It may be that the systems were fooled by the transient and modulating sounds caused by the cups and saucers, wrongly identifying this as speech with no competing noise. This suggests that the speech detectors in these systems may not be sophisticated enough to reliably distinguish between speech and other modulating sounds.
The results from the “supermarket” background were quite inaccurate for the four systems that have a music category in their classification system. This background includes some soft music along with other typical supermarket sounds. Of the four systems with music classification, two assigned 100% of the hours exposed to the music category, one 84% of the hours, and one 37%. Taken together with the results of the classification when these hearing aids were exposed to music (Figure 3), this calls into question the relevance of hearing aids identifying music at all. For example, while system E accurately identified 100% of the hours of both classical and pop music, it also identified 100% of the speech in the supermarket background noise environment as music. This is a thought-provoking result that illustrates how hearing aid intelligence cannot accurately predict the user’s intent. The presence of music in an environment does not mean that the user wants to listen specifically to it, and may in fact consider the music to be competing noise depending on the situation.
As mentioned previously, it was not possible to read the output of the environmental classification system directly from Hearing Aid B, and we therefore interpreted the automatic program switching data as a reflection of the environmental classification. We considered that the results for speech-in-noise classification might be affected. However, the inaccuracy of the classification for Hearing Aid B was attributable mainly to the classification of the scene in the supermarket background as music.
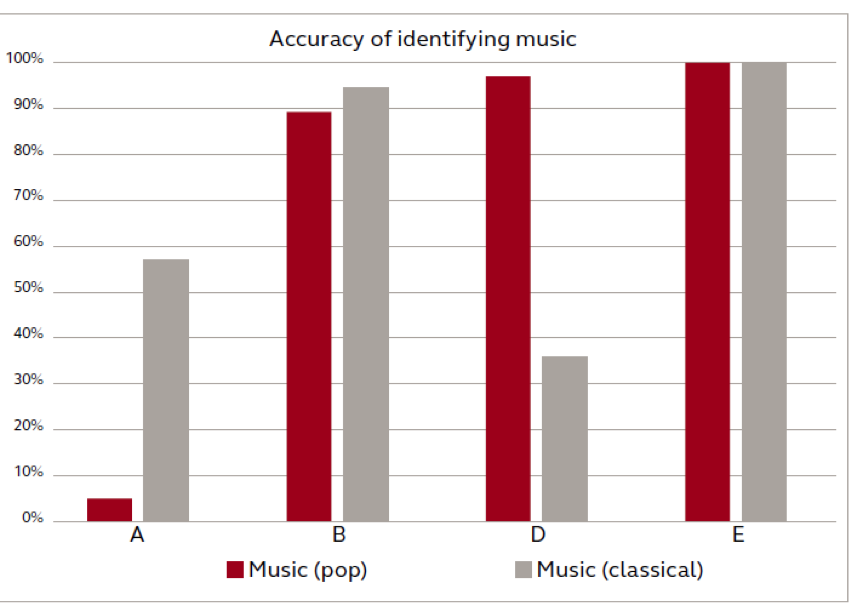
Figure 3. Four of the systems tested had music identification, presumably to automatically adjust settings for music listening. Systems B and E showed the best results in identifying two different genres of music. System E, while correctly identifying both classical and pop music, also classified 100% of speech in the supermarket background as music. It would probably not be consistent with listener intent to change to music listening settings in a supermarket environment.
Conclusion
Listeners showed a high level of agreement in their subjective classification of the sound files used in this investigation, and the sound files were therefore judged to provide a valid reference for assessing the accuracy of hearing aid classifiers. All 6 of the premium hearing aids tested accurately classified “quiet” and “speech”. Four of the 6 were also highly accurate in classifying different types of noises. Of the 4 hearing aids with music classifiers, 2 were highly accurate in classifying examples of pop and classical music. Unsurprisingly, the speech-in-noise environments proved to be the most challenging to classify accurately. The systems which were least accurate either confused the environment with modulating background noise with a speech-only environment, or prioritized the music in the environment that included music in the background noise. The environmental classifier in the ReSound LiNX 3D was the most accurate both for the speech-in-noise backgrounds and as a whole.
References
Büchler, M., Allegro, S., Launer, S., & Dillier, N. (2005). Sound classification in hearing aids inspired by auditory scene analysis. EURASIP J Appl Signal Processing, 18, 2991-3002.
Kates, J. (1995). Classification of background noises for hearing aid applications. J Acoust Soc Am, 97(1), 461-470.
Citation
Groth, J., & Cui, T. (2017, April). How accurate are environmental classifiers in hearing aids? AudiologyOnline, Article 19796. Retrieved from www.audiologyonline.com


