
Editor’s Note: This text-based course is a transcript of a live seminar. Please download supplemental course materials.
Hello, my name is Mona Dworsack-Dodge, and I am an audiologist for Otometrics in Denmark. I am a part of the research and development team. In the process of developing the new AURICAL fitting system, we have run in to a lot of questions about how different parameters impact the results of the fittings that you can get for the different fitting prescriptions that are available. I found myself having to consider a lot of things that I had not considered since graduate school. I thought I would recap some of the particular challenges and parameters that have raised questions. The title of this talk is not meant to be provocative in any way; rather it is to remind us that there can be challenges, and we want to try to clarify those as much as we can.
My background is as a pediatric audiologist, particularly in the areas of newborn hearing screening, infant diagnostics and follow-up. I have been back and forth between the manufacturing side and the clinical side now for the last few years. Five years ago, I came to Otometrics to work on the project related to implementing the new AURICAL system. Now let's get into the presentation.
NAL and DSL Targets
All NAL (National Acoustic Laboratories) and DSL (Desired Sensation Level) targets are not created equally. First, let's consider what these prescriptions have in common. They are, of course, both evidence-based practice prescriptions. There is a lot of literature and research validating them as tools for best practice. Both of them use speech-like signals, or speech as the stimulus of choice for verification. You can obtain different targets for soft, average and loud inputs. That is important for some of the recent advances in hearing instrumentation, and a change in trends for using real speech stimuli as opposed to composite signals or pure tones for verification. NAL and DSL both provide a consistent approach for fitting, regardless of the manufacturer that you are using to fit the hearing instrument. They are not dependent on what algorithm is actually used internally by the device or influenced by the make or model at all. Rather, you have a neutral starting point with a lot of validation behind it as a way to set your baseline for fittings.
For NAL-NL (non-linear) 1 and NL2, the premise is essentially loudness equalization. The aim is to equalize the perception of loudness over a specific range of frequencies, rather than having the low frequencies dominate loudness. The other goal is to maximize predicted speech intelligibility while constraining that loudness.
Evolution has seen it change from being a linear approach, NAL and NAL-RP (revised profound), to a compression approach, NAL-NL1 and NL2. The formula has also moved from insertion gain to aided gain, with targets that are geared toward more speech signals, and, with some modifications, can be related well to other target rules. Of course, there is a host of validation and evidence surrounding NAL-NL1. There have been a lot of enhancements based on patient preference and comfort settings (Johnson & Dylan, 2011). There is also a recent 20Q from AudiologyOnline (Johnson, 2012) that is a nice summary of these changes.
The most recent version of DSL is DSL 5.0, and this premise is loudness normalization. The aim is to restore the loudness perception of the hearing-impaired listener to that of the normal-hearing listener at each frequency. Here, the goal is to avoid loudness discomfort while also providing audibility for speech across a wide range of input levels in both quiet and noisy environments, for infants as well as adults. New additions to DSL are having different targets for quiet versus noisy environments, as well as taking into account the age of the listener.
DSL started as a pediatric fitting tool, but it has evolved to include targets for adults as well. Modifications have been made for noise programs so you can set noise and quiet programs to independent targets, which correlate quite well with preferred listening levels. Again, the same Johnson and Dylan (2011) article is referenced in terms of the comparison of the different fitting prescriptions available.
Where Are They Now?
Figure 1 shows an adult target for a sloping hearing loss with a soft input (55 dB), for both the DSL 5 and NAL-NL2. You can see that the middle frequency range is pretty similar for both prescriptions; the deviations are at the extreme ends of the frequency regions. We have come a long way when we see that we can end up with very similar fittings for the two prescriptions.
