
Editor's note: This is a transcript of the live expert e-seminar. To view the course recording, please register here
Today I want to discuss a signal that we as audiologists spend a lot of time talking about but, in certain ways, probably do not understand quite as much about it as we should, speech. We know that speech is the primary signal that patients are interested in hearing effectively, and we create many technologies designed to process the speech signal. But understanding the detailed nature of the speech signal, or the dynamics, is important as we consider the different types of modern hearing aid technology and its effect on that signal.
What is speech?
Speech originates in the human body and, more specifically, is a reflection of movement within the human body. You produce speech by blowing air out of your lungs, and it resonates through your oral cavity, pharyngeal cavity and nasal cavity. Changes in those cavities create the sounds of speech that we are used to hearing. Speech is the acoustic reflection of movement. It is the evidence that the person producing the speech was moving the articulators of the mouth, the jaw, tongue, and soft palate, in order to create different sounds to communicate information.
Today I want to talk about the acoustic nature of movement. Sound changes as movement changes - which, for us specifically, mean a change in our body. As the position and shape of our body and mouth changes over time, so does the sound the listener is hearing. When you listen to speech at a conscious level, you are paying attention to the meaning of the signal through words and letters. You are not all that sensitive to phonemes themselves. At a level below your conscious awareness, however, your cognitive system is precisely aware of the way that you are changing your body to create those sounds. If you go back and look at some of the primary speech science literature, there were different discussions about how humans perceive speech. One of the schools of thought was the motor theory of speech perception. The idea was that you recognized the sounds of speech based on the sort of movements you would need to make to produce that sound. In other words, you do not decode the sound directly, but rather the sound is mapped on to whatever sort of movements would be necessary to create that sound. Now, not everybody in the speech science world buys into the motor theory of speech perception, but the general point is that speech is not some abstract thing. It is something that is created by the movement of the body.
As audiologists, we tend to talk about just two dimensions of the speech signal: frequency and amplitude. When we go about correcting for hearing loss, for example, we specifically look for how much gain to apply to the speech signal for different input levels and frequency regions to make it more audible to the patient. In the field of speech perception, hearing loss, and hearing aids much of our discussion is related to the articulation index or the speech intelligibility index (SII). Information in the speech signal falls differently across the spectrum, and we use the SII as a measure of how much of that information is audible above the patient's threshold. Figure 1 is a representation of speech importance as it is broken down into phonemic classes by frequency region. Each of those classes of sound are produced in radically different ways based on movement patterns of the head; in other words, a plosive is different than a vowel or a glide or a nasal sound. Different patterns carry different information. The dynamic properties of a stop are different than the dynamic properties of an affricate even though they may be created at the very same place in the mouth. It is just how the tongue interacts with the alveolar ridge and that will tell you the difference between a /t/ and a /s/. So talking about speech only in terms of frequency and amplitude does not fully capture everything that you need to know about the speech signal.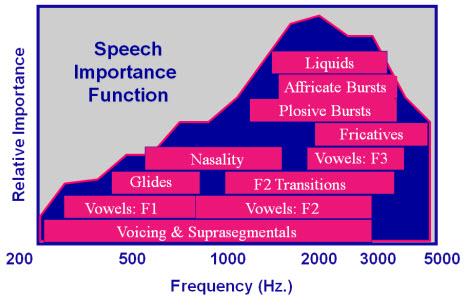
Figure 1. Speech importance across the frequency spectrum; note more relative importance in the higher-frequency regions.
This is important because hearing aids do more than just amplify sounds in different frequency regions. The amplification applied in different frequency regions changes with input over time. What this lecture is all about today is how the timing parameters of hearing aids potentially interact with the timing parameters of speech signals. If speech is a reflection of movement of the articulators and you are passing that through a technical system (i.e. the hearing aids) that is changing the response to sound continually based on input level, then you have two moving parts. The speech is changing over time. The reaction of the hearing aid is changing over time. The simple reality is that those two timing windows tend to be very similar. The attack and release times in hearing aids are of similar magnitude to the dynamic changes that occur in speech signals. That is one thing for which most audiologists do not have a good appreciation: the fact that you are trying to create a system to correct for a moving target using the same sort of timing windows in the device as in the changing signal.
Hearing Movement
I want you to say the word "slip knot" out loud to yourself. Go ahead. It probably took you half a second or so, depending on how quickly you talk. Now what I want you to think about is the number of discrete movements that you used to produce the word "slip knot." Your tongue probably starts in a neutral position. Then you raise the tip up to your alveolar ridge to create the /s/ sound, and you start pushing air through your mouth to get out that narrow groove at the tip of your tongue to create the /s/. At the same time, you start to drop the body of your tongue to move into the /l/ position. You move from the /s/ position with the tip of the tongue up, and you have to release that tongue tip relatively quickly for your tongue to take the body position for the /l/, which quickly transfers into another tongue position for the /i/ sound in "slip." You create a certain amount of steady-state time when you are producing the /i/ vowel in "slip," and at the same time you are starting to close your lips to produce the /p/ sound. Then you have to move into the /n/ sound for "knot," so at the same time you are holding your lips together for the /p/ you start to put the tongue in position to produce the /n/ sound at the beginning of "knot." In most cases, people do not release the stop between the /p/ sound and the /n/ sound. At the same time you are starting to drop your soft palate. All of those things are happening at the same time. Then you have to go into the tongue position for the /ah/ sound in "knot," and back up to a stop- closed position with the tongue on the alveolar ridge for the final /t/. Within that half of a second, you are making a dozen discrete movements with the articulators in your mouth. All of those movements were necessary in order for you to create that sound so that it would be interpretable by the listener. This is just a small indication of just how quickly you move things in your mouth and how sensitive you are to those positions.
