
Editor's note: This text course is an edited transcript of an Oticon webinar on AudiologyOnline.
Learning Outcomes
- After this course learners will be able to describe the basic principles underlying spectral subtraction noise reduction approaches.
- After this course learners will be able to describe the acoustic conditions required for directionality to have an impact on performance.
- After this course learners will be able to explain the concept of completion approaches to managing speech understanding in noise.
Introduction and Overview
At Oticon, we believe that being able to understand speech in complex listening environments is critical for people with hearing loss. Despite recent advances in technology, understanding speech in environments where there are other people talking continues to be one of the most difficult challenges with hearing loss. This is not a fault of technology advances, but traces back to the fundamental issue of sensorineural hearing loss. Hearing is a complex, highly intricate, highly-calibrated perceptual system in the body. Once hearing loss is present, in the vast majority of cases, it’s permanent. It creates distortion in the signal as it passes through the peripheral auditory system. One of the ways this distortional aspect of hearing loss manifests, is in trying to understand a complex signal like speech in a background of other complex signals.
We’ve come a long way as an industry to create better and better solutions for people with hearing loss, but there is still a long way to go. During this course, I want to take a step back so we can get a bigger view, and look at how this problem is currently being addressed in technology. In order to understand new approaches that we will see in the future, it’s important to understand the principles that underlie current approaches. What are some of the benefits and drawbacks of the current approaches?
The brain is our best ally when it comes to speech understanding in noise. The brain is a very effective signal processor. It can take in a lot amount of information and make sense of it. When the brain is receiving good information, as in the presence of normal hearing, it works well. In the presence of hearing loss, the incoming information is distorted.
It’s hard to eliminate noise, especially when the source of the noise is other people talking. The noise reduction approaches available today have some disadvantages. I’ll review how directionality and noise reduction are typically active in hearing aids. Finally, I’ll give you a glimpse into current and future approaches.
Soundscapes
Soundscape is a very broad concept in the area of environmental engineering and acoustics. The basic idea is that every location -- whether a public or a private place -- has a certain sound that we would expect. There are sources of sounds that we anticipate in those environments, that help define the environment. Changing the environment (e.g., putting up a building, creating a new road, widening a road, changing traffic patterns) will change the sound pattern of that environment. As human beings, we expect there to be sound in certain environments, and that sound will take on certain characteristics. There’s a lot of interest in understanding how the activity of humans will change soundscapes, and in turn, how humans will be affected.
Axelsson, Nilsson, & Berglund (2010) proposed a model to serve as a framework to study soundscapes. One of the observations about soundscapes is that they can have multiple dimensions. In other words, psychologically, they can have different qualities. One of the dimensions in the area of soundscape perception is the idea of sounds being either pleasant or unpleasant. Another dimension is whether or not the soundscape itself is eventful or uneventful. In other words, is it a busy place? Is it a calm place? Do you perceive the sounds as pleasant or unpleasant? Most sounds in a person’s environment can be accounted for in these two dimensions.
For example, a place that is full of pleasant sounds and is eventful, feels exciting. In contrast, an eventful place that is full of unpleasant sounds feels chaotic. Depending on the sounds in the environment, different places can be perceived with different psychological realities.
If we look at human sounds, technology sounds and nature sounds we find that listeners almost always interpret human sounds, which are mostly speech, as pleasant and eventful.
Humans enjoy contact with other humans, even if it’s not direct contact. If we sit at a Starbucks and have a cup of coffee, sometimes it’s pleasant just to know that there are other people around. Of course in some instances, we might prefer to be by ourselves, but there is a certain pleasantness in knowing we are not alone. For those with normal hearing, human sounds are usually perceived as being a pleasant part of soundscapes.
In contrast, a study from Sweden in 2014 (Skagerstrand, Stenfelt, Arlinger and Wikstrom, 2014) asked hearing aid users to rate the top five sounds that bother them. They reported that the most bothersome sounds are those produced by people, especially speech sounds. It is a psychologically interesting juxtaposition that normal hearing people consider speech sounds to be pleasant, whereas hearing impaired individuals are bothered the most by speech sounds. At Oticon, we strive to bridge the gap between these disparities, so that ultimately, hearing aid users perceive human sounds as pleasant.
How Does the Brain Manage Complex Environments?
Imagine this situation (Figure 1): You’re trying to listen to one speaker (indicated by the dark blue waveform), and you are in the presence of another speaker (the light green waveform). Maybe you are talking to someone in front of you, and there is someone off to the back or side of you who is also talking. How does the brain manage this complex environment?
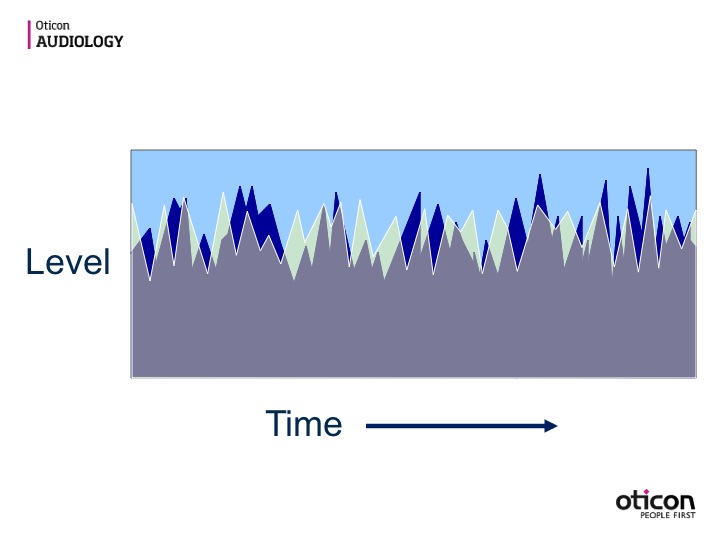
Figure 1. Listening to one talker (dark blue waveform) in the presence of another talker (light green waveform).
Normal hearing individuals can do a good job of monitoring and tracking one voice in the presence of another voice. They can switch their attention. If you have normal hearing and you no longer wish to listen to the speaker in front of you, and want to monitor a voice to the side or behind you, you can do that without too much trouble. The brain is good at taking in a complex waveform and sorting through it.