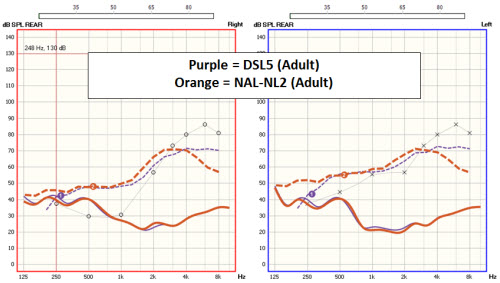
Figure 1. DSL 5.0 (purple) and NAL-NL2 (orange) fitting target comparisons for a soft input.
Figure 2 is the same hearing loss, but now we are looking at an average input of 65 dB. The blue is DSL, and the green is NAL-NL-2. Again, we end up with very similar prescriptions for the speech frequency range for both DSL or NAL.
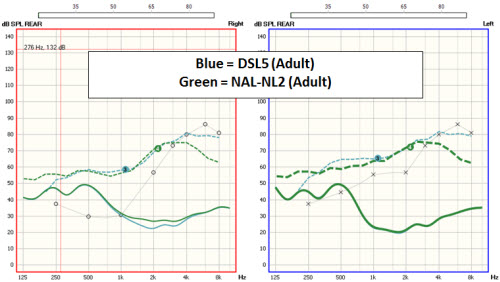
Figure 2. DSL 5.0 (blue) and NAL-NL2 (green) fitting target comparisons for an average input (65 dB).
Just a little bit of orientation about percentile analysis, or what is often referred to as speech mapping. This is the way we are analyzing and trying to fit to prescriptive targets now. You can see in Figure 3 the gray shaded area, which represents the input signal, or the signal that is being presented to the ear, which in this case is a 65 dB signal. The black line in the middle is the long term average speech spectrum (LTASS), and the shaded area represents the “speech banana.” You will also see your 30th percentile and 99th percentile curves. The dashed line represents the target for the LTASS. The peach curve above is the target, with the dashed line being the target for the LTASS, with the lower boundary representing the 30th percentile, and the upper boundary representing the 99th percentile. This view can give you information about how the hearing instrument is amplifying and compressing the signal as it is being passed through the instrument.
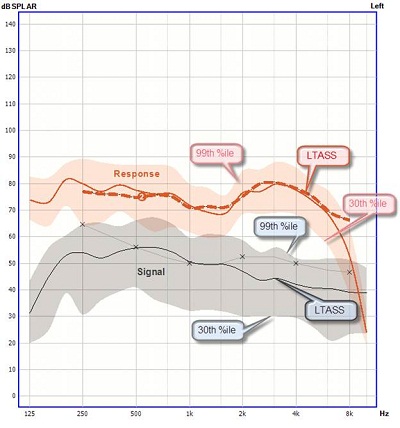
Figure 3. Aided response for average speech (65 dB).
Intersystem Deviations
In 2009, Rickets and Mueller wrote a paper entitled, “Whose NAL-NL Fitting Method are you Using?” This was an investigation into fittings that were achieved using NAL-NL1 across the different probe microphone measurement systems. They discussed five factors that can affect the accuracy of the verification process: target adjustments for the hearing instrument and the fitting type, conversions used to display the hearing loss in targets in ear canal sound pressure level (SPL), the hearing aid’s specific interactions with the measurement signal used, the level and shape of the input signal, and the analysis of the measured signal.
They made some measurements on three different systems and then compared the NAL-NL1 targets for both open and occluded fittings on three verification systems using the system defaults. They randomly selected which system to begin with, so they would choose a system fit to target, and then measure without readjusting on the other two systems. Then they would repeat that cycle with the other two systems as baseline. They then calculated a deviation from the NAL targets for each system. They found that the results on Verifit and MedRX systems were similar, but the Fonix system resulted in a desired fitting that was approximately 3 to 4 dB lower in the low frequencies and up to 8 to 10 dB higher in high frequencies. They wondered why that might be and listed some possibilities.