You have been listening to my voice now for ten minutes now. You may notice something about the sound of my voice. If you were really good in phonetics as an undergraduate you probably realize I have a lateralized /s/. In other words, I do not put the tip of my tongue at my alveolar ridge with a groove right down the center of it and blow air out of the center of my tongue, but rather I flatten my tongue against my alveolar ridge and press the sound out of the side of my tongue. I have relatively atypical speech production or movement pattern when I produce a /s/. I was never able to correct it. I know it sounds a little sloppy, but it is one of the things that defines the sound of my voice. The reason I bring it up is that although you may not have been able to identify the lateralized /s/, you were probably able, at some level of your conscious awareness, to identify that it did not sound quite right.
Think about watching a movie like Avatar or a video game in which they are using realistic drawings of humans. One of the things that they have never been able to get right is making the movement look normal. Programmers do many different things to try to make the human movements like walking or running look as natural as possible, but it never looks quite right. There is something about the way the people move. The human observer is very sensitive to movement patterns and what looks and sounds normal and what does not. When someone produces speech in a manner differently than you would expect, you are sensitive to those changes. Let's take a look at this in a little greater detail.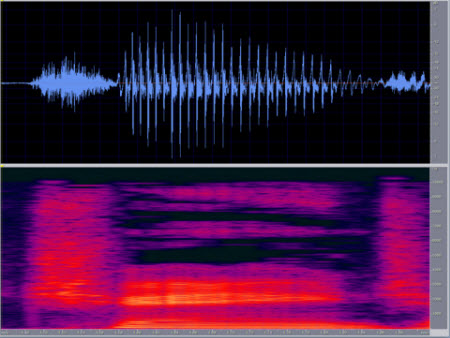
Figure 2. Vocal energy for the word "change" as pictured on a spectrogram.
Figure 2 is a spectrogram of my production of the word "change." Let's take a look at some of the specific movements that show up in the waveform. You start off with a closure phase of the /ch/ affricate, and then you go into the fricative part of the sound and that defines a /ch/ sound as different from a /sh/ sound. If you move on, you notice an increase in intensity over time during the affricative part of the sound because the mouth is getting more open. You close it down pretty tightly for the stop portion of the affricate but then you open it over time. You see the same vowel energy level in the word "change" as we mentioned in "slip knot," where the vowel is not necessarily a steady-state level. We often talk about vowels coming in under a certain level, but the reality is in normal conversational speech vowels are rarely steady state. Vowels can be steady state, meaning they keep the same amplitude for a steady period of time, when you sing them. But when you speak vowels, usually you do not hold vowels at their steady-state position. In Figure 2, note that the amplitude of the /a/ in "change" increases and then decreases in intensity. It does that because you open your mouth to produce the /a/, then you close your mouth to go into the nasal /n/ sound after you produce the vowel. Then you move into the rising second formant (F2) during /a/ because you start at a lower F2 position (Figure 3). You start rising in F2 position as you move towards the /n/ sound. You then have the nasal murmur that occurs during the /n/. The nasal murmur is a loss of sound in the low to mid-frequency range, resulting in nasality. It is a hole in the spectrum, as they say. You see that hole shows up pretty clearly in the mid to low-frequency region where air is being shunted into the nasal cavity.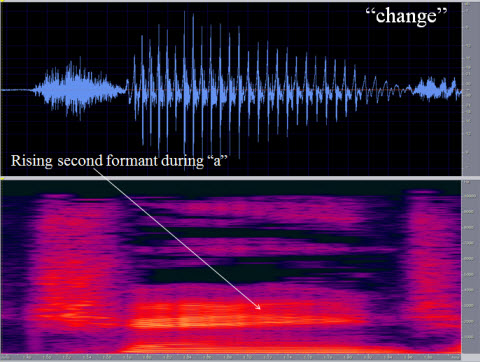
Figure 3. Identification of the rising second formant during the vowel production in the word "change."
The second formant is the most important because it primarily tells you the position of the tongue. It identifies whether there is a high or low contrast to the tongue, and to some degree it tells you a little bit about front and back placement. Many of the phonemes are contrasted by the height of the tongue, such as /i/ versus /o/ for example. The difference between these phonemes is in the second format - a high second formant versus a low second formant. You see the formant structure being carried through to voiced consonants at times, and it reflects the position of the tongue and the mouth. It is a relatively robust acoustic parameter and tells us exactly what phoneme is being produced.