In the situation that I just described, the ear is getting the same stimulation. The cognitive system is still receiving two complex waveforms mixed together. The difference is, as information is coded and sent up to the brain, the brain can then pull the signal apart and identify two different sources. Then, the brain can decide which one of those speech sources it wants to pay attention to, and which one it wants to disregard.
Part of that skill set involves the brain picking up on certain cues that differentiate one voice from the other. The brain will use whatever cues it can find. If you’re listening to one talker in the presence of another talker, there are a lot of different cues that you can use at any moment in time to separate out those two voices:
- Fundamental Frequency
- Harmonic Structure
- Supra-segmentals
- Visual Cues
- Linguistics
- Loudness
- Location
- Timbre
- Rate
The sound of a person’s voice is made up of many different elements, and the brain is effective at separating the voices and tracking them.
The Brain is Opportunistic
The brain is what I refer to as opportunistic. In other words, the cognitive system is good at finding the cues at that moment in time that separate out one voice from the other, and using those cues to track, over time, one voice versus the other. It doesn’t have to do a lot of work to be able to do that.
When you have normal hearing, you don’t have to do anything special to listen to one voice in the presence of one or more talkers. If the brain receives good information, the brain will sort through what’s coming in, and decide what it wants to listen to and what it doesn’t want to listen to. Of course, even normal hearing individuals eventually run into problems if the signal-to-noise ratio is very poor. As long as the signal is of good quality, the brain can handle a lot of it and still sort through it.
Think about what happens if you’re in a public place that has a poor public address system. For example, imagine you are at an airport or a train station, and you’re trying to hear an announcement with a lot of noise and activity going on around you. If the speaker system is of poor quality, there is a lot of reverberation, and there is a poor bandwidth, you may know there is an announcement happening, but you will not be able to decipher what is being said.
In that case, the problem has more to do with the poor quality of the signal coming out of the PA system than the environmental noise. The brain can’t work with the poor signal. Even if most of the other noise went away, you would still have trouble deciphering the announcement. In a case like that, because your brain is receiving limited and inferior information it has a lot of trouble interpreting the message.
Loss of Ability to Organize Sound
We often define hearing loss as the inability to hear certain sounds, and that is true to an extent. We also know that people with sensorineural hearing loss struggle in noisy environments. Why is this so? Think about in this way: the patient is suffering from the loss of ability to organize sound. In other words, in a moderately noisy environment, a person with sensorineural hearing loss may describe the situation as being overwhelmed by too much sound. They are not hearing more sound than the normal-hearing individual. However, because the sound is poorly defined within the cognitive system due to the peripheral hearing loss, the brain can’t organize and make sense of that sound. It can’t separate out the different sound sources and decide it’s going to pay attention to one sound source while ignoring the other sound sources. What can we do in these situations that help the patient better organize sound? What kind of technological solutions can we use?
Current Approaches
We can start by examining how is the problem currently addressed in hearing aids. The two main technologies used in hearing aids to address noise are directionality and noise reduction. Let’s look at the major principles that define how these systems work. There is some variation in approaches between hearing aid companies, but there are some general principles that are common to all approaches.
Subtractive vs. Completion
The approaches used in hearing aids these days can be grouped into two categories: subtractive approaches and completion approaches. Subtractive approaches involve trying to identify undesirable sounds, and subtracting them out of the signal that is reaching the hearing aid user’s brain. In order to understand a primary speaker in the presence of competitive speech signals, the idea is to subtract out the “bad stuff” and leave the “good stuff.”
Completion approaches handle the problem in a different way. Completion approaches work under the idea that the brain will use as much good information as it can get. Using technology, we give the hearing aid user extra good information, so that the brain can put together the signal. The hope is that the extra good information will be enough for the brain to complete the signal.
Subtractive Approaches
In the hearing aid industry, the main objective in deploying a subtractive approach is to define what you want to subtract, and then figure out a way to eliminate that from the signal. The problem is, it is often difficult to identify and take away what needs to be removed from the signal, without also taking away “good stuff.” For example, noise reduction headphones are good at canceling out undesirable sounds, allowing the user to listen only to what they want to hear. When you’re wearing a set of noise reduction headphones, there’s a microphone on the ear cup, facing away from the wearer. Presumably, what you want to listen to is coming in on the line that’s feeding the headphones. The noise (i.e., everything happening outside the ear cups) is isolated. One of the basic reasons why noise suppression headphones work so well is that the noise signal is independent of the desired signal.
Because the system can independently identify the noise and the desired signal, it can subtract out the noise without touching the desired signal. Hearing aids do not have the opportunity to do this very well, because by the time the signal gets to the hearing aids, both the noise and the desired signal are already mixed together. The same principles used in a subtractive approach like a noise reduction headset can’t be used in hearing aids, because hearing aids Have not had that independent look at the noise versus the speech.
Spectral Subtraction
In signal processing, there is a general group of noise reduction approaches that use spectral subtraction. Spectral subtraction simply means that you eliminate noise by picking out one or more frequency regions, and filtering those frequency regions out of the signal.
Spectral subtraction works really well if the noise that you want to eliminate occurs in one frequency region, and the desired signal occurs in a different frequency region. However, as we know, the speech signal is a very broad band signal. The human voice and its resulting speech signal cover a very broad spectrum, well beyond the bandwidth of hearing aids. Since speech information can fall anywhere across that spectrum, when you subtract noise of the spectrum, by definition you are going to take some speech information out of the signal as well.
With hearing aids, it is a balance of cutting out enough of a part of the spectrum to get rid of the noise source, without hurting the speech signal too much. The brain is effective in putting together a speech signal that has a hole in the spectrum. In other words, if some of the spectrum is taken out, the listener could still easily understand speech. The problem with spectral subtraction is first defining what that noise is, and then making sure not to take out too broad of a range of the speech signal.