One of the things that they postulated was an interaction of the hearing aids with the signals that were used. They also concluded that using a speech signal versus a composite signal or non-speech signal might actually yield different results in light of potential interactions with the signal. So they used a different compression setting to see if that influenced anything. In all three cases (Verifit, MedRX and Fonix) you end up with similar results, and so the assumption is that it is not the interaction of the signal itself that is causing the deviation in this case. Of the five factors that Ricketts and Mueller (2009) listed as the possibility for influencing the verification process, we will focus today on target adjustments for the hearing instrument and fitting type.
NAL
Let’s look at NAL first. NAL-NL2, as it was created, actually has only two mandatory inputs for generating a new target: air conduction thresholds at 500 Hz and 2,000 Hz. However, when you look at the test application, there are five input screens, which means that there are many more parameters than 500 and 2,000 Hz threshold values.
Before I move on I want to comment that one of the new additions is gender, which NL2 now makes adjustments for. Through their research, the designers at NAL found that female patients tended to prefer on average about 2 dB less gain than male patients. So they have incorporated an adjustment for gender into the algorithm. They have also incorporated changes for experienced versus new users, and you will see that reflected in the targets. New users tend to prefer less gain than experienced users. They have also introduced an influence for tonal languages. The low frequencies are of importance because you get the fundamental frequency information for tonal languages, which have more low-frequency emphasis.
There is also the audiological input screen where you can choose the transducer type, which is important at the time the audiogram was measured. There is also a place to input the coupling method used for the hearing instrument itself. There are real-ear-to-coupler difference (RECD) selections, with RECD for thresholds as well as for hearing aids. The real-ear unaided response (REUR) and the real-ear dial difference (REDD) are what are used for HL to SPL conversion; we will come back to that in a short while.
You will have a selection screen where you can choose the hearing instrument type, venting, et cetera. Finally, we have a target screen with several possibilities to generate targets for the coupler, for the ear, for ear simulator gain, speech insertion gain, aided gain, et cetera. There are a lot of possibilities for generating targets. The reason for talking about all these selections is to say that someone has to make decisions about the parameters that are used to generate a target regardless of the fitting prescription that you have chosen to use. In some cases that may be you as the user, and in some cases it may be the developer of the verification system, depending on what choices are made available to you in that system.
There are a lot of questions that come up about specific parameters and the influence that they may have on targets. A very common question that comes up is, “Why does venting not appear to influence real-ear SPL targets?” When I asked Harvey Dillon that very question, he referred me to an NAL-NL2 implementation graph. On the left side of the graph, there is RECD for the assessment side. That is related to the measurement of the audiogram itself. Then on the right side there is RECD for the hearing aid or the fitting. Connected to that RECD is the venting, and that venting will actually influence the RECD that is used in that case, and, as a result, will have an impact on the coupler gain that is prescribed.
If you are using coupler gain measurements, meaning that you do your fittings in the coupler, you will see an impact of the vent. However, if you are making probe microphone measurements and generating a target on the ear, then there is not an influence of the vent. If that does not make sense to you, there is a brief article in The Hearing Journal where Harvey Dillon (2006) said venting should not change the ear canal SPL when a fitting has been made optimal for a person at any frequency. Suddenly a light bulb went off. It makes sense that you would not want to make an adjustment to the SPL that is desirable for a client when you are measuring it in their own ear. You can actually see that in play if you look at the test application and look at the targets that are generated for 2cc coupler gain versus real-ear aided gain (REAG). In Figure 4 you can see targets on the left for a 2cc coupler and targets for REAG on the right. This is for a closed vent. Below it, you can see the same targets but now for an open vent. You can see that there has been an adjustment to the target on the 2cc coupler side as compared to the real ear aided gain side where there is no adjustment made.