Figure 4 shows the spectral characteristics of the phrase "why chew my shoe." The reason I used "why chew my shoe" is because it has the same diphthong in "why" followed first by the affricate /ch/, and then followed later by the fricative /sh/. Notice the movement pattern is different. Like I said earlier, affricates are typified by a closure phase and then a rapid open phase. You notice how the level of the /ch/ rises very quickly after it is released from the stop phase. You can see that transition from a very closed, low-energy phase to a very rapid increase in energy. You do not see it doing the same thing with /sh/ because /sh/ does not have the closure phase. You get a gradual increase in the energy level over time. That is the only thing that differentiates between /ch/ and /sh/, but it is a big difference.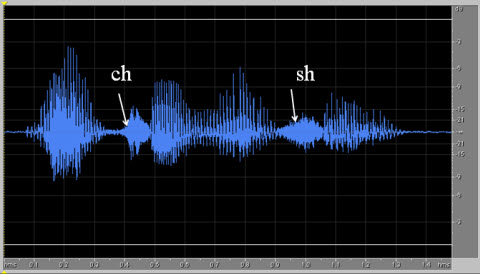
Figure 4. The phrase "why chew my shoe," illustrating the spectral differences between the affricate /ch/ and the fricative /sh/.
I will give you one more example (Figure 5). This shows the difference between the word "ooze" and "ease." Now, ooze starts with /oo/ sound followed by the /z/ fricative. "Ooze" is typified by a low second formant. When you produce /oo/ in your mouth you have the tongue pulled back and down towards the back of the mouth. Then you move from that tongue position to the alveolar position to produce the /z/ sound; the tongue moves a relatively long way in the mouth.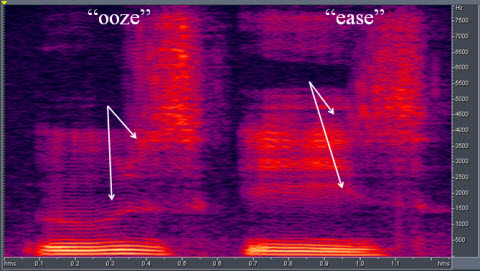
Figure 5. Two words, "ooze" and "ease." White arrows indicate the low second formants followed by the transition time from the initial vowel to the /z/ sound.
What you notice in Figure 5 is the change in the pattern of energy during the /oo/ vowel where the tongue starts to move up to the alveolar position to produce /z/. Try to do that with /ee/. It is a high vowel in the mouth, and to go from the /ee/ to /z/ position is not as far to move. What you see, comparatively, is that movement does not start as early in the /ee/ position as the /oo/. You can keep the steady-state position of the tongue in the /ee/ longer because, in order to produce the /z/, you do not have to move the tongue as far. Again, these are all very subtle but important differentiations in the movement pattern within the mouth to produce the speech sound.
Timing Properties of Conversational Speech
In conversational speech, we produce somewhere between three to five syllables per second. It varies tremendously by talkers, but three to five syllables per second means that you may produce up to ten phonemes per second when you are talking. Within that one-second time period you might have one to two stressed vowels (100 to 200 ms). Unstressed vowels tend to be a little bit shorter at 75 to 150 milliseconds, but it depends on which vowels you are producing. You are also going to produce maybe two to three voiced consonants, which tend to be a little bit longer, perhaps in the range of 50 to 100 milliseconds. Unvoiced consonants are shorter, falling somewhere between 20 and 100 milliseconds. The point is that the average length of a phoneme is approximately 100 milliseconds or so but there are a lot of variables. Vowels typically last longer, up to 200 milliseconds, where some of the consonant sounds may be only 50 milliseconds depending on exactly how they are produced. You can get a general idea of the timing parameters in speech when you see it graphically displayed.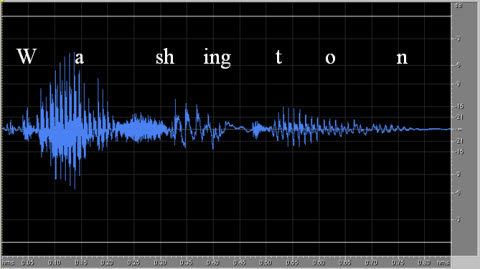
Figure 6. Spectral characteristics of the word "Washington."
Figure 6 shows the word "Washington" as it was produced from my voice. "Washington" is made up of eight phonemes and took me about 800 milliseconds to produce. That was about 100 milliseconds per phoneme, on average. But notice some of the phonemes are longer than others. Note the steady-state /ah/ sound at the beginning of "Washington" is closer to 150 to 200 milliseconds, whereas the closure /t/ sound in Washington is approximately 50 milliseconds. Sometimes it is difficult to tell where one phoneme ends and the other one begins. The last vowel in Washington is an unvoiced, neutral vowel going into the /n/ sound. Because there are two voiced sounds /o/ and /n/ co articulating without a very high tongue position, they mix into each other. These are very minimal examples of how speech sounds interact with each other in a period of time. Now that we know what speech is made up of in terms of timing windows, let's take a look at the way hearing aids respond over time.
