
Learning Outcomes
After this course, readers will be able to:
- Identify the major assumptions that underpin the standard fitting approaches used in audiology.
- Explain how fitting algorithms have been developed.
- Describe the foundation of the residual capabilities approach to fitting amplification.
Introduction
Thank you for your interest in this first of a three-part series on complex versus standard fittings. In part one, we'll examine some of the background material in order to frame the discussion about good strategies for dealing with more complex fittings. We want to create a different way of thinking about the process of fitting hearing aids in general, in order to make fitting complex cases more straightforward, and ultimately more successful. In parts two and three, we'll dive into some specific situations where the nature of the person's hearing loss creates situations where standard approaches may not completely solve the problem.
When we talk about complex fittings, we're typically referring to audiometric or etiology-based issues that can be very confusing for the audiologist; issues where the application of standard approaches might not necessarily achieve the best solution. Over the years, Oticon has developed insights and suggested approaches that the hearing care professional can use when they encounter some of these non-traditional fittings. Our end goal is to make sure that the hearing care professional has a much clearer path to success when dealing with more complicated cases.
Standard vs. Complex
To begin, let's define the typical characteristics that constitute a standard fitting. These are the conditions that most hearing care professionals likely think about when it comes to understanding the typical patient.
- Mild-to-moderate, moderate sensorineural hearing loss (SNHL)
- Flat to gently sloping shape
- Symmetrical hearing threshold level (HTL) and word recognition score (WRS)
- Good WRS in quiet
- Stable hearing loss
- Presbycusis (age-related hearing loss), perhaps with some noise-induced hearing loss (NIHL)
We're typically not talking about ski-slope losses in a standard fitting, for example, but rather someone with a less dramatic shape to the audiogram. These traits are not only the typical characteristics of patients being seen in the hearing aid clinic, but they are also used when hearing aid research is done. Much of what we have learned about fitting rationales and the way we approach hearing losses are based on research conducted on patients who fit these criteria. When hearing aid researchers go about setting up projects, often they have to decide which sort of patients they're going to see. These are typically the sort of criteria that are applied when selecting patients for a hearing loss study, in order to keep the test group similar. However, from a clinical standpoint, they don't necessarily capture those "outliers" that exist. In reality, they are not so much outliers, because most clinicians will be quick to recognize that many patients that fill up their appointment calendars don't fit all these criteria. When those outliers occur, the whole fitting process can be thrown a little bit out of whack. In this three-part series, we will be talking about patients who don't fit all these typical criteria, and we'll be examining some of these criteria as we go through the course today.
Assumptions When Fitting Hearing Aids
I want to start by taking a look at some of the assumptions we use when we go about our typical hearing aid fitting. In a typical fitting, a patient comes in, the thresholds are measured, word recognition scores are measured in quiet and/or noise, UCLs may or may not be measured, then this audiometric information is put into fitting software and/or into real-ear machines, depending on the choice of the clinician. Fitting targets are determined, either on the fitting software or on the real-ear machine or both. Hearing aids are fit and prescribed to match these targets. If real-ear techniques are being used, the adjustments will be made to the hearing aid to make sure that we hit those targets. That's what defines the standard approach to fitting hearing aids that is pretty common in our field right now. If the patient runs into problems, then those problems are dealt with in the fine-tuning process.
Prescriptive, Not Adaptive
What are some of the things that we assume when we fit? For example, one of the things that we use is a prescriptive method. In other words, when we fit hearing aids, we take information at the input stage (e.g., hearing thresholds) and use that information to determine what a hearing aid should do. We then fit a hearing aid based on those criteria, and we only make adjustments if things are not going well. The basic flow of the prescriptive process is: Input data --> Prescription --> Fine Tuning
The prescriptive process can be contrasted with an adaptive way of fitting hearing aids. A fully adaptive way of fitting hearing aids would be to put blank-slate hearing aids on a patient, and then use some sort of routine to determine the best settings for that patient, based on an adaptive, iterative process of fitting the hearing aids. The problem is that there is so much flexibility in modern hearing aids, it is mathematically impossible to do that. If you take a look at all of the combinations of settings in hearing aids and extrapolate it out, there are millions of different combinations. As such, it's impossible to be able to examine all combinations of settings for a patient. We have to somehow limit the amount of searching we could possibly do, because there's no way in a clinical environment that we could use a truly adaptive process. There have been approaches in the past that have examined the idea of using a prescriptive process, but again the math is not working in our favor. Even if you limit it to just a handful of parameters that could be adaptively adjusted in hearing aids, the math and the timing don't work out. As a result, we have fallen back to a prescriptive process, where we base the settings that we give a patient on certain assumptions that are driven off the input data, typically hearing thresholds, that we put into the system. We then deal with any patient concerns in what we refer to as "fine tuning", which is a final adjustment or a modification of the settings away from the prescription, based on things that the patient will tell us or things that we observe in real-ear settings.
I understand that the math works against us, so we must use a prescriptive approach. This process would be logical and make a lot of sense if most fittings were just fine with the prescription. However, in a significant number of our fittings, we spend a lot of time (perhaps too much time) in the fine-tuning process. The fact that so many fittings have to be adjusted after the fact would suggest that our prescriptive approaches are not totally capturing all the things that we need them to capture. That doesn't mean that I have any solutions for this problem. We know that it's an ongoing problem and so we fall back to the prescriptive process. Since fine tuning methods in our field are not very well described, it's up to the individual clinician to decide how they're going to fine tune and in which direction they will go. It provides a certain amount of vagueness to our clinical process. We are very strict about what those prescriptions are - some hearing care professionals are very strict about how close to targets they have to get when they're verifying their fittings. Every clinician uses a combination of experience, knowledge and guess work to fine tune, based on the patient's input.