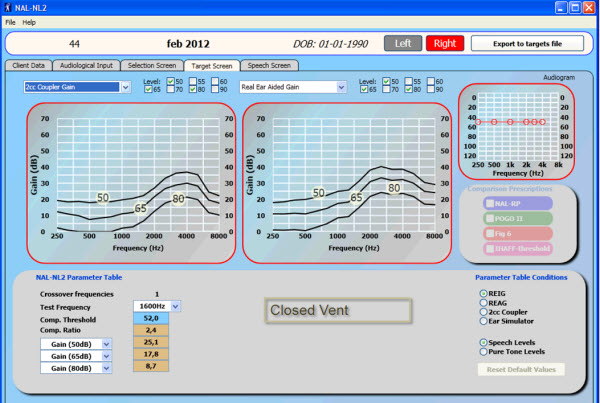
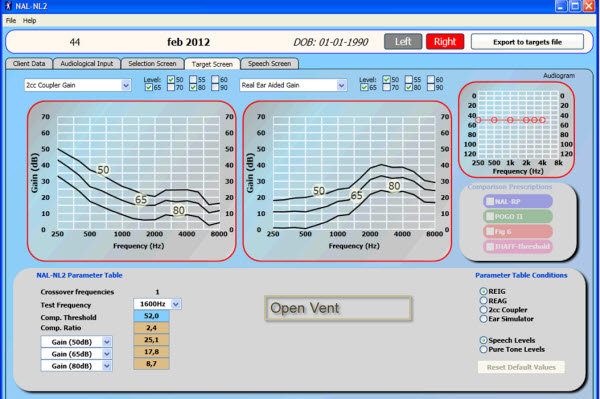
Figure 4. Targets for 2cc coupler gain (left panel) compared to real ear aided gain (right side) in closed vent (top) and open vent (bottom)conditions.
The reason that we make the adjustment on the coupler side is that we cannot recreate the conditions where the sound is leaking out at the ear. In the implementation documentation for how to implement the NL2 algorithm in to a fitting software or verification system, they provide a list of the various parameters and where they will have an impact. Venting is something that will only have an impact in this case on the 2cc coupler gain, but will not have an impact on the insertion gain or the aided gain.
General audiometry parameters and things like age and gender will impact all three targets: the insertion gain, the aided gain, and the coupler gain targets. But things that influence the predictions of RECD and REDD, such as tubing and venting the insertion depth of the hearing instrument and the hearing instrument type, will have an impact only on the coupler gain and not on either insertion gain or aided gain.
There are a range of options available on various verification systems. Even though there are only two basic parameters that are required, there are many selections to be made. Either those selections are made for you, or you make them yourself. The idea of one system (Verifit) is certainly ease of use, or to minimize the number of selections the user has to make. One can assume that the other choices that are not available on the screen have been set to a default recommended by the NAL-NL2 algorithm itself. You have very basic audiometric entries and a few details to be able to enter here.
The opposite end of the spectrum is that the clinician should be allowed to enter in and have control over any parameter that might influence the target itself. This particular system (Fonix) has a lot of detail on the basics screen, and then an advanced screen with even more detail. It tries to encompass almost everything that is incorporated in the NAL-NL2 test application itself. This is obviously going to be good in the case of researchers or people who are interested in a lot of the fine details and who are able to make judgments about the various parameters changes.
Then there are systems that are somewhere in between. You might have a very basic screen and then a more detailed, advanced screen. We will focus mainly on the OtoSuite, which is the system that I am most familiar with, of course. For our OtoSuite, we have common settings that we think people might be interested in changing on a routine basis, although you are given the choice to show and make these selections for every client or not. If you do not show it for every client, then the system assumes all defaults recommended by the NL2 algorithm. We also include advanced settings so that you can provide more fine detail than you could if you just relied on the basic settings.
Conversion Factors
Conversion factors are important to discuss because this is one of the main sources of variation amongst systems, especially when you are making comparisons in terms of output as opposed to gain. If we look at NAL specifically and the potential sources of inter-system variance, the defaults that are assumed by each system may vary. As I mentioned to you before, there are lots of options. If you are not able to make those choices, then the system has obviously made them for you. We can hope that each system is using the kind of default recommended values from the fitting prescriptions algorithm itself, but you may never know that. The transducer’s selection may not actually be aligned. That is important as it relates to the HL to SPL conversion; it is dependent on the transducer that is used. The HL to SPL conversions rely on RECD values or real ear unaided gain (REUG) values, depending on the transducer used in order to drive the REDD. It is not common practice for people to measure REDD, so we estimate that utilizing either RECD or REUG.