Timing Properties of Non-linear Hearing Aids
As you know, non-linear hearing aids are made to change the gain over a period of time, typically in the form of attack and release. The timing parameters of these gain changes are not instantaneous. Some delays are inherently built into the way hearing aids respond to gain changes over time, and it is important to have an appreciation for what those gain changes are. In the case of Figure 7, the signal starts at a low level, rises quickly to a higher level and then drops again to a lower level, and gain of the hearing aid is going to follow that. The gain of the hearing aid is going to drop when the input level rises, and then when the input level drops, the gain of the hearing aid is going to restore itself.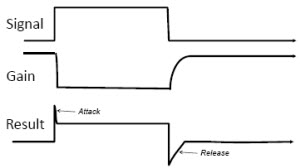
Figure 7. Schematic of attack and release gain with a signal moving quickly from low-intensity input to higher-intensity input.
Notice the attack time, meaning how quickly the hearing aid responds to an increase in signal level. It tends to be relatively short in modern hearing aids compared to the release time, which is the time over which the hearing aid tries to turn the gain back up after the signal level drops. Attack times are reflected in gain changes on the order of maybe 1 to 5 milliseconds, whereas release times can vary quite dramatically from 20 or 30 milliseconds to 2 seconds long.
Modern hearing aids tend to employ fast attack times at 1 to 5 milliseconds. There is much more variability in the release time, however. A standard range might be from 30 to 100 milliseconds, whereas a slower release time is on the order of 200 to maybe 2000 milliseconds. It depends on the manufacturer's amplification philosophy. The choice between a fast or slow release time in a hearing aid is relevant when you consider the timing parameters of speech. Remember I said that the rough average duration of the phoneme is 100 milliseconds, but that the duration may vary from 30 milliseconds to 200 milliseconds or more. The crux of the problem is that you have hearing aids changing in the same time windows that the speech signal is changing, and there can be interesting interactions between them.
Figure 8 illustrates the effects of fast versus slow-action compression on the speech signal. What you see is a cartoon drawing of speech at three different input levels: soft, moderate, and loud. Say this person has a hearing loss and loud speech is audible to them, but moderate and soft speech are not audible. A non-linear hearing aid is designed to take the full range of speech inputs and make them appropriately audible to the listener above threshold.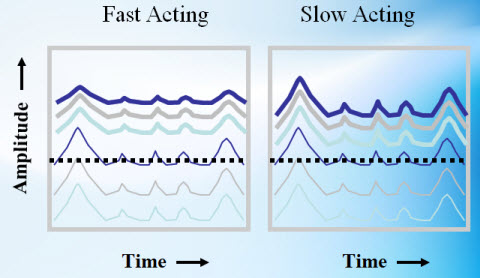
Figure 8. Differences in compression strategies as a function of time and amplitude.
A fast-acting system and slow acting system can be contrasted to each other depending on how they handle the situation. A fast-acting system is designed to change its gain in a very fast time window. An intense vowel sound that occurs, for example, is going to call for a small amount of gain. If this vowel is followed by a soft consonant, the gain will have to increase significantly when the softer consonant comes through to compensate for the differences between the louder vowel sound and the softer consonant. In a fast-acting system, the output peaks are going to be close to each other because the response is fast. It gives more gain for the softer sound as quickly as possible. What ends up happening when you account for soft, moderate and loud speech is that you see a reduction in the total dynamic range, not just short term peak-to-peak differences between phonemes. Everything is reduced in terms of the range of amplitude, including the contrast from one phoneme to the next because the gain of the hearing aid adjusts very, very quickly. Most audiologists assume that this is what is happening with wide-dynamic-range compression in non-linear hearing aids.
Slow-acting compression is considered slow because the release time of the compression is extended, for example maybe one second long. The idea of having a long release time is to make sure that the gain does not change from one phoneme to another. In other words, if there is a natural peak-to-peak difference between a loud vowel and a subsequent soft consonant, this loud vowel will cause a certain gain response to the hearing aid and so that loud vowel is going to be amplified up beyond that level. When that soft consonant comes through, the gain that is applied to the loud vowel is also applied to the soft consonant. What you are trying to do is maintain the peak-to-peak relationship between the vowel and consonant. There is a natural amount of information embedded in the vowel-to-consonant intensity difference. Long release times are used by some manufacturers in hearing aids specifically to preserve these phoneme-to-phoneme differences. Slow release times will make the long term differences between soft, moderate and loud speech reduced so that you can pack more of the long term average of speech within the patient's dynamic range, but it is done in such a way that the peak-to-peak differences between the phonemes are maintained at their natural level.