To review, hearing aids today typically have 2 to 64 channels, with most hearing aids having 4 to 12 channels. Noise reduction typically works by analyzing each channel to ascertain whether that channel is dominated by speech or by noise. If someone is talking, there is going to be some speech information present in that channel. If the background noise registers at a significantly higher level in that particular channel, and it is defined as predominantly a noise signal in that frequency region, then the noise reduction algorithm will reduce the level in that frequency region. It’s going to subtract out that part of the spectrum, to some degree, so that, overall, the noise is not so perceptually dominant. Some speech information will be removed, with the idea that that speech information wasn’t useful to the patient in that frequency region, because it was dominated by the noise source. The question is, can we remove enough of those frequency regions to make the noise not seem so apparent to the patient, but still leave enough of the speech signal available to the patient that they can make sense of the signal? Those are the general principles that define noise reduction in the way it’s currently deployed in hearing aids.
Figure 2 is a graphic image of a three-part chord. There are three very discrete places where the sound is being produced. If I’m trying to listen to speech in the presence of this chord of music, particularly if the music is loud, it could be very challenging.
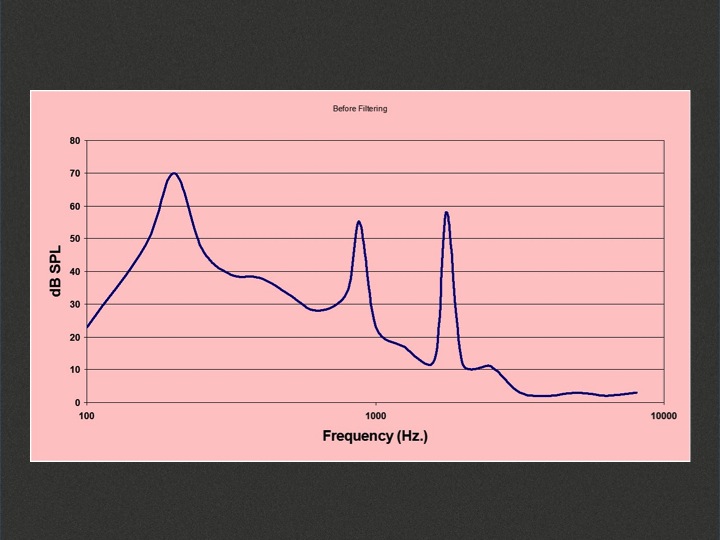
Figure 2. Three-part chord of music with spectral peaks.
If we use a filter that subtracts those peaks out of the music (Figure 3), it will be much easier to understand speech. Some of the speech signal has been cut out along with those peaks, but since the peaks are narrow regions of the signal, the brain has the ability to fill in the gaps and to put the signal back together.
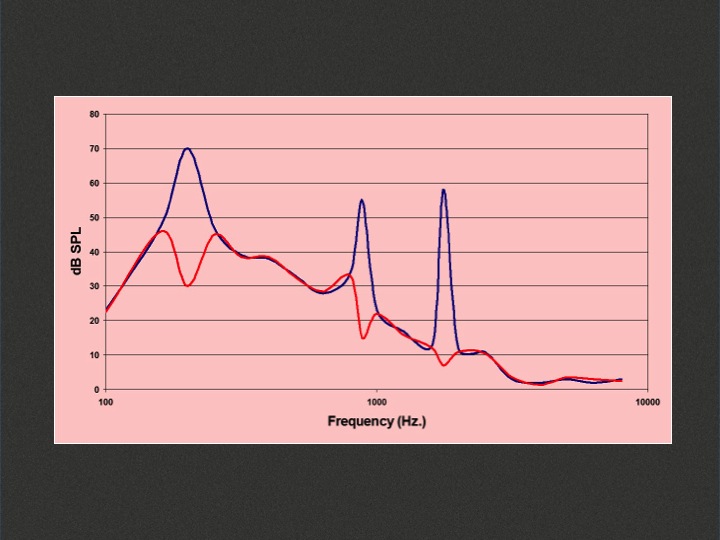
Figure 3. The application of a filter applied to the discrete frequency regions where the spectral peaks occur.
In such a case, a spectral subtraction type of approach is effective. However, our patients don’t typically complain about hearing speech in the presence of noise that is in discrete frequency regions. When people report having trouble understanding speech, it’s usually because they are listening to speech in the presence of other people talking. When other people are talking it creates a broadband competition, and there is not a very discrete frequency region that can be isolated and filtered out.
How does the hearing aid know that the dominant signal in a particular channel is speech versus noise? That is achieved via modulation analysis (Figure 4). Modulation analysis looks at the way the waveform changes over time. It analyzes the pattern and determines whether that pattern of bursts of energy and drops in energy resembles the behavior of a speech signal or not.
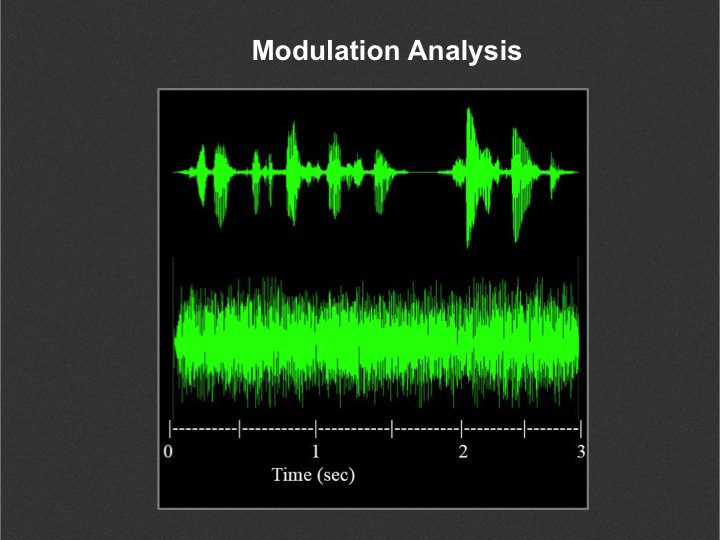
Figure 4. Modulation analysis in speech (top) and non-speech (bottom) signals.
The speech signal is a series of phonemes occurring over time, each with a typical duration and level. Vowels tend to be at a higher level and have a longer duration than consonant sounds. If you put phonemes together in a string, you are going to see bursts of energy that register at different levels and at different durations over time. For conversational speech, approximately three to seven times per second, you will see a burst of energy for a vowel sound, followed by a drop in energy for consonants (particular unvoiced, high frequency consonants), or for pauses between words or sentences. The result is a typical fluctuating pattern represented in the top signal in Figure 4. That is the typical modulation behavior of speech.