If we look at the REDD for a headphone, basically this is just a quick procedure that was described by Rickets and Mueller (2009) to see what the REDD is or the conversion value that is being used to get from HL to SPL on your system. Enter in a flat 50 dB HL hearing loss, and then go to the screen where you can see SPL and calculate the difference between the thresholds. In the case of a flat 50 dB hearing loss, the REDD for a headphone at 250 Hz is 27, at 1,000 Hz is 8, and at 4,000 Hz is 12 dB.
How did we get there? In the OtoSuite for the AURICAL system, basically the transducer selection will guide whether we use the RECD or REUG, and any parameter that impacts their calculation will influence the HL to SPL conversion. We have three formulas that we use for HL to SPL in the real ear. For insert phones, the threshold in SPL is calculated as the HL threshold plus RECD plus the insert phone reference equivalent threshold sound pressure level (RETSPL) for either an HA1 or an HA2 coupler. It is an important designation as to whether or not it is an in-the-ear (ITE) or behind-the-ear coupling in order to get the correct RETSPL value to be used.
For sound field, the SPL threshold is the HL threshold plus REUG, and of course the correct orientation of 0, 45 or 90 degrees azimuth plus the sound field RETSPL again for 0, 45, or 90 degrees. For headphones, that threshold is the equivalent of HL plus the real ear-to-6cc standard transform plus the RETSPL for headphones. To get back to HL from SPL, apply those formulas in reverse. In order to get from SPL real ear to SPL 2cc we simply subtract the applied RECD from the real ear SPL threshold.
Signals and Targets
Signals and targets can be another potential source of variation when you are comparing measurements and fittings across systems. First off, NAL does not actually provide real ear aided response (REAR) or SPL targets. That is, they do not provide output targets. They provide aided gain, insertion gain and coupler targets, but the output targets are not available. What that means is that systems which want to do dynamic fitting or speech mapping where we look at the percentile curves, the targets need to be converted to be used in that way. That is derived by adding the aided gain to the input signal that is used, and it ends up providing a customized REAR or coupler SPL target. Those may differ among systems depending on how they do the calculations. In the OtoSuite, we actually customize the targets a bit further by applying the known signal spectrum for the chosen signal so that we can actually achieve appropriate targets depending on the signal that has been used.
Figure 5 is the speech banana for a 65 dB average International Speech Test Signal (ISTS). We take that input signal and we add it to the aided gain generated by the NAL-NL2 algorithm. By adding those two, we end up with an aided response target (Figure 6). Then we are able to make measurements looking at the percentile curves. That gives us extra data for looking at compression and other useful pieces of information that we might not be able to get when we are looking at aided or insertion gain. We can take that a little bit further, and since we know the input spectrum for various signals that are being used, we can then apply those spectra to the aided gain target and get customized targets for the individual signals.
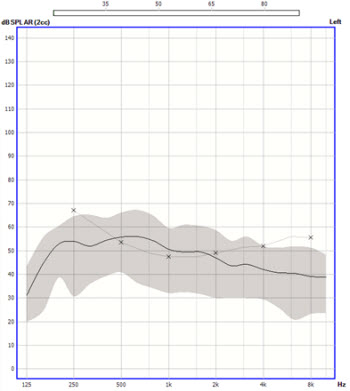
Figure 5. Speech banana for a 65 dB average International Speech Test Signal (purple).