These differences in slow acting versus fast acting systems have been documented for a number of years, and there are arguments in favor of both. A slow-acting advocate would talk more about maintaining the natural intensity differences between one phoneme to the next. One study suggests how speech information is coded (Hedrick, Schulte, & Jesteadt, 1995). In this study they used a steady-state /ah/ vowel, preceded by a burst of consonant energy in the higher frequencies, /p/ or /t/. Naturally, the burst for a /pah/ is less intense than a burst for a /tah/, just based on the acoustics of speech in normal situations. They took the same acoustic signal, as far as frequency location of the energy, and varied the intensity of the high-frequency burst in relation to the vowel over a 20 dB range. When that burst of energy was kept at a higher intensity level, it sounded more like a /tah/ to the listeners. When that burst was at a lower intensity level, it sounded more like a /pah/ to the listeners. The vowel being was maintained at the same intensity the entire time. This indicates that as the relative level of the consonant burst was changed, the perception of which sound was being produced was also altered. That is because the listener has a reaction between the natural level of the vowel versus the consonant, and as you manipulate the relative level of the consonant you create the perception of a different consonant, even though the same frequency information was there. Again, it speaks to the fact that relative intensity differences carry information. How would a hearing aid affect a situation like this?
How Do Hearing Aids Affect the Speech Signal?
Figure 9 is a crude example of what happens to the phrase "why chew my shoe" when it is processed with a short release time. The fricative sound of the /sh/ actually increases in intensity over time. When you look at the output of that hearing aid in the region where it is supposed to be a /sh/ sound you actually have something with an envelope that looks closer to a /ch/ sound because the gain in compression is released relatively quickly. You are basically changing the natural envelope of the speech sound to go from a gradually rising fricative to something that changes more dramatically and is going to be more typical the way an affricate sound would be produced.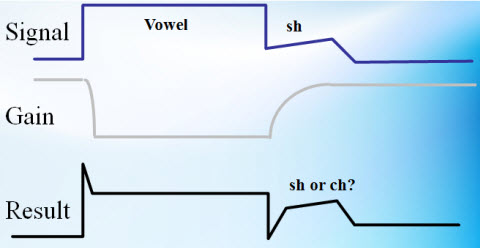
Figure 9. Schematic of a short release-time function.
If you pass the same phrase through a system within a longer release time, you see that that the gain starts to change quickly as the vowel passes through the system (Figure 10). However, you will notice the gain changes more gradually over time when coming out of the loud vowel into the fricative /sh/. When the hearing aid releases, the result maintains an amplitude that looks more similar to the original /sh/ input to the hearing aid.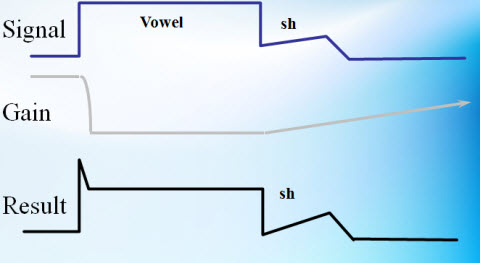
Figure 10. Schematic of a long release-time function.
Let's take a look at some of these effects in real speech signals. Consider the phrase "please jot down how much change I need" (Figure 11). Many audiologists assume that a fast-acting compression system takes the soft inputs, or consonants in this case, and applies more gain to make those sounds more audible. Figure 11 shows the assumed effect of fast-acting compression on the phrase. One of the things to remember is that hearing aids do not necessarily recognize the individual phonemes of speech. Compression systems and hearing aids do not just adjust chosen parts of speech as shown in Figure 12. This is a representation of a hand-edited speech sample where the amplitude of the soft consonants such as /z/ and /ch/ by were boosted up by 6 to 10 dB in order to make them closer in level to that of the vowel sounds.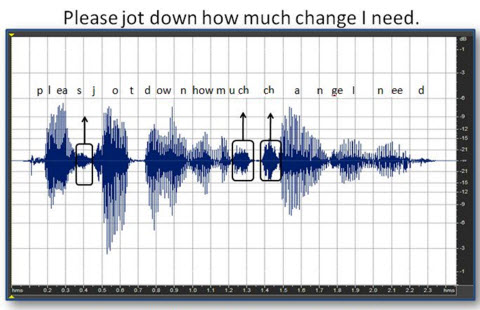
Figure 11. Assumed effect of compression on the phrase "please jot down how much change I need."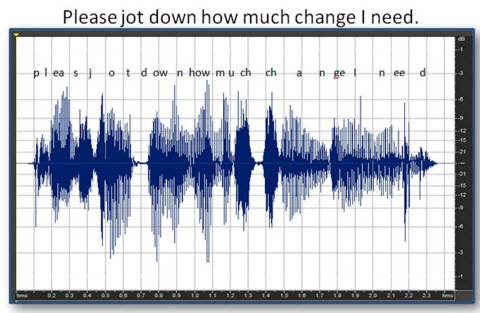
Figure 12. Hand-edited version of the same phrase, where consonants /s/, /ch/ and /sh/ were manually increased to be represented on the same order as the vowels.
All compression systems in hearing aids only recognize acoustic energy or signal level. Figure 13 shows the end result of the phrase after passing through an actual fast-acting compression system. Basically even the quiet periods between phonemes and the low amplitudes of certain phonemes are all brought up because the compression system is trying to respond to everything at a low level, not just soft consonants.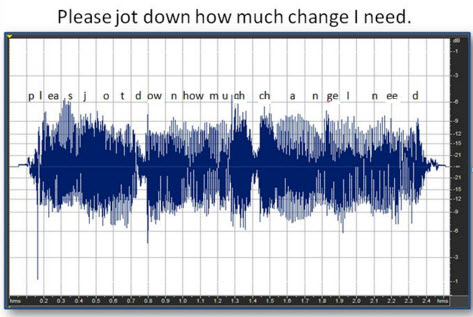
Figure 13. Actual effect of fast-acting compression on the entire phrase.