There are some common issues that our patients describe (e.g., sound is too sharp, or too soft, or muddled). Once we have heard the patient's complaints, we then need to interpret what that means, so we can adjust the hearing aid settings and make corrections accordingly. In our field, that whole process is not very well defined. With complex fittings, it becomes even more muddy. Some examples of complex fittings include patients who have extremely restricted dynamic ranges, poor word recognition, or significant asymmetries between the ears. From clinician to clinician, there is a great deal of inconsistency about how to respond to these situations. In the field of audiology, we need to recognize that this is one of the assumptions under which we work.
Restore Audibility and Correct for Threshold Loss
Most prescriptive attempts are all about restoring audibility and correcting for threshold loss. When you take a look at the way fitting rationales are designed, the goal is to make sure that we make speech audible again. Because of the threshold loss, part of the speech signal is not going to be available to the patient unless they wear amplification. Our job is to determine how much amplification we should provide in each frequency region, in order to make sure that speech is audible again. Because of the loss of sensitivity inherent in hearing loss, we have to somehow amplify the signal to overcome that loss of threshold.
I think that it is important to dig into the rules that we use a little bit more, so that when we get to the point of restoring audibility, creating targets and matching those targets, we remember where some of these numbers come from. One of the nice movements in the field over the last 10 years has been the idea of using speech mapping instead of insertion gain as a way to verify what's going on in fittings. Many clinicians still use insertion gain, which is fine. Insertion gain and speech mapping provide the same information, but they are just different ways of looking at that information.
Figure 1 shows a speech map for the moderate speech level input being amplified to match certain targets somewhere in the patient's dynamic range. This is a pretty standard approach. I wanted to dig into where those targets come from, so you understand some of the assumptions that underline the way we conduct hearing aid fittings.
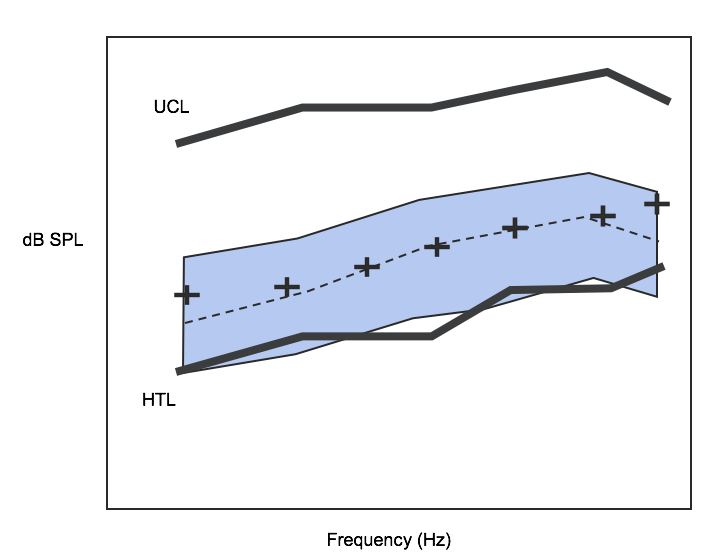
Figure 1. Speech map for moderate speech level input.
Example fitting rationale. Figure 2 shows a good example of the way a fitting rationale could be developed; it is a very simplified version of a fitting rationale. There are many more wrinkles that need to be worked into it, but I want to go through this with you so you understand some of the assumptions that are involved. Don't let the math scare you.

Figure 2. An example fitting rationale.
Let's take a look at the first line in Figure 2. If the hearing threshold level (HTL) is greater than 50, then the patient's assumed uncomfortable loudness level (UCL) is 100 dB plus half of how much it is above 50. In other words, UCLs for someone with a mild hearing loss are no different than UCLs for someone with normal hearing. Let's say we pick that level to be 100 dB SPL. Once you get above a moderate hearing loss, then the UCLs start to raise, but they only raise at about half the rate as the threshold change. For example, a patient with 70 dBA hearing loss, their UCL is going to increase by 10 dB, because that is half the difference between 70 and 50. The dynamic range starts to shrink once you get above about 50 dB hearing loss. That's a well-known observation, but this is how it would show up in a fitting rationale. Again, a couple of the assumptions are that the patient has a normal UCL, meaning similar to what a normal hearing person would have if they have a mild hearing loss. If they have a hearing loss above a mild hearing loss, then there's a standard rate at which that UCL is going to increase. Now, that assumption would be irrelevant if UCLs were directly measured, but UCLs are not measured on a lot of patients who get fit with hearing aids. If it's not going to be measured, then somehow it has to be calculated by the fitting software.
The second line indicates that the most comfortable loudness level (MCL) is halfway between the patient's UCL and their HTL. That's a standard assumption. If MCLs were measured directly, it might vary a little bit, but again MCLs are measured even less often than UCLs, especially with frequency-specific stimuli. The reason is that it's tricky to come up with a most comfortable level for a non-speech signal. It's kind of an odd question to ask a patient, and therefore most clinicians don't measure it. If they don't measure it, it has to be predicted.
The third line is that the gain applied to a 65-dB input is equal to the patient's MCL minus 65. In other words, how much gain do I need to raise a 65-dB input and place it at the patient's MCL. That assumption, the idea of placing moderate speech at the patient's MCL, is a fairly common assumption in a lot of fitting rationales. That's how it would show up mathematically in a very simplified version.
Next, we have to calculate compression. Compression is equal to 100 dB, which is the normal dynamic range for the normal hearing person, divided by the difference between UCL and HTL. Let's say that the patient has a 50-dB hearing loss. The UCL is going to be 100, the HTL is going to be 50. The difference there is 50. 100 divided by 50 equals two. You would have a compression ratio of 2.0. Again, compression ratios are usually figured out in a little bit more complex way than that, but you get the idea of how something like that would be calculated.
Finally, we determine gain for softer and louder inputs. Gain for 50 and gain for a louder input (gain for 80), is going to equal the gain for a 65 dB input and then modified by the compression ratio, because you need to get soft through loud gain to fit in the patient's remaining dynamic range.