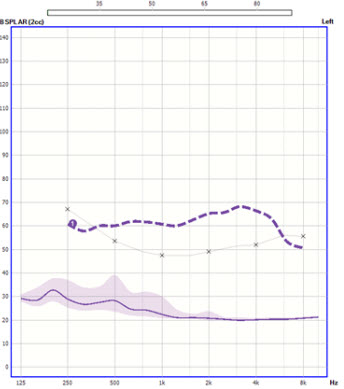
Figure 6. Aided response target generated from an input signal and the aided gain from the NAL-NL2 algorithm.
The ISTS is going to be the signal that is likely to get you closest to the standard speech target for NAL. So, if you are making comparisons across systems, then you probably want to use ISTS or one of the International Collegium for Rehabilitative Audiology (ICRA) signals. Then, depending on whether or not you are interested in high frequencies, you can use things like babble or pink noise and so on.
Another important factor is that making sure that the bilateral versus unilateral settings are aligned. In the case of a bilateral or unilateral fitting, the NAL algorithm will implement a correction of anywhere between 2 and 6 dB, depending on the degree of hearing loss. If you have it set up as bilateral/unilateral in one system and not in the other, that could result in a fairly significant difference in the targets and fitting that you see as a result.
The experience settings might not be aligned. As I mentioned before, NAL has introduced an experience setting based on the fact that experienced users tend to prefer more amplification than new users. If that setting is not aligned, then you will end up with some degree of difference between the targets and the fittings. This relates more when you are comparing between the hearing instrument fitting software. There have been plenty of papers and presentations about the fact that there is a lot of variability amongst first fit and initial fittings from the various fitting softwares. Hawkins and Cook (2003) attribute some of that to the proprietary coupler response for flat insertion gain (CORFIG) values that are used by the various hearing instrument manufacturers, which may result in different targets.
DSL
There are a few more required entries for DSL than NAL. The list of actual required entries that were to be implemented by makers of verification systems is shown in Figure 7. We are required to make it possible for you enter all of these particular parameters. Again, DSL provides its own test application, which you can obtain by contacting the University of Western Ontario if you are interested in making some comparisons in your system from the pure implementation.

Figure 7. Required inputs for DSL v5.0.
There are not as many screens; there are only two, but there are still quite a few parameters. Again, you have things like the client’s age, the client type, compression, thresholds, RECD, REDD, et cetera. You can generate targets for insertion gain, aided gain and output, and coupler responses.
We answered the question earlier about venting for NAL, but what about for DSL? I think you will not be surprised to find out that there is no difference between open vent and occluded vent conditions. However, for the coupler SPL targets, there are significantly higher target values for the open vent as compared to the occluded fitting. Again, that is because we are trying to accommodate for the fact that we cannot recreate the conditions in the ear, so we need to compensate for the sound that is lost in that case.
Another question that comes up quite often is, “What about hearing instrument type? Why does the hearing instrument type not appear to influence things when I expect it to?” In the DSL test application, we can make a comparison between ITE and BTE for REAR targets versus coupler SPL targets. Again, when we are comparing the REAR targets, they are the same regardless of ITE and BTE. But in the case of the coupler target, you end up with a difference in the high frequencies.
In order to recreate or simulate the conditions in the coupler that are on the ear, we have to find some way to accommodate for microphone location effects depending on the style of hearing instrument that is worn. That will have the most impact in the high frequencies, but you do not need to compensate for the different locations on the ear when you are making the aided response measurements, because you actually can measure where those responses are with the microphone in the location that it is actually being used in.
Again, there is a range of options on probe microphone measurement (PMM) systems from very simple to very detailed. The OtoSuite, again, is the middle of the road with both basic and advanced settings.
Intersystem Variance
Similar to NAL, the defaults assumed by each system may vary. There are several parameters to be chosen, and if those parameters are not available to you as a user, you have to rely on what default values are set for that system you are using. The HL to SPL conversions for each system might vary a little.