The compression system cannot tell the difference between the closure of a /p/ or the soft /th/ sound and the hissing of an air conditioner. Everything that is soft is going to be amplified by a certain amount of gain. What you get is a loss of definition of the natural amplitude changes in the speech signal (Figure 13).
We have used fast-acting compressions quite a bit over the decades because they are the sort of thing that can improve audibility for many of the soft speech sounds. But we often did not factor in the effect it was having on the sound quality through hearing aids. The situation gets even more complicated when you talk about speech in a background of noise. One of the things that happens when you get to periods of low intensity speech, like pauses between two sentences or a low-intensity speech sound, is that the hearing aid will want to increase the gain of those low speech sounds. However, it is going to take whatever sound is in the background and turn it up, also (Figure 14). When speech in relatively steady- state noise is processed through a fast-acting compression system, you get a ballooning up of the background noise during time periods where the speech is dropping to a lower level.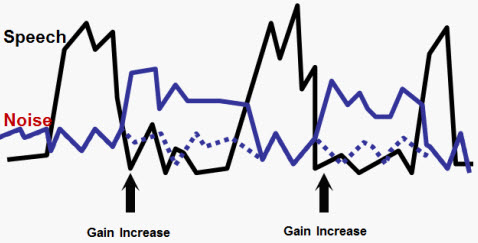
Figure 14. Effect of fast compression on speech in the presence of background noise, where low-level inputs are amplified regardless of information.
When peaks in speech occur, the noise level is driven down. But in the periods of softer speech or pauses in the speech signal, the speech or the noise level jumps back up. It is an inherent characteristic of a fast-response signal system because of the timing parameters that are used in those systems.
When I pass that same signal through a slow-response system, meaning a compression system with a long release time, you get a much quieter sound quality to the hearing aid. Slow-acting systems are not perfect, either. Slow-acting systems will not change the gain very quickly in response to a loud sound followed by a soft sound. So if you have a situation where someone is talking and there is a loud intrusive sound in the environment, that sudden loud sound is going to turn the gain of the system down, and the gain is going to stay down for long period of time. You get a drop off period. With a long release time close to 1000 milliseconds, you get that notion that the speech disappeared or certainly dropped out after that loud burst. That is one of the drawbacks of slow-response systems.
As we move forward in this field, we are going to see more sophisticated compression systems because of these known limitations of both fast and slow-acting systems. Figure 15 is a block diagram for a more modern compression system we call Speech Guard. It has two monitoring systems of the input level. Most compression systems only monitor speech input in one way, but by having two monitoring systems you can set one to respond on a long term basis to perform overall gain adjustments to the speech signal, and the other to respond to very quick and dramatic changes of the signal either upwards or downwards.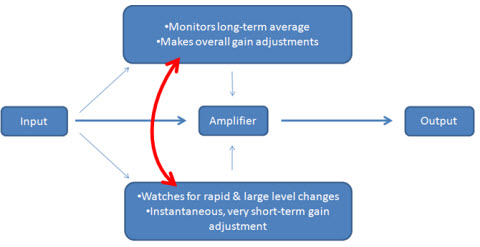
Figure 15. Speech Guard signal processing employed by Oticon. A dual-monitoring compression system processes both long-term speech inputs as well as sudden input changes.
By having a second monitoring system that only responds to relatively large jumps beyond the normal variation of the ongoing speech signal, you can create a compression system that responds either very quickly or very slowly. This is designed to get around this problem of the timing parameters of non-linear systems changing over the same time period as that of the speech signal. If you can create a compression system that responds instantaneously or very, very slowly, then you are creating a system where the compression changes are made outside the windows of the natural amplitude changes in the speech signal. This way, you are able to hear the sound quality difference because you do not hear some of the artifacts of the compression system.
Real Ear
The final topic I want to talk about is how some of these effects show up in real-ear measures. The reality is that real-ear systems do not necessarily capture all the dynamic interactions that occur in the hearing aid. For example, Figure 16 shows two real-ear recordings of two different hearing aids where the gain was set very similarly so they would match on a real-ear response. If you look at the responses you would say those two hearing aids are basically doing the same thing (Figure 16). But these two hearing aids have very different dynamic properties. One is set to relatively fast-acting syllabic compression, whereas the other is set to this dual-monitoring compression system, and it creates two very, very different sound qualities.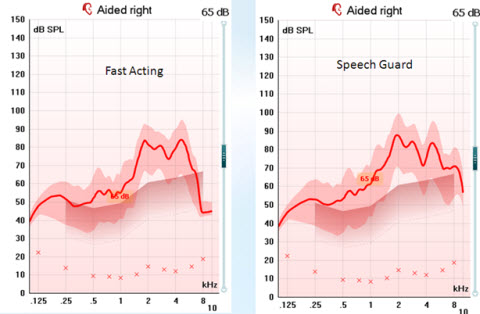
Figure 16. Two hearing instruments set to have the same gain output, with differing compression systems; the left panel is fast-acting compression, and the right panel is the dual-monitoring Speech Guard compression system.