Non-speech signals change in level over time, but not typically in the same pattern as the speech signal. I don’t know of any signal defined as “noise” that changes in level over time the way the speech signal does. The bottom signal in Figure 4 is a cafeteria-type background noise -- clearly a non-speech noise. Notice that although there are fluctuations in level over time, it’s not timed the same way as the speech signal. There are not as many peaks, and there is not as much of a depth of the drop between the peaks and the valleys.
We usually talk about the speech signal as having a 30 dB peak-to-valley ratio. Those big peaks that are associated with the stressed vowels happen 30 dB above some of the softer, unvoiced consonants. Modulation analysis looks at how often the peaks and valleys occur, and also how deep the valleys are as compared to the peaks. This can be done mathematically, and is easily analyzed by a computer.
Within a particular channel, hearing aids will use modulation analysis to decide whether or not that channel is dominated by a speech or a non-speech signal. If the noise signal is at a high level and masks out any evidence of the speech signal, then that channel would be identified as dominated by noise. If you see evidence of peak and peak-to-valley behavior consistent with a speech signal, then the system would identify that as channel as likely containing a speech signal.
It becomes more challenging when noise fills in valleys of a speech signal. In Figure 5, you see the modulation pattern of a speech signal (top), and a non-speech noise signal (bottom).
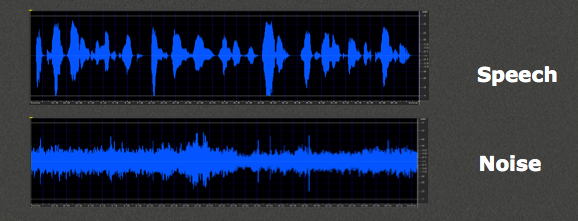
Figure 5. Speech signal (top) and non-speech noise signal (bottom).
I mixed these two signals together at two different signal-to-noise ratios (Figure 6), and the question is, would these be considered speech or noise? In the left panel in Figure 6, I mixed the signals together at a little bit better signal-to-noise ratio. You still see pretty good evidence of the peak-and-valley behavior of a speech signal, although the peak to valleys do not have a full 30 dB drop because the noise has somewhat filled in the area between the peaks and valleys.
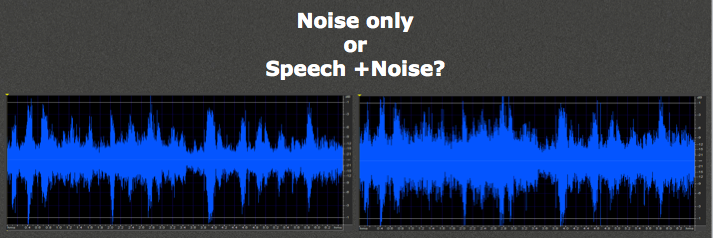
Figure 6. Speech and noise signals mixed with two different signal-to-noise ratios (left panel SNR is 5 dB better than right panel).
In the right panel in Figure 6, the signal-to-noise ratio is 5 dB worse. It is harder to define whether or not there is a speech signal in the presence of the noise. This is the problem with modulation analysis: when there is worse than an approximately +10 dB signal-to-noise ratio, it is difficult to know whether or not speech is present.
Even when it is determined that speech is present, it doesn’t mean you can separate it out. Spectral analysis only determines whether or not that channel is being dominated by noise. If the channel is defined as being dominated by noise and gain is reduced, that gain reduction will also reduce speech signals in that channel. Then, you’re counting on the brain to put together the rest of the desired signal.
Limitations of Spectral Subtraction
There are some limitations of spectral subtraction. It is not a fully effective way of getting rid of noise. For people who use hearing aids in noisy environments, the basic principles used in noise reduction in hearing aids (spectral subtraction using modulation analysis), are not enough to make the noise go away. This is especially true when there is broadband noise, or the noise consists of other people talking.
The other issue with spectral subtraction in hearing aids is that the filtering is relatively long-term (i.e., lasting over several to many seconds). It takes this long to analyze the channels, determine which channels are noise-dominant, and apply gain reduction in those channels.
One of my colleagues compares it to the speed at which you walk. In essence, the idea is that as you move from room to room, environment to environment, if the noise pattern is different in one room than another, then you’ll get a slow adjustment in the way these hearing aids respond as you move from location to location. Often, it’s not you moving from location to location. It could be that the environment changes, or a noise source enters or leaves. The main idea is that it’s not a moment-to-moment change in the spectrum of the hearing aid -- it’s more of a long-term, gradual change.
One of the reasons for the gradual change is that if it happens too quickly and it is not precise, it can create sound quality issues. The patient may feel like there’s too much happening in the hearing aid. The rate has to either be gradual or extremely fast, almost on a phoneme-to-phoneme basis. Spectral subtraction, especially based on modulation analysis, cannot happen fast enough to provide a good sound quality, so it must be done on a very gradual basis.
If noise reduction is not a very effective way of getting rid of noise, why is it used in hearing aids? As most professionals know, it’s used because hearing aids with noise reduction sound better. In situations where the background noise is more narrowband such as an air conditioner running, you can eliminate that part of the spectrum and the brain will not notice anything is gone. When noise is low frequency dominant, you can reduce the low frequencies to get rid of the noise, while leaving mid- and high frequencies. In this case there is
plenty of speech information for the brain to use. Patients typically report a positive effect of noise reduction, stating that it’s easier for them to be in environments that have noise. They report that it is not as overwhelming to be in noisy environments and it is less fatiguing.
Essentially, noise reduction does not improve the speech perception abilities of the patient, because it does not provide more speech information to use. It simply removes enough of the noise out of the environment so that it is not overwhelming.
Spatial Subtraction
The second type of subtractive approach I refer to as spatial subtraction. Spatial subtraction is synonymous with directionality. The reason I use the term “spatial subtraction” in this course is to illustrate that directionality is a subtractive approach. Similar to noise reduction, where you’re trying to get rid of noise by taking out parts of the spectrum, in directionality, you’re trying to get rid of noise by taking out parts of the listening space. In other words, you’re trying to subtract out sounds coming from certain angles, to allow the person to concentrate in one particular angle, usually the angle immediately in front of the person. You’re trying to make the bad stuff go away, and keep only the good stuff. That generally defines subtractive approaches.