Now, NAL does not consider Uncomfortable Loudness Levels (UCL), but DSL does make some adjustment for UCLs. In this case, it is important to make sure that the UCL that is used when comparing systems is equivalent. The transducer selection might be aligned; we talked earlier about why the transducer selection was important as it related to the HL to SPL conversion. Again, the bilateral and unilateral settings might not be aligned. Experience settings might not be aligned. This is really a misnomer because DSL does not have direct experience settings. DSL handles adult and pediatric fittings, so you do have to indicate whether the client is adult or pediatric. Generally speaking, the adult fitting is meant to correspond to acquired, late-onset hearing loss versus the pediatric fitting which is meant for early-onset or congenital hearing loss. What is sometimes seen in the clinic is that a child who has been fit with a DSL all their life will actually prefer the child target when they become an adult over the adult target. So, there is not a direct experience setting in the DSL algorithm, however, there is some influence based on whether or not it is in a child or adult.
Quiet versus noise targets might not be aligned. DSL provides targets for the different noise programs, so if you have it set up for a noise target in one system and a quiet target in another system, you could end up with a misalignment in the targets. Again, those CORFIG values could not match. In the case of DSL, output targets are provided, but those targets are actually varied by signal type so they categorize them in to speech, speech noise or pure tone. Depending on how the verification system classifies the signal, it may fall in to one category or another, so you could end up with a different target if the same signal is classified as speech noise on one system but as speech on another system. That could influence and make a difference.
Furthermore, DSL provides the possibility for you to customize targets using the signal spectrum if it is provided to the algorithm. In the case of OtoSuite, in the same way that we derive the response target for NAL, we apply the signal spectrum to the response target that is generated by the DSL algorithm in order to get a custom target.
Differences between Fitting and Verification Software
The primary source of deviation between the fitting and verification software is similar to what we see when comparing across systems. One of the first things to consider is a mismatch of understanding between what it means to actually fit to a prescriptive target versus selecting that prescription as an applied algorithm. What I mean by that is that when we implement an algorithm into a hearing instrument, it is applied based on average 2cc coupler values. We hope that what is measured at the client’s ear will be close to what we expect from the target, but it is based on average 2cc values, and there are variances, such as the CORFIG values that I mentioned before. So that is why it is very important to measure every individual ear. It is important to understand the distinction between using the DSL or the NAL algorithm to get things set up and pre-programmed, and the individual ear variances that might impact what is actually arriving at the client’s ear drum.
Mismatched signal types are something that I see quite often when folks are comparing fitting software with a verification system. Most verification systems default to a speech or speech-like signal. The OtoSuite, by default, uses the ISTS, but there are other speech signals like the Rainbow Passage and live signals that can be used. But some of the fitting software settings are based on pure-tone sweep measurements or a constant-level input will be higher than that of a broadband signal where you add up the overall energy to achieve the same root mean square (RMS). If you ended up using a pure-tone signal in the fitting software and a speech signal in the verification system or vice versa, you could end up with significantly different targets.
There also is a possibility of mismatched versions of prescriptive targets. DSL m[i/o] is very often how the DSL implementation is referred to in the various fitting software programs, and in some cases that refers specifically to DSL version 4.1 or 2. Then they will make a specific distinction that DSL v5.0 is a separate entry. Whereas on some systems you might see DSL m[i/o] referred to the DSL approach, and it could be the most recent version which is DSL v5.0, or not. You want to make sure that what you are using on your verification system matches with what you are using on your fitting software. If you are using DSL 4 in the fitting software and DSL 5 in the verification system, then you will end up with a significant mismatch in the targets.
There may also be a mismatch in the use of predicted versus measured REUG or RECD. Most fitting software programs allow you to import the REUG or RECD that was measured on the verification system. In some cases when there is some hardware integration, you can measure directly from the fitting system itself. When possible, it makes sense to do that, because the verification system is likely to use the measured values as opposed to the predicted values. So if you have one system using predicted values and one system using measured values, you could end up with a significant mismatch because predicted values are based on averages for a specific age range. Average is average which means that an individual ear can vary from that average significantly.