One more example of this is with an older product we had on the market, Syncro, contrasted to a more recent product we have on the market called Agil Pro. The Syncro has a fast-acting compression system and the Agil Pro has the dual Speech Guard system. The static gain of these two hearing aids are relatively similar based on the speech mapping, however, they can create a different sound for the patient depending on the differences between the dynamic response of the systems. When listening to these two hearing aids in person, you get quite a different sound quality for both, even though the overall gain is the same.
Summary
Overall, we have come a long way with non-linear hearing aids. Now that we are 20 years into the era of multi channel nonlinear processing, it is time to start getting to the next level of discussion of what we want hearing aids to do. When non-linear multi channel hearing aids were first introduced in the early 1990s, the goal was to try to improve audibility for patients who had a limited dynamic range because of sensorineural hearing loss, and the first tendency was to use fast-acting compression. Not long after this did we start to think that slow-acting systems made better sense because of the way they preserve speech information. What you will start to see as we move forward in the field are more sophisticated systems where you do not have to make a compromise and choose either fast acting or slow acting. You will see more and more discussion from the manufacturers about these sorts of improvements and further refinements in the way non-linear hearing aids work. If there are questions about information covered here, please feel free to e-mail me at [email protected]. Thank you for your time and your attention.
Reference
Hedrick, M.S., Schulte, L., & Jesteadt, W. (1995). Effect of relative and overall amplitude on perception of voiceless stop consonants by listeners with normal and impaired hearing. Journal of the Acoustical Society of America, 98(3), 1292-1303.
Dynamics: The Third Dimension of Speech
August 15, 2011
This article is sponsored by Oticon.
Continued and its subsidiaries provide professional education authored by qualified Subject Matter Experts for continuing education purposes. These materials are intended for educational purposes and do not constitute medical advice or a substitute for individual clinical judgment. Continued is not a clinical healthcare provider; the licensed professional is solely responsible for ensuring that the application of any techniques or information presented is within their legal scope of practice and jurisdictional requirements.


Related Courses
1
https://www.audiologyonline.com/audiology-ceus/course/oticon-government-services-may-2023-38919
Oticon Government Services May 2023 Contract Update
Oticon understands that sudden, disruptive sounds affect a large majority of hearing aid users, making it difficult to stay sharp and focused – especially when engaged in conversation. Oticon Real™ is designed to help with this challenge and keep patients engaged. In this course we introduce new options on the VA hearing aid contact.
auditory, textual, visual
129
USD
Subscription
Unlimited COURSE Access for $129/year
OnlineOnly
AudiologyOnline
www.audiologyonline.com
Oticon Government Services May 2023 Contract Update
Oticon understands that sudden, disruptive sounds affect a large majority of hearing aid users, making it difficult to stay sharp and focused – especially when engaged in conversation. Oticon Real™ is designed to help with this challenge and keep patients engaged. In this course we introduce new options on the VA hearing aid contact.
38919
Online
PT60M
Oticon Government Services May 2023 Contract Update
Presented by Kirstie Taylor, AuD
Course: #38919Level: Intermediate1 Hour
AAA/0.1 Intermediate; ACAud inc HAASA/1.0; ASHA/0.1 Intermediate, Professional; BAA/1.0; CAA/1.0; IACET/0.1; IHS/1.0; Kansas, LTS-S0035/1.0; NZAS/1.0; SAC/1.0
Oticon understands that sudden, disruptive sounds affect a large majority of hearing aid users, making it difficult to stay sharp and focused – especially when engaged in conversation. Oticon Real™ is designed to help with this challenge and keep patients engaged. In this course we introduce new options on the VA hearing aid contact.
2
https://www.audiologyonline.com/audiology-ceus/course/why-evidence-matters-38163
Why Evidence Matters
Oticon has a long history of focusing on innovative research into how the brain processes sound and how technology can support the brain’s natural ability to process sound. In this course we will review evidence supporting Oticon’s technology developments and how hearing care professionals can use this information to discuss benefits and explain why they are recommending Oticon solutions.
auditory, textual, visual
129
USD
Subscription
Unlimited COURSE Access for $129/year
OnlineOnly
AudiologyOnline
www.audiologyonline.com
Why Evidence Matters
Oticon has a long history of focusing on innovative research into how the brain processes sound and how technology can support the brain’s natural ability to process sound. In this course we will review evidence supporting Oticon’s technology developments and how hearing care professionals can use this information to discuss benefits and explain why they are recommending Oticon solutions.
38163
Online
PT60M
Why Evidence Matters
Presented by Lana Ward, AuD
Course: #38163Level: Intermediate1 Hour
AAA/0.1 Intermediate; ACAud inc HAASA/1.0; AHIP/1.0; ASHA/0.1 Intermediate, Professional; BAA/1.0; CAA/1.0; IACET/0.1; IHS/1.0; Kansas, LTS-S0035/1.0; NZAS/1.0; SAC/1.0
Oticon has a long history of focusing on innovative research into how the brain processes sound and how technology can support the brain’s natural ability to process sound. In this course we will review evidence supporting Oticon’s technology developments and how hearing care professionals can use this information to discuss benefits and explain why they are recommending Oticon solutions.