To review, nearly all variants of directionality in the market today use adaptive polar plots. In other words, the sensitivity pattern of the microphone changes over time to try and defeat the major source of sound coming from the back or sides of the listener. These polar plots can be adjusted so that the nulls (i.e., the direction where the microphone is least sensitive) are pointed in the direction of the dominant noise source in that particular frequency region.
I say that “particular frequency region,” because hearing aids can have directionality deployed in multiple channels. Most hearing aids today can have one polar plot in one frequency region, and a different polar plot in a different frequency region. Within that frequency region, the polar plot will adjust itself based on simple mathematical principles. It will adjust so that the null is pointed towards the dominant sound source coming from the back or sides of the patient. The objective is to subtract out that part of the overall signal.
Directionality works well under certain conditions. If you’re in a condition where the acoustics are good for directionality, then you can get a significant improvement in the signal-to-noise ratio. If the dominant noise source is speech coming from the back or sides, you can get an improvement in signal-to-noise ratio even in the presence of this broadband signal. With directionality, you’re not subtracting out parts of the spectrum, but you’re subtracting out parts of the listening space. You can still leave a good broadband signal for the patient to hear, but subtract out other broadband signals that are coming from different locations.
A series of studies were conducted ten years ago at Walter Reed Army Medical Center (e.g. Walden, Surr, Cord, & Dyrlund, 2004; Walden et al., 2005). The purpose of the studies was to define the conditions under which directionality works well. They defined those conditions as having the following characteristics:
- The desired speech sounds are from the front
- There is some noise in that environment, coming from the backs or sides
- The speaker is not too far away from you
- There is not too much reverberation in the environment
If those conditions are met, then directionality works well and is rated favorably by patients. They recognize the improvement that directionality provides in those situations. However, patients prefer the sound quality of a hearing aid when it is in omnidirectional mode. They receive a fuller sound picture. It is not quite as noisy and it is a better quality audio signal. Patients prefer the way a hearing aid sounds when it is in omnidirectional mode, unless there is too much noise in the environment. In a noisy environment, if noise can be reduced via directionality, they prefer that the hearing aid switches into directional.
Automatic directional systems automatically change between omnidirectional and directional modes. With these systems, it is important that the hearing aid is in omnidirectional mode at the right times, and in directional mode at the right times. Different manufacturers have different schemes about how the hearing aids decide where they should be directionally. In general, these systems work by identifying and reducing sounds coming from the back or the sides, and leaving the sounds from the front (which is assumed to be the signal of interest).
In order for automatic directionality to work well, it is necessary for the acoustic environment to be set up the right way. I made a recording with speech coming from one meter in front of KEMAR, and noise coming from one meter behind KEMAR (Figure 7). Observe the waveform with directionality both on and off. Based on the waveforms, it might be difficult to see whether or not the signal-to-noise ratio has improved. However, the histogram at the bottom of Figure 7 shows the distribution of the levels on a moment-to-moment basis.
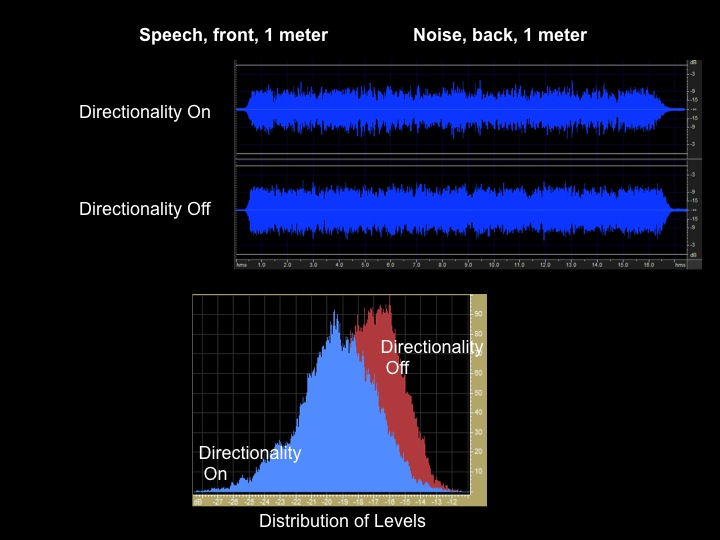
Figure 7. Directionality on v. off with speech at 1 meter from the front, and noise at 1 meter from the back.
When directionality is on versus off, notice that the histogram has shifted to a lower level, about 5 dB. What that means is that about 5 dB of the signal (the noise part of the signal) has been removed. By looking at histograms when directionality is turned on, we can determine whether or not we changed the signal. In this case, you see evidence that directionality had some benefit. Approximately a 4 to 5 dB improvement in signal-to-noise ratio is typically what is provided by a directional system in a low reverberant environment with speech coming from the front and noise coming from behind.
Using the same recording setup (speech one meter in front of the KEMAR, noise one meter behind KEMAR), I also performed the recording in a highly reverberant room that contained many different hard surfaces (Figure 8). If you look at the histogram, you will notice that there is no evidence that directionality had any impact on the signal. In a highly reverberant situation -- even though the noise started from the back and the speech started from the front -- the sound sources no longer have any true directional characteristics by the time they reach the listener (in this case, KEMAR).
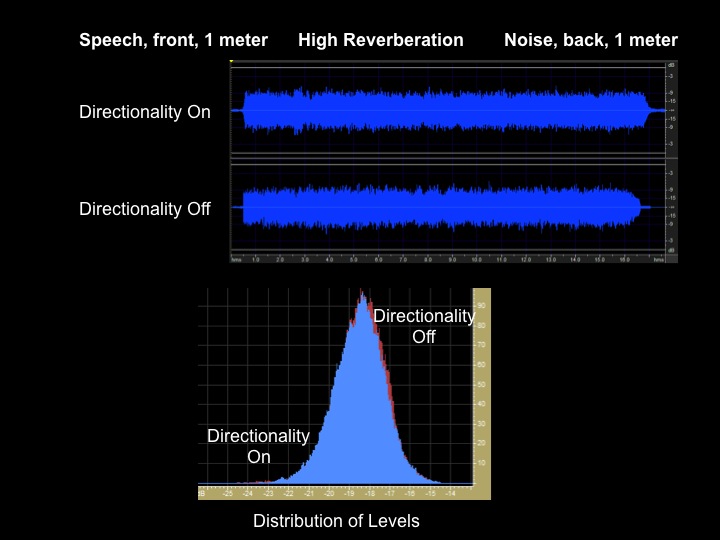
Figure 8. Directionality on v. off in a reverberant environment.