The point of this exercise is to show you the assumptions that underpin fitting rationales. Fitting rationales are more complex than this, but you get the basic construct. You have to decide where you're going to place speech. Speech is going to be placed somewhere within the patient's dynamic range. You have to make the full range of speech, or as much of it as you want, to fit within that dynamic range. You have to somehow calculate what that compression ratio should be, and you have to make assumptions about the size of the dynamic range. Importantly, fitting algorithms are largely based on mean loudness perception data.
I want to take a look at an assumption about median data (Figure 3). This is data that came out of UCLA back in the 1980s. This is the relationship between patients' uncomfortable loudness levels (UCLs, also known as loudness discomfort levels or LDLs) and the patients' hearing thresholds. This data happened to be captured at 2000 Hz, but it's no different than data at any frequency you would test. The solid line is the median best fit line. The reason I like this dataset is because it shows the individual data points that led to that median line.
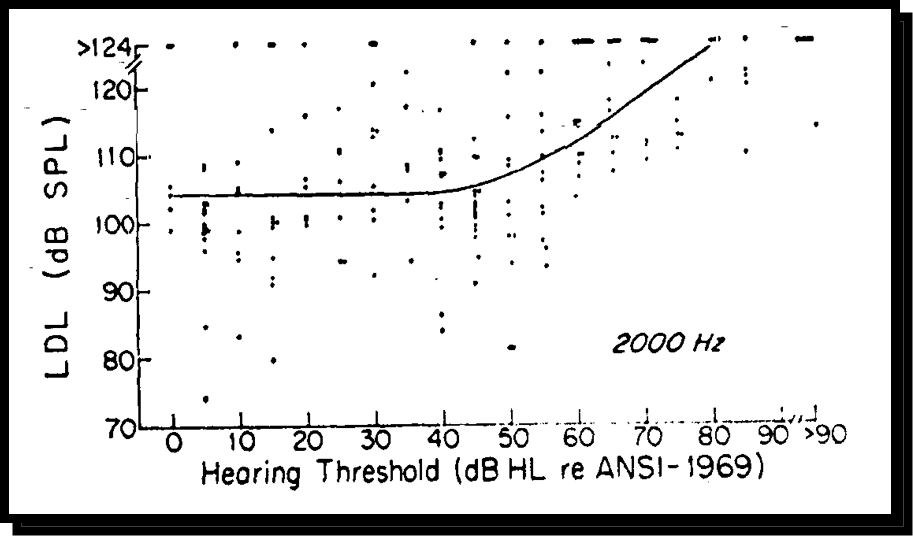
Figure 3. Median data.
You will notice in this dataset that UCLs don't really change from normal until you get beyond a mild hearing loss. You see in that 45 to 50 dB range, that's when the UCLs start to rise, but they don't rise as quickly as the thresholds are rising. They increase at approximately half the rate that the thresholds are increasing. The median line corresponds to that simple rationale that I gave you. It is important to notice is how much variability in real clinical data goes into that median relationship between hearing thresholds and UCLs. For example, take a look at 40 dB of hearing loss. You can have people with UCLs or LDLs down as low as 80 or 85, but as high as well over 120 dB. Those patients are all going to be fit the same way based on a fitting rationale that would use some sort of predictive UCL. One way to get around this is to individually measure UCLs, but that doesn't happen a lot. It's not just UCLs that we assume. We often make assumptions about where the patient's most comfortable loudness level might be, and that might be built into certain fitting rationales or other loudness dynamic considerations.
The point I'm trying to make is that even within true clinical populations, there is a significant amount of variability on almost any psychoacoustic dimension that you could measure. If I was showing you frequency resolution or temporal resolution or other loudness-related measures, you're going to see similar patient-to-patient variability, in terms of what the real data looks like. Because of that, any time that you fit hearing aids based on average psychoacoustic data, you should immediately recognize the fact that there is going to be variability from patient to patient on how closely that average assumption is going to fit for that individual patient. Fitting rationales that are based on average psychoacoustic principles should, by definition, not be appropriate for all patients. There should be situations where patients, for example, want more loudness or less loudness out of their hearing aids, because their individual loudness function related to their hearing loss just doesn't follow the median pattern as closely as you might assume.
Measurable Hearing is Usable Hearing
The next set of assumptions relate to the usability of the patient's remaining dynamic range. One of those assumptions is that measurable hearing is usable hearing. Let's say I measure a threshold at 2000 Hz at 65 dB, and I either measure or use a predicted UCL of 110. Then, what I am assuming in standard hearing aid practice is that anything from 65 to 110 is usable hearing in that patient's remaining dynamic range. If we go back to the speech mapping example from earlier, I showed you that space between thresholds and UCLs. Once we establish thresholds and once we establish the UCL, most fitting rationales will assume that anything between those two lines is usable, as far as placing amplified speech up there. That is generally a safe assumption, but not necessarily all the time. In other words, it doesn't take a lot of psychoacoustic integrity to be able to establish a threshold on a patient. Putting a pure tone in the ear and getting the patient to raise their hand or push a button doesn't require an auditory system that can do a complex task. But we use a measurement of hearing threshold using simple stimuli to predict or to create a space in which we are presenting a complex signal (amplified speech), especially amplified speech in a background of competition. The psychoacoustic integrity that it takes to be able to effectively encode and process a complex signal like speech is not necessarily the same sort of integrity that it takes simply to establish a threshold. Although we use that and it's a safe assumption in many cases, it's important to recognize that just because you've established a threshold doesn't mean that the hearing above that threshold is necessarily all that useful to the patient.
Make the Full Range of Inputs Fit
Another thing that speech mapping has created for us as far as a goal of fitting, is that we try to make the full dynamic range of signals fit within the remaining dynamic range of the patient. For the last three decades, that's what multi-channel non-linear hearing aids have been about: defining how much room we have to work with, taking soft through loud speech and using compression, in order to make sure that that full range of speech input fits within the patient's remaining dynamic range. The purpose of using multi-channel non-linear compression is making everything fit. Again, that's a very safe assumption in a lot of situations, however in some cases, if the remaining hearing isn't usable in a particular frequency region, that assumption can lead us astray.