3
https://www.audiologyonline.com/audiology-ceus/course/oticon-government-services-introducing-more-36630
Oticon Government Services: Introducing Oticon More
Sound scenes are dynamic, complex and unpredictable. It is the role of the brain to handle this complexity to hear and make sense of it all. Oticon is committed to developing life changing technologies that support the way the brain naturally processes sound. Get ready to discover the new perspective in hearing care with a fundamentally new approach to signal processing. *This is a recording of the VA Oticon More Introduction Event from May 3, 2021*
auditory, textual, visual
129
USD
Subscription
Unlimited COURSE Access for $129/year
OnlineOnly
AudiologyOnline
www.audiologyonline.com
Oticon Government Services: Introducing Oticon More
Sound scenes are dynamic, complex and unpredictable. It is the role of the brain to handle this complexity to hear and make sense of it all. Oticon is committed to developing life changing technologies that support the way the brain naturally processes sound. Get ready to discover the new perspective in hearing care with a fundamentally new approach to signal processing. *This is a recording of the VA Oticon More Introduction Event from May 3, 2021*
36630
Online
PT60M
Oticon Government Services: Introducing Oticon More
Presented by Candace Depp, AuD, Thomas Behrens, MS, Danielle Tryanski, AuD, Sarah Draplin, AuD
Course: #36630Level: Intermediate1 Hour
AAA/0.1 Intermediate; ACAud inc HAASA/1.0; AHIP/1.0; BAA/1.0; CAA/1.0; IACET/0.1; IHS/1.0; Kansas, LTS-S0035/1.0; NZAS/1.0; SAC/1.0
Sound scenes are dynamic, complex and unpredictable. It is the role of the brain to handle this complexity to hear and make sense of it all. Oticon is committed to developing life changing technologies that support the way the brain naturally processes sound. Get ready to discover the new perspective in hearing care with a fundamentally new approach to signal processing. *This is a recording of the VA Oticon More Introduction Event from May 3, 2021*
4
https://www.audiologyonline.com/audiology-ceus/course/genie-2-fitting-focus-series-36119
Genie 2 Fitting Focus Series: Oticon More First Fit
In this course we will cover the initial fitting steps for a successful Oticon More initial fitting using Oticon’s Genie 2 fitting software.
auditory, textual, visual
129
USD
Subscription
Unlimited COURSE Access for $129/year
OnlineOnly
AudiologyOnline
www.audiologyonline.com
Genie 2 Fitting Focus Series: Oticon More First Fit
In this course we will cover the initial fitting steps for a successful Oticon More initial fitting using Oticon’s Genie 2 fitting software.
36119
Online
PT30M
Genie 2 Fitting Focus Series: Oticon More First Fit
Presented by Amanda Szarythe, AuD, CCC-A
Course: #36119Level: Intermediate0.5 Hours
AAA/0.05 Intermediate; ACAud inc HAASA/0.5; AHIP/0.5; BAA/0.5; CAA/0.5; IACET/0.1; IHS/0.5; NZAS/1.0; SAC/0.5
In this course we will cover the initial fitting steps for a successful Oticon More initial fitting using Oticon’s Genie 2 fitting software.
5
https://www.audiologyonline.com/audiology-ceus/course/counseling-techniques-supporting-standard-care-38697
Counseling Techniques Supporting Standard of Care
Effective counseling practices make a tremendous difference in hearing healthcare. Being able to communicate the benefits of advanced technology in simple language patients can understand is the key element in this process. This course will provide suggestions for consumer-friendly language based on clear benefits when making a strong recommendation for premium technology as the standard of care.
auditory, textual, visual
129
USD
Subscription
Unlimited COURSE Access for $129/year
OnlineOnly
AudiologyOnline
www.audiologyonline.com
Counseling Techniques Supporting Standard of Care
Effective counseling practices make a tremendous difference in hearing healthcare. Being able to communicate the benefits of advanced technology in simple language patients can understand is the key element in this process. This course will provide suggestions for consumer-friendly language based on clear benefits when making a strong recommendation for premium technology as the standard of care.
38697
Online
PT60M
Counseling Techniques Supporting Standard of Care
Presented by Amanda Greenwell, AuD
Course: #38697Level: Intermediate1 Hour
AAA/0.1 Intermediate; ACAud inc HAASA/1.0; AHIP/1.0; ASHA/0.1 Intermediate, Professional; BAA/1.0; CAA/1.0; IACET/0.1; IHS/1.0; Kansas, LTS-S0035/1.0; NZAS/1.0; SAC/1.0
Effective counseling practices make a tremendous difference in hearing healthcare. Being able to communicate the benefits of advanced technology in simple language patients can understand is the key element in this process. This course will provide suggestions for consumer-friendly language based on clear benefits when making a strong recommendation for premium technology as the standard of care.