Directionality works by comparing the arrival time of signals to the front and back microphones. By looking at arrival times to the front and back microphones, the system can define that some things were starting from the back and moving forward, and some things were starting from the front and moving backwards. However, because of all the reflection in a reverberant environment, the arrival times do not indicate from which directions the signals are coming; in effect, the reverberation washes out these cues. In this example, even though the speech started from the front and the noise was in back, directionality had no benefit. This is one of the limits of directionality.
One of the characteristics of spatial subtraction (or directionality) is that directionality reduces all signals in the null. In other words, whatever the sound source is (speech or non-speech), it will be reduced if it is at a dominant level. Hearing aid directionality is a relatively simple system in terms of the way it sets polar plots. Polar plots are based on trying to minimize the sound pressure level getting to the hearing aid. It does not make much distinction whether or not that sound is a speech or non-speech signal.
Beamforming
One of the advances in directionality that has occurred over the last several years is based on the ability of wirelessly connecting two hearing aids together on either side of the ear, -- beam forming. The concept of beam forming has been around for 30-plus years. In hearing aids with multiple microphones, if you can move the microphones away from each other spatially, then you can use a more powerful directional approach in order to isolate sounds coming directly from the front or from the sides.
When directionality is deployed in just one hearing aid at a time, the most that you can separate the two microphones is a few millimeters. When you have two hearing aids that are “talking” to each other, you now have four microphones that are farther apart from each other, and you can use a more powerful directional approach. That approach is called beamforming.
Beamforming has been around for decades, and has been implemented in hearing aids in different ways over time. Once hearing aids via wireless technologies became able to communicate with each other, a more advanced beamforming approach was used in hearing aids.
Imagine you are in an environment where you are trying to listen to someone in front of you, but there are other conversations going on in front of you, or off slightly to the sides in front of you. This is a situation that would not be handled effectively by traditional directionality (Figure 9).
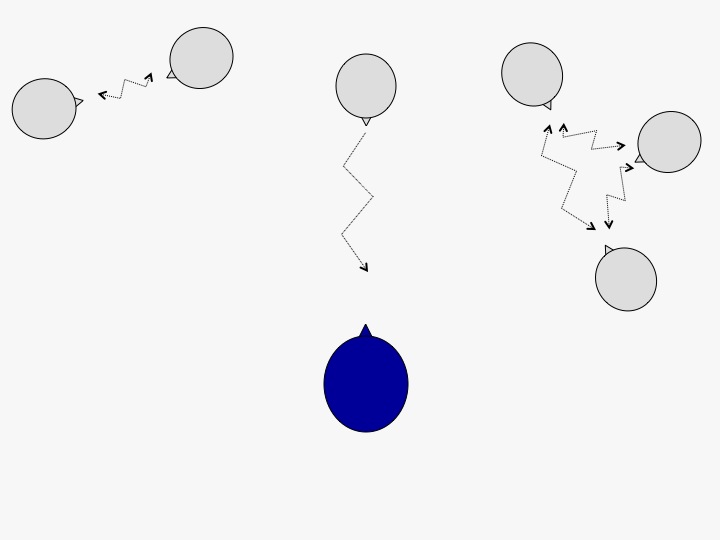
Figure 9. Environment with desired signal and competing noise sources all occurring in front of the listener.
Beamforming can create a more focused beam in one very narrow direction, towards the front (Figure 10). The idea is to provide a much more significant improvement in the signal-to-noise ratio, in a diffuse environment where the source of sound is not only from the back and sides of the listener.
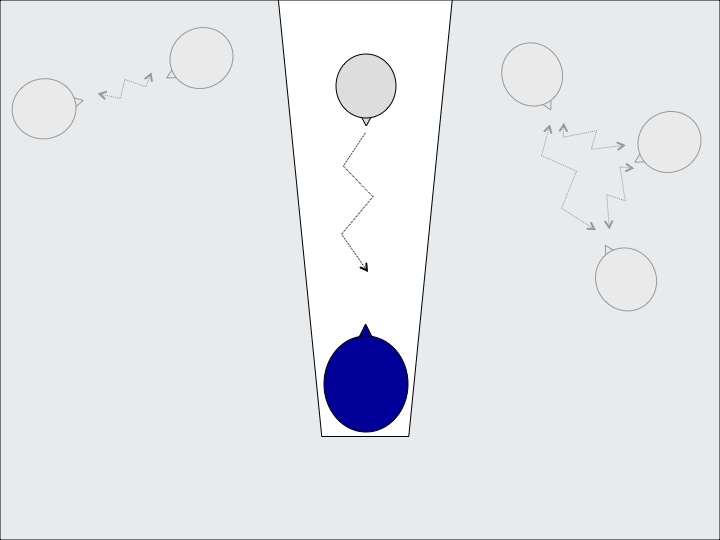
Figure 10. The narrow beam of beamforming.
There are a lot of sound quality issues that go along with beamforming, and also some usability issues. One of the usability issues is that you only hear what is in the narrow beam. Beamforming is the ultimate hearing aid application of subtractive approaches, meaning that everything else seems to be brought down and taken out of the picture, and the only thing that you listen to is what is right in front of you.
That might immediately strike you as a good thing, because your patients complain about situations with other people talking. However, what it ends up creating for a lot of patients is a very isolated sense of sound. The sense that the only thing you hear is right in front of you, and everything else has been taken out of the picture.
There are advantages to the beamforming approach. In a noisy environment, it may provide the needed signal-to-noise ratio. However, one downside is that it isolates the listener from everything else.
Making Noise Go Away
It is difficult to create solutions to make noise go away without some disadvantages. Subtractive approaches eliminate things out of the sound picture. The cost of trying to improve speech perception could be the cost of losing things out of the sound picture that might be valuable to the patient.