More Bandwidth is Better
The third assumption is the more bandwidth, the better. One of the focuses of hearing aids has always been to increase the bandwidth. It used to be that hearing aids wouldn't give you much past 1000 Hz, and then it was 2000 Hz, and then it was 4000 Hz. Today, you have hearing aids with a usable bandwidth out close to 8000 to 10,000 Hz. Eventually we'll go beyond that level. The assumption being that the more bandwidth we can get, the farther out in frequency that we can reach, the more information that we can bring into the patient's auditory system. That is a safe assumption, because there's always potential for information out there. Again, you're talking about frequency regions that might not be working particularly well. Just because you can amplify out to eight or 10 kHz, that doesn't necessarily mean that the ear can use that information. We've seen a little bit of movement to deal with that over the last 10 years. For example, the TENS test is a procedure to define the usability of the remaining hearing, especially in the high frequency region.
The idea of using frequency-lowering techniques to move information from the high frequencies down to the mid frequencies has been another emerging discussion. When most people think about frequency-lowering techniques, they think of it as a way of providing audibility in the high frequencies. In other words, if some of the high frequencies cannot be reached because of severe thresholds, they can move them down to the mid frequencies. The reality is that frequency lowering also has relevancy if the high frequency hearing isn't usable to the patient. You might be able to establish thresholds, but that doesn't necessarily mean that that part of the patient's auditory system can encode information effectively up there. Perhaps another use of frequency lowering is more about moving away from bad parts of the auditory system. In most cases when we fit hearing aids, we try to go out as far in frequency as we possibly can. Again, it's a good assumption, it makes a lot of sense, and it applies in many cases, but there may be cases where that assumption doesn't apply.
How do we describe a patient's auditory status? When we describe a patient's auditory status, by default, we often talk about what the patient's audiogram looks like. We treat hearing thresholds as if that's a full description of the patient's auditory system. Most clinicians know that that's not a complete description of the patient's auditory system, but it is the shorthand that we use in the field of audiology. It is important to remember that hearing impairment isn't necessarily just a change in the audiogram. The audiogram is only one measure of one aspect of the patient's hearing. It's not a complete description of the patient's hearing. We are dealing with a health change in the patient. We're dealing with a physiological change away from normal in the condition of the ear. This change can manifest in many different ways, in terms of the way the system is working and in terms of what the person can do with their hearing, those things may not be fully captured by the audiogram. However, in almost all cases, the fitting rationales that we use are driven by the audiogram. I don't know of any fitting rationale in existence that is driven by the physiological condition of the ear, beyond what is captured by the audiogram. It is important to recognize this assumption that if you measure someone's threshold, that somehow you understand how well their hearing is working. In fact, you understand one part about what their hearing is doing, but you don't necessarily understand everything.
What do we assume about SNHL? One of the things we assume about sensorineural hearing loss is captured in the left-hand panel of Figure 4. As stated earlier, the normal hearing person has a dynamic range of about 100 dB. Again, it depends on frequency, but that's a rough approximation. If you go from the least intense parts of soft speech to the most intense parts of loud speech, you're talking about a speech range that almost fills the normal dynamic range. We know that patients with sensorineural hearing loss are going to have some sort of restriction in that dynamic range, since UCLs don't begin rising until you get above about 50 dB hearing loss. People with sensorineural hearing loss are going to have some sort of restriction to their dynamic range. Therefore, we use multi-channel non-linear approaches in order to fit the full dynamic range of speech into that reduced dynamic range of the patient.
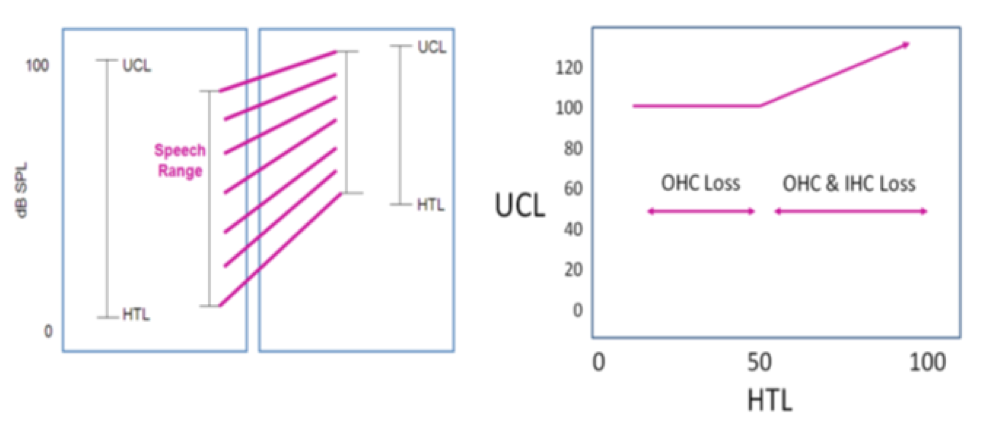
Figure 4. Assumptions about sensorineural hearing loss.
On the right side of Figure 4 is a simplified model that we have been using for a few decades to describe that process, where we talk about hearing loss up through mild hearing loss as being primarily just outer hair cell (OHC) loss. Once you get above moderate hearing loss, you're talking about some sort of combination of outer hair cell loss and inner hair cell (IHC) loss. Remember that inner hair cells are the sensory fibers that take information from the periphery and turn it into a neural code to go up the eighth nerve to the auditory cortex. Outer hair cells are there to modify the sensitivity of the inner hair cells. The outer hair cells sharpen the sensitivity of the inner hair cells. In a typical case of mild hearing loss, it generally seems to be a case of loss of outer hair cell function. The inner hair cells are still there waiting to be stimulated; you just have to get the stimulation above 40 or 50 dB input before that inner hair cell can be stimulated. They lose their sensitivity because of loss of outer hair cells.