Again, there could be a mismatch between the binaural and monaural fitting selections in the verification software as opposed to the fitting software. It is important to check that in the case of NAL, as I mentioned before, because it can vary anywhere from 2 to 6 dB. In the case of DSL, a 3-dB reduction is applied across input levels when there is a binaural fitting. Furthermore, a mismatch can occur between adult and pediatric client types or experienced versus new client types. Those will impact targets depending on how you have it set in the verification system versus the fitting software, so just make sure that those are aligned if you can.
What Can I do About Potential Variations?
First, familiarize yourself with the prescription that you are applying to your fittings. There are some nice publications that give good overviews of the various prescriptions, and that makes it easier for you to have a baseline and know what to expect, especially if you are using a new version and want to know the differences between the versions. For information on the evolution from NAL-NL1 to NL2, you can find a nice overview from Gitte Keidser and colleagues (2011). Susan Scollie and her colleagues in Canada (2005) published a nice article about DSL v5.0 as well. More recently, Johnson and Dillon (2011) did a comparison across various prescriptive methods of insertion gain, predicted loudness, frequency bandwidth and speech intelligibility. They not only looked at DSL and NAL the latest versions, but they also looked at NL1 and the Cambridge approach as well. As I mentioned before, Earl Johnson (2012) also has a 20Q article here on AudiologyOnline focusing primarily on DSL 5.0 and NAL-NL2.
Check the settings in your probe microphone system and your fitting software to see if there is a mismatch. If you see something that does not make sense to you, check all the parameters that you can to see if something is off. Sometimes on the fitting software you have to look in a couple of different places to find the settings, but do take the time to do that, because often there is a simple explanation for why you see that variation.
Of course, consult the reference manuals and clinical support material. Most hearing instrument and verification system manufacturers are constantly putting on courses and publishing white papers, making it possible for you to use these tools more easily now than in the past. In the case of Otometrics’ AURICAL, we have a wesite, futurefitting.com, where you can go and see various videos to support different parts of the process, as well as some of the references and white papers that supporting fitting and verification using AURICAL.
I appreciate your attention today. I hope that this has been a beneficial course for you. Please feel free to contact me at Otometrics if you have any questions.
References
Dillon, H. (2006). What’s new from the NAL in hearing aid prescriptions? The Hearing Journal, 10, 10-16.
Hawkins, D., & Cook, J. (2003). Hearing aid software predictive gain values: how accurate are they? The Hearing Journal, 56(7), 26-34.
Johnson, E. (2012, 9 April). 20Q: Same or different- comparing the latest NAL and DSL prescriptive targets. AudiologyOnline, Article 20289. Retrieved from https://www.audiologyonline.com/audiology-ceus/course/20q-same-or-different-comparing-20289
Johnson, E., & Dillon, H. (2011). A comparison of gain for adults from generic hearing aid prescriptive methods: Impacts on predicted loudness, frequency bandwidth, and speech intelligibility. Journal of the American Academy of Audiology, 22, 441-459.
Keidser, G., Dillon, H., Flax, M., Ching, T., & Brewer, S. (2011). The NAL-NL2 prescription procedure. Audiology Research, 1(24), 88-90.
Ricketts, T. A., & Mueller, H. G. (2009). Whose NAL-NL fitting method are you using? The Hearing Journal, 62(8), 10, 12, 14, 16-17.
Scollie, S., Seewald, R., Cornelisse, L., Moodie, S., Bagatto, M., Laurnagaray, D., Beaulac, S., & Pumford, J. (2005). The Desired Sensation Level Multistage Input/Output algorithm. Trends in Amplification, 9(4), 159-97.
Cite this content as:
Dworsack-Dodge, M. (2013, January). The Devil is in the fitting details. AudiologyOnline, Article #11566. Retrieved from https://www.audiologyonline.com.