In everyday situations, noise reduction and directionality are not as active as you might think they are. Figure 13 shows data from 103 users of our hearing aid, Alta Pro (Figure 11). These patients use hearing aids on a relatively frequent basi, averaging over 11 hours per day of use. The data show the amount of time that different signals occur in the patients’ environments. The signal types are: speech, speech plus noise, or noise.
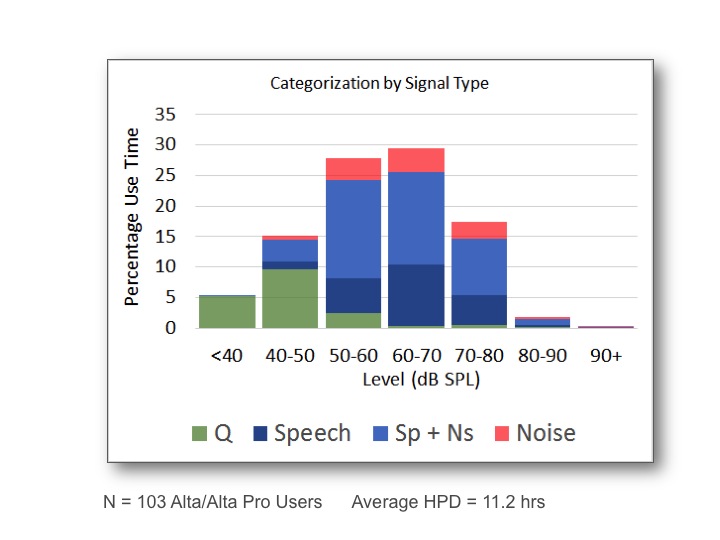
Figure 11. The percentage of time that various signals and levels occur in everyday environments for 103 hearing aid users.
In the range of 50 to 70 SPL, there is a significant amount of time that patients are in a speech + noise environment. Most of the time is spent in these moderate noise level environments, and for a majority of that time, there is both speech and noise present.
The problem is that noise reduction in hearing aids is level-dependent. This is data on how the noise reduction in our hearing aids would handle those different environments (Figure 12). In the left-hand panels are noise-only signals, at 80 dB on the top and 50 dB on the bottom. On the right panels are speech plus noise at +5 signal-to-noise ratio, at 80 and 50 dB inputs.
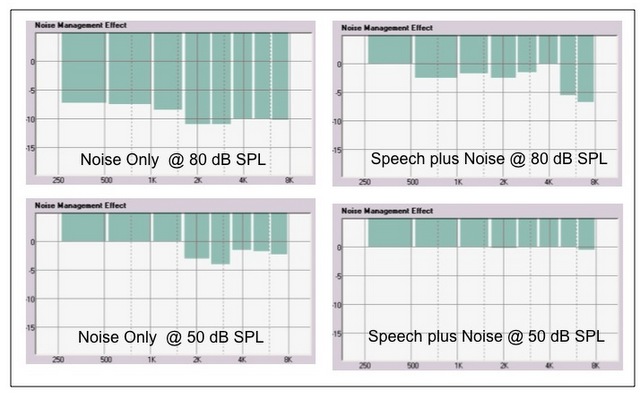
Figure 12. Level-dependent noise reduction in various environments.
The bar length represents the amount of noise reduction deployed. Notice that when listening to noise only at 80 dB, you get a lot of noise reduction. If you either drop the overall level of the noise only down to a moderate level (50 dB), or if you mix in a speech plus noise situation, there is not as much noise reduction. As is the case with most hearing aids, this is because noise reduction is level-dependent. Additionally, a system like our TriState Noise management has additional analysis that will detect and protect the speech signal, even if it is imbedded in noise. Overall, across manufacturers, noise reduction is not designed to kick in until the environment is relatively loud.
The problem is that there is a lot of speech plus noise that occurs in these moderate environments, but there is not a lot of noise reduction being applied. Just because noise is present in an environment, does not necessarily mean that noise reduction can find the noise, or reduce the noise.
The same can be true of directionality. Figure 13 shows how often directionality is active in our hearing aids, and the data is typical across companies. We have three modes of directionality: surround (omnidirectional or surround sound); split directionality (directionality above 1000 Hz.) and full directional.
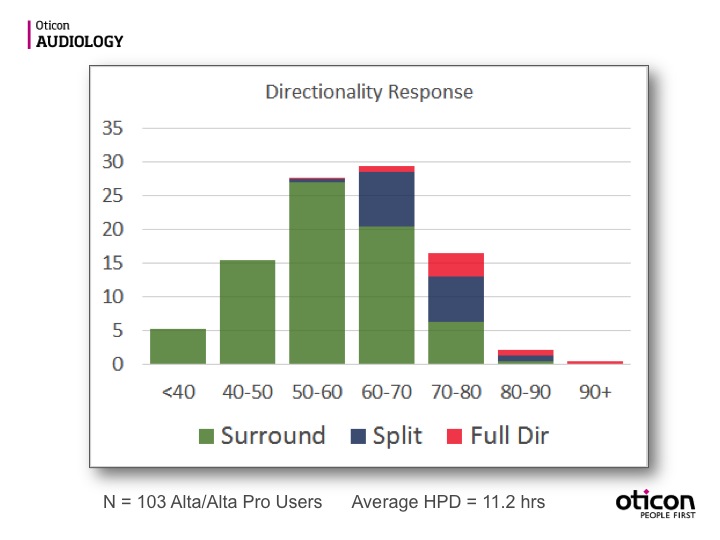
Figure 13. Directionality response.
If you look at split directionality and full directionality as a combination, you will notice that they are not active that much of the time (Figure 13). Approximately 20% of the time, directionality will be active in the hearing aid. Just because there is noise in the environment does not necessarily mean that directionality is going to activate.
In summary, when noise is present in the environment, it doesn’t necessarily mean that it will always being taken out of the hearing aid signal. With current approaches, they cannot attack the problem all of the time.
Completion Approaches
Earlier, I mentioned that the brain is opportunistic and will use whatever information it can. Another way of trying to solve the problem of speech understanding in noise is by giving the brain more information, rather than by taking information away. We count on the brain being able to sort through that information, in order to find speech in the environment.
One of the most effective ways to help a person improve speech understanding in noise is to put a hearing aid on them. In Figure 14, the gray speech spectrum is the unaided speech spectrum in the presence of a mild to moderate, gently sloping loss. The red is the aided speech spectrum that the patient receives from the hearing aid.