Once you start getting into the moderate hearing loss range and above, then typically what you're seeing is a combination of outer hair cell loss and inner hair cell loss. Some of the primary sensory fibers, the inner hairs have now been lost. Again, this is a generalized assumption about the way sensorineural hearing loss works. It's not a true complete capture of what happens. In a lot of cases, you see a much more complex pattern of damage beyond just looking at just inner hair cell loss and outer hair loss. You may even see some strange patterns, such as a full complement of outer hair cells with inner hair cell loss. Or, you can see the opposite, where there is complete inner hair cell preservation and only outer hair cell loss, or a combination thereof. That simplifying assumption is exactly that. It captures a lot of what's going on, but it doesn't capture everything.
What else must go right? It's important to remember what else has to go right within the auditory system. Remember, the stimulation of inner hair cells is just the end process of a lot of other supporting processes that must occur within the inner ear for hearing to work well. For example, you have the fluid cavities and the electrochemical balance of those fluids has to be right. The membranes that comprise the inside of the cochlea have to be intact and working properly. The connection between the hair cells and the eighth nerve has to be healthy and working right. The mechanical movement of the fluid within the inner ear has to work well. The blood supply to the inner ear has to be healthy. Other key supporting features within the auditory system have to be working well for the hearing mechanism to work properly. The hearing mechanism is a highly calibrated, highly tuned system. If any part of the system gets thrown off, then the whole system can fail or act in a disruptive way. When we use that simplifying model of inner hair cells and outer hair cells for sensorineural hearing loss, although that captures the typical sort of pattern we would see, that doesn't necessarily capture everything we need to know about how the individual's auditory system is working.
Let's look back to the speech map in Figure 1, which is from a routine clinical procedure. One of the things you will notices is that the moderate speech banana has been matched very closely to the prescribed targets. You might look at this speech map and think that it is a good fit, which is a perfectly legitimate interpretation of that result. However, another one of the things that you should see is a working space. You can see the thresholds and the UCLs and a playing field that you, as the clinician, get to use for that individual patient. One of the questions that should start to come to mind when you are fitting hearing aids is, "How good is that working space? Do I know that that working space is going to provide a proper encoding of the information that goes up to the auditory cortex? Does that hearing work well?" You may know the range of that hearing and know the difference between thresholds and UCLs, but taking a look at it this way doesn't tell you the quality of the remaining hearing.
In the 1980s, Plomp talked about the two aspects of hearing loss: The A component and the D component. The A component is the audibility component that is captured by thresholds. The D component is the distortional aspect of hearing loss, which is measured functionally by using speech and noise measures. I believe that the D component is the answer to the question, "How good is the remaining hearing." That working space that you see on the screen: how functional is it for the patient? For the typical patient with mild to moderate hearing loss (flat to gently sloping, good word recognition, symmetrical thresholds), that working space usually works pretty well and you can use it fully. You can use as much bandwidth, you can make things fit using multi-channel, non-linear approaches into that working space and try to fully exploit the usability of that working space. However, when we talk about some of the more complex fitting populations, then the quality of that remaining space might not be as good as it is in the typical hearing loss. As such, the fitting approaches might need to be modified.
All Speech is Valuable
Another set of assumptions that we use when we fit hearing aids is that all speech is valuable. In other words, speech across the frequency of range is important to be able to present to the patient. Modern fitting rationales, at times, do recognize that there is some variability across frequency range, in terms of the usability or the importance of speech signals. The contrast comes into play when you talk about the difference between the DSL non-linear approach and the NAL-NL2 non-linear approach. DSL non-linear was developed primarily with children in mind. Since children need to develop speech and language, they are very careful not to make any limiting assumptions about the usability of speech in different frequency regions. The goal of DSL is to make all of the speech signal audible to the patient. Now, they do recognize that you can't overcompress the signal, so there are some compression limits put into that. However, they don't make any strong assumptions about some frequencies being more important than others.
NAL-NL2 takes a different approach. NAL-NL2 recognizes that these speech signals change in importance as you move across frequencies. Because certain frequency regions are more important than others, NAL-NL2 will put an emphasis in certain frequency regions (approximately 1 to 4 kHZ) specifically to try to capture the most important parts of the speech signal. In general, when we fit hearing aids, our goal is to make as broad a bandwidth of a speech signal as audible as possible, because we believe that there is information strewn across the full bandwidth of the speech signal. While this is true, it doesn't necessarily mean that all that information is equally as valuable.
Targets Are "The Sweet Spot"
Another assumption that affects the way we go about fitting hearing aids is that targets are some sort of sweet spot. It is the idea that if you hit targets, you're going to unlock hidden speech understanding skills within the patient; and conversely, if you miss the targets by a certain amount, your patient loses the ability to extract information from the speech signal. I'll show you an example in a few moments that questions this assumption, but first I want to set up with some other points before I get to that.
One of the reasons those targets exist is because they provide the best way to make everything fit within the remaining dynamic range. In other words, if you can make moderate speech hit these targets, then you're maximizing your opportunity to get the full dynamic range of speech (soft through loud) to fit within the patient's remaining dynamic range. Clinicians will often treat targets as if they're some sort of hidden magical point within the middle of the patient's dynamic range that absolutely has to be locked onto or the patient's going to miss something about the speech signal. The only thing that we can say about the speech signal is that it has to be audible for the patient to understand it. If it's inaudible, then the patient's going to miss the information. There is very little evidence that somehow speech is more intelligible in certain places within the patient's remaining dynamic range. That assumption has never been proven in any way, shape or form. The idea that targets are some sort of sweet spot simply cannot be justified by any data that we have. They are a functional place to help the remaining dynamic range be used to the greatest degree possible, but it isn't necessarily because the average spectrum of moderate speech must hit those targets in order for speech to be best understood by the patient.
In Figure 5, I have tried to visually capture what I just talked about, in terms of rationales. This represents the DSL way of thinking, which is that you want to take the full speech range and place it within the remaining dynamic range of the patient. It doesn't matter which frequency region you're dealing with; you want to do it across the full bandwidth.
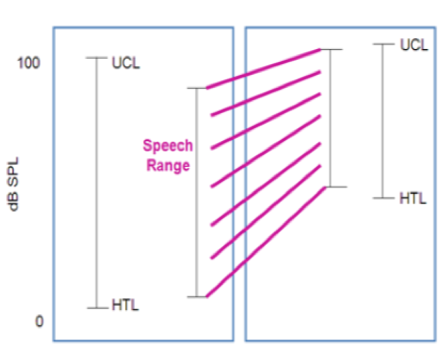
Figure 5. An illustration of moving the speech range into the patient's dynamic range.
In Figure 6, we can see the speech importance function that's determined by the Articulation Index. The Articulation Index, or Speech Intelligibility Index (SII), has been telling us for decades that speech from about 1000 Hz out to 4000 Hz carries the largest information burden in the speech signal. In this graphic, the background in blue are those speech importance functions from the Articulation Index, and the relative importance of certain frequency regions over others. You see that peak around 2500 Hz in terms of the importance function. I've also overlaid the frequency regions that account for the different phonemic contrasts in English. For example, the place differences on plosives as determined by the bursts, that's going to occur from about 1500 Hz out to about 4000 Hz. The affricates are a little bit more limited where they are, but again they're a high-frequency cue. The second formant transitions, consonant-to-vowels or vowel-to-consonant transitions, which also have been identified as a very important cue in the ongoing speech signal, those transitions go from about 1000 Hz out to about 5000 Hz, etc. You see the first formant vowels and the second formant vowels, et cetera.
The reason I put those classes of phonemic information on the slide is it explains why speech from about 1000 Hz to 4000 Hz is so important. There are so many different classes of information that are differentiated in that region. If you get a very good response for a patient around 2000 Hz plus or minus an octave, you are capturing where most of the contrast in the speech signal occurs. That's why some parts of the spectrum of the speech signal are more important than other parts, because there are more things going on there. This graphical way of looking at the importance of the long-term spectrum of speech is important, because it breaks down the fact that it's not just about the acoustics of the speech signal, but it's also about the information content in the different frequency regions.
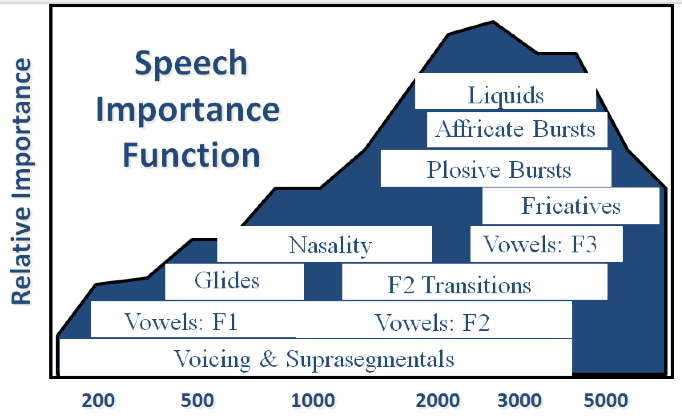
Figure 6. Speech importance function.
Assumptions Related to Fine Tuning
The next set of related assumptions indicate that fine tuning is a movement away from optimal, and that we typically fit to intelligibility and we fine tune to satisfy sound quality. These two assumptions state that:
- Targets mean something, and we have to match those targets as closely as we can.
- If we have to fine tune the response (especially in the mid to high frequencies), somehow we are stealing information away from the patient.
- There's an optimal, "magic" spot where we're going to hit those targets; if we have to move away from the targets, we are moving away from some sort of optimal setting for the patient.
- Targets are determined based on trying to maximize speech intelligibility.
- If we allow the patient to drive the fine-tuning process, they are often going to be driving that process based on sound quality concerns, which may be in contrast to what we're trying to accomplish with the fitting.
Sometimes we act as if there's a conflict between what we (the hearing care professionals) want to get out of the hearing aid fitting and what the patient wants to get out of the hearing aid fitting. To me, that's sort of an odd sort of way of thinking about the situation, because it is the patient's hearing. One of the things that I tried to demonstrate earlier (with that UCL data out of UCLA) is that there is a lot of variability in the psychoacoustic performance from patient to patient to patient. If we fit targets, and we get too rigid about keeping the fitting at those targets, we are not reflecting what is known about the evidence in our field. There's a lot of talk these days about evidence-based fitting. Part of the evidence that underpins psychoacoustics and sensorineural hearing loss is that there's a tremendous amount of variability from patient to patient. If we try to make all patients with 60 dB of hearing loss at a particular frequency listen to exactly the same level of amplified speech signals, then we are not acknowledging the true evidence in our field: the variability across patients. Therefore, target fittings should be viewed as a good place to start. If a patient is complaining that things are too loud or too soft or too sharp, we shouldn't pretend as if the patient is somehow compromising their fitting by moving away from an optimal setting. We should view it as the patient is adjusting the fitting rationale to best represent how their individual auditory system works.
Frequency response, speech understanding, and sound quality. In my opinion, many hearing care professionals believe the fine tuning is somehow at odds with the optimal fitting. As evidence against this belief, I want to examine an important study that came out of Holland about 20 years ago (van Buuren, Festen and Plomp, 1995). In that study, the researchers tried a variety of different frequency responses on a group of patients and looked at speech understanding and sound quality. They started with the NAL fitting, and then systematically moved away from the NAL fitting in both the low frequencies, and in the high frequencies. All in all, they tried 25 different variations of the NAL fitting that either had more or less low frequencies and/or high frequencies.