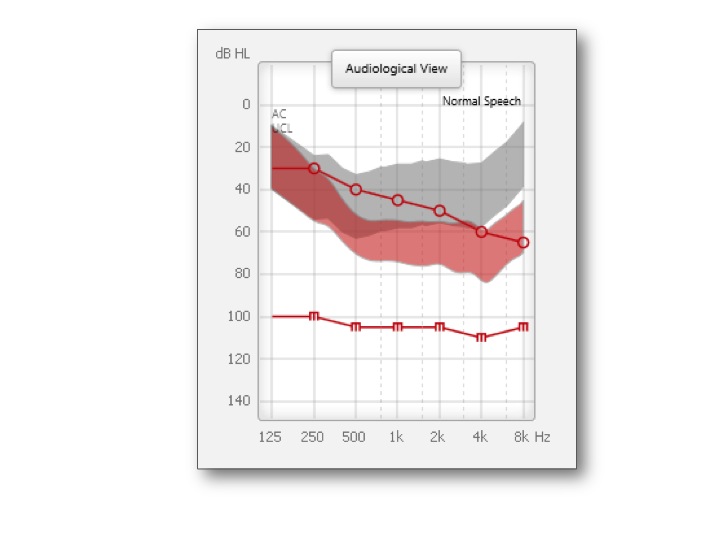
Figure 14. Unaided vs. aided speech spectrum.
There is significantly more of the speech spectrum that is audible in the gray spectrum versus the red. Even in the presence of a background noise (another person talking or multiple people talking), by making more speech audible (gray spectrum), you significantly improve the amount of opportunities that the brain has to hear the signal of interest. Now, the brain has more opportunities to find the good stuff, even though it may have to deal with more of the bad stuff.
Simply putting in a hearing aid with a good response, especially good bandwidth, often is enough to help a person significantly. For example, a study out of the University of South Carolina (Horwitz, Ahlstrom, & Dubno, 2008) looked at the impact of bandwidth on speech understanding in noise. Their data showed that with wider bandwidth, speech understanding in the presence of background noise (other people talking, other broadband signals) is improved, even though you’re giving the patient more noise at the same time. This is because you’re giving the patient more opportunities to hear important information in the speech signal, even if there is also more noise. You’re allowing the brain to have more access to information. A broadband hearing aid is a good example of a completion approach.
Speech Guard
Another approach that we use is called Speech Guard. Speech Guard preserves information in the speech signal that has been amplified by maintaining all the detail in the speech waveform. This is in contrast to fast-acting compression, which is typically employed in other hearing aids.
Speech Guard preserves more of the details of the waveform that can often become obscured when using a fast-acting compression approach. It preserves more information for the brain. Hearing aids with Speech Guard allow the person better access to speech waveforms. In October 2014, Andrea Pittman and colleagues demonstrated that the extra information in the signal with Speech Guard allows a better ability to understand the speech signal, especially in complex listening environments and when performing complex listening tasks.
Spatial Sound
The third example of a completion approach is Spatial Sound. In Oticon’s hearing aids, and those of at least one other manufacturer, we use an approach of connecting the two hearing aids together across the head. That preserves the relative level differences from one side of the head versus the other side of the head. It helps the brain to locate the directions or sources of sounds.
This idea of preserving inter-aural level differences is lost in non-linear hearing aids that are operating independently. Since the signals are coming in at different levels on one side of the head versus the other side of the head, non-linear hearing aids try to correct for that. However, if the two hearing aids communicate with each other, they recognize that this is the same signal coming in higher on one side of the head versus the other side of the head. By getting the hearing aids to communicate, you can try to preserve that information for the brain. It helps the brain sort through that complex listening environment and decide what to listen to, and what to ignore.
Future Approaches
In the future, we will see more emphasis in this area of making undesirable noises go away. There’s always value to using a subtractive approach in a hearing aid, if we can get rid of only the bad and keep the good. That’s been hard to do in hearing aids. As our signal processing continues to get better, we will see improvements in eliminating unwanted sounds.
We will also see more of an emphasis on trying to maintain good information for the brain. There has been a lot of recent research both in our industry and from outside it, regarding understanding the way the brain and our cognitive systems manage complex listening environments. We’re learning more and more about how to feed information to the brain, to allow the brain to best understand speech, especially in a complex environment.
I believe that future approaches in hearing aids are going to be focused on not simply making the bad stuff go away, but also on how we can best preserve usable information for the brain. I believe we will invent new products with the capability of allowing the brain to do what it does best: sort through different sound sources in order to perceive the speaker and hear the speech signal that the listener wants.
I hope this course provided you with a review of principles used in current approaches for dealing with speech in noise, and will serve as a foundation for you to understand the next generation of approaches that we will see in the future.
References
Axelsson, O., Nilsson, M.E., & Berglund, B. (2010). A principal components model of soundscape perception. JASA, 128(5), 2836-46. doi: 10.1121/1.3493436
Horwitz, A. R., Ahlstrom, J.B., and Dubno, J.R. 2008. Factors affecting the benefits of high-frequency amplification. Journal of Speech, Language, and Hearing Research, 51(3), 798–813.
Pittman, A.L., A.J. Pederson, and M.A. Rash. 2014. Effects of fast, slow, and adaptive amplitude compression on children’s and adults’ perception of meaningful acoustic information. Journal of the American Academy of Audiology. 25, 834-847.
Skagerstrand, A., Stenfelt, S., Arlinger, S., & Wikstrom, J. (2014). Sounds perceived as annoying by hearing-aid users in their daily soundscapes. IJA, 53(4), 259-269.
Walden, B.E., Surr, R.K., Cord, M.T., & Dyrlund, O. (2004). Predicting hearing aid microphone preference in everyday listening. JAAA 15, 365-396.
Walden, B.E., Surr, R.K., Grant, K.W., Summers, W.V., Cord, M.T., & Dyrlund, O. (2005). Effect of signal-to-noise ratio on directional microphone benefit and preference.
Citation
Schum, D. (2016, July). Attacking the noise problem: Current approaches. AudiologyOnline, Article 17637. Retrieved from https://www.audiologyonline.com.