For all 25 fittings, they conducted adaptive speech in noise testing. Their data show that many of the frequency responses provided results that were pretty close to the results from the NAL response. The only variations where speech understanding was significantly poorer from the NAL were the ones that had the maximum amount of low frequencies, causing an upward spread of masking. The point here is that if a target was some sort of sweet spot, then the NAL response would yield the best performance on the speech in noise task, and the results from all the other frequency responses would be significantly poorer. Instead, this study showed that a broad range of frequency responses provided similar results to the NAL response for these patients.
They also measured sound quality - both "clearness" and "pleasantness". There were good ratings for a lot of the frequency responses. It was only those responses that had the most high frequencies or a lot of low frequencies where the ratings for clearness and pleasantness were poor. There was quite a bit of variability in the sound quality ratings, meaning that there's a lot of variability from patient to patient in how they perceive and rate clearness and pleasantness. While the ratings from the NAL response were good, there are also many other responses away from that target that could be equally acceptable to the patient.
To me, this study tells us that targets are a good practical place to start if you're trying to make the full range of speech fit within the patient's dynamic range, but there's nothing specifically about the target that will unlock speech understanding per se. Targets place the moderate speech spectrum appropriately so that you can make everything else fit within the patient's dynamic range. However, once you do that, as long as you don't overemphasize the low frequencies, there are many variations of the target that may very well provide good speech understanding. Additionally, in regard to sound quality, the target should deliver an acceptable sound quality as should a range of frequency responses around that target.
Another thing to remember is that full-time hearing aid users wear their devices at least 16 hours a day, seven days a week. We provide an audiological definition of what a fitting should be: we are fitting to target based on our assumptions about speech audibility and speech intelligibility. It is important to keep in mind that patients have every right to tell us how they want the hearing aid to sound: it's their hearing after all. When we fit hearing aids, we're re-creating the world of sound for these patients. If we expect them to wear hearing aids 16 hours a day, seven days a week, we also need to respect their opinions about the way their hearing aids should sound. This idea that somehow fine tuning is a movement away from optimal is a very audiological-centric way of thinking about things. In terms of the patient's input and their rights, they should have the opportunity to hear sound the way they want to hear it.
Both Ears Contribute Equally / Two Monaural Fittings
The final set of assumptions that I want to investigate is the idea that both ears contribute equally to the fitting, and that when we fit hearing aids, mostly we're fitting two monaural fittings. In other words, we fit one hearing aid to one ear and the other hearing aid to the other ear; we don't necessarily adjust the fittings in a big way when we fit two hearing aids on two ears. Some hearing aid fittings are adjusted for loudness to compensate for two ears versus one ear, but other than that we don't necessarily see it as more than just two individual fit hearing aids. In other words, if you put the thresholds in one ear and the thresholds in on the other ear and you fit a set of hearing aids, you're not going to get major changes in the fitting, because you're fitting two hearing aids compared to one hearing aid.
When people hear, they have inputs coming from two different sides of their auditory system, but in almost all cases they hear one single unified sound. That's our goal of the hearing aid fitting: to create that single unified sound. This is usually easy to achieve in symmetrical hearing loss. However, with asymmetrical hearing loss, when we try to create that single unified sound with two different ears operating asymmetrically, some of those assumptions will start to change a little bit. We'll dig into asymmetrical hearing loss in part three of this series.
Assumptions Can Lead Us Astray
Next, I want to share an example of how these assumptions can lead us astray. Figure 8 includes a real-ear response of a patient that I fit a while ago. The patient was the subject of some research I was conducting at the time. He was a staff physician at a university hospital and had very high demands on his hearing. The fact that the hearing aid rolls off after about 2K is due to the quality of the hearing aids that we had to work with back in 1989. If that patient was fit today, that frequency response would go out another octave or so in the hearing aid. Looking at that insertion gain, what sort of audiogram do you think would this patient have? I'm asking you to work backwards. If you're providing up to 15 to 20 dB of insertion gain at about 1000 Hz and above, what do you think the patient's audiogram would look like?
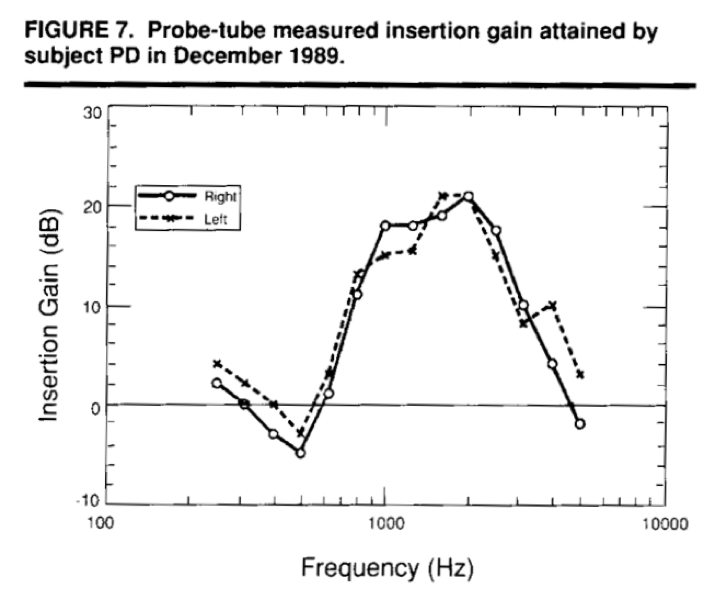
Figure 7. Probe-tube measured insertion gain, research subject.
You probably would not have guessed that the patient's audiogram would look like the one in Figure 8. This is a patient with a rising audiogram: a genetically-related, moderate hearing loss in low frequencies rising to normal hearing at 2000 Hz and above. After a lot of experimentation in the research project that we were running at the time, that patient chose a response that emphasized the amplifying speech signals up in the region where his hearing was near normal or normal. That is a very odd response, but an interesting response to think about when we're trying to decide what's going on in this person's auditory system.
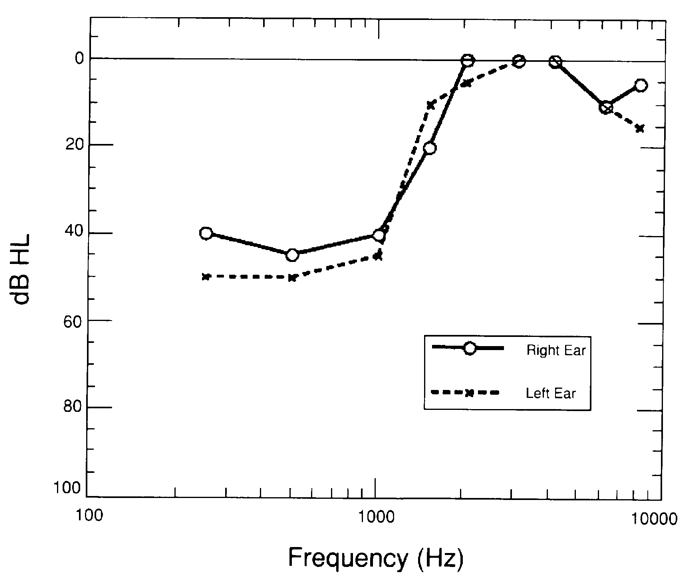
Figure 8. Audiogram, research subject.
One analogy we can use to compare to this situation is to think about pirates with peg legs. Peg legs were fit in a very simple way: cut a piece of wood equal to the length of leg that the pirate lost and then put it on the pirate. Modern prosthetic devices are not fit this way. The length of the prosthesis must match so the patient can stand upright, but it's far more complex than that. Modern prosthetic devices are fit under the assumption that the patient has remaining physiology that can be tapped into. If a patient loses their leg, for example, they have some remaining bone structure and muscular structure and neural intervention that can be taken advantage of, in order to try to get a functionally optimal solution for the patient. This way of thinking should also be used when we fit hearing aids. It's a concept that I like to call "residual capabilities": the aided signal should be viewed in relation to the remaining auditory abilities of the patient. The patient's hearing has been changed and we can't do anything to restore the thresholds to normal. What we can do is use the remaining physiology that the patient has to the greatest degree possible.
Think of it this way. We know what inner hair cells look like when they're normal and we know what they look like when they're damaged. What do inner hair cells look like when we put a hearing aid on a patient? They look the same as when they didn't wear the hearing aid. My point is that disordered hearing is disordered hearing. When we put hearing aids on patients, we're not restoring their hearing to normal: we are trying to restore their function towards normal, but we don't change their hearing. The hearing that the patient has when they enter the process is the same when we change the process. What we do is try to manipulate sound in order for it to be used optimally with the remaining hearing that the patient has. The hearing is gone, the thresholds are gone, that's not coming back. It's a disordered auditory system and it's always going to be disordered. Our goal is to understand how good the remaining hearing is, and how we can create a response in a hearing aid that makes the best use of the remaining hearing that the patient has.
Models of Intervention
The assumptions I have described naturally lead us to the hearing loss correction model. In other words, we compensate for hearing threshold loss by the way we prescribe gain to patients with hearing loss. I'm suggesting that one of the ways we can think about hearing aid fittings, especially those that are more complex, is to view the aided signal in relation to the patient's remaining auditory abilities. That's the residual capabilities model. In other words, we're not fitting hearing loss; we're fitting remaining hearing. Our goal is to try to make best use of the remaining hearing that the patient has.
Two keys to fitting amplification using the residual capabilities model are:
- How can the patient use the remaining hearing that they have?
- What are they using their hearing to do?
In other words, they want to use their hearing to hear and understand speech. In part two of this series, I'll go back to that case of the staff physician who is using a response in a hearing aid that looked very different than you may have predicted, based on the patient's audiogram. That patient is using his hearing in order to hear the most important parts of speech in the part of his auditory system that works the best. His case taught me about residual capabilities. By watching what he did with his hearing, it was a watershed moment in my life as an audiologist. It was then that I understood that I'm not fitting someone's hearing loss; I'm fitting their hearing, and the patient needs to be able to use the hearing to the greatest degree possible.
Summary and Conclusion
After everything we have covered today, if you refer back to the graphic in Figure 1, it should start to look very different for you. You should now be able to see a space and recognize that it's the patient's remaining hearing. You should also be thinking about what you can do to manipulate sound to make sure that the patient gets the best use out of that remaining hearing. In the typical fitting, that space is pretty easy to use as we see fit. However, when we move into some of these complex cases it becomes trickier, because the remaining hearing may not be as good as we would like it to be. As such, we have to start modifying our approaches. I call this modification approach Exception Discovery. It is consistent with a quote from the Supreme Court Justice Oliver Wendell Holmes: "Young men know the rules. Old men know the exceptions." For a standard fitting, the typical rules work fine and we don't have to think about them too much. The idea with exception discovery is that we need be aware of when exceptions are going to occur. What are the conditions that would make us stop for a moment and realize that the typical procedures might not make sense? When we are fitting the hearing aid, we need to be aware of when we might need to start changing. That's the concept of exception discovery: using the standard rules to be efficient with our time, our energy, and our approaches, while at the same time being cognizant of situations where we might need to take a step back and approach the fitting differently. Exception discovery is what fitting complex cases is all about. As we move into part two and part three of this series, I'll cover specific cases and situations in which exception discovery and the idea of residual capabilities will start to come into play. Thank you for your time and attention.
References
van Buuren, R.A., Festen, J.M. and Plomp, R. (1995). Evaluation of a wide range of amplitude-frequency responses for the hearing impaired. Journal of Speech and Hearing Research, 38(1), 211-21.
Citation
Schum, D. (2017, December). Complex versus standard fittings: Part 1. AudiologyOnline, Article 21662. Retrieved from www.audiologyonline.com

