
Learning Objectives
After this course, participants will be able to:
- Describe the basic differences between supervised, unsupervised and reinforced machine learning.
- Describe how the first real-time machine learning application functions within a hearing device.
- List two examples of how incorporating real-time machine learning in a hearing device will improve hearing personalization for end-users and the potential for less follow up visits.
Introduction and Agenda
During this course we will answer the following questions:
- What is Artificial Intelligence?
- What is Machine Learning?
- Growth of Machine Learning
- How Do Humans Learn?
- How Do Machines Learn? Applications of Machine Learning
- First Real Time Machine Learning Application in a Hearing Aid
We're going to spend time discussing and defining artificial intelligence, machine learning, and the impact that these technologies are going to have on the audiology profession. After gaining a better understanding of machine learning, we will discuss its growth. Next, we'll spend some time analyzing how humans learn, as compared to how machines learn. Finally, we'll talk about the first real-time machine learning application in a hearing aid: The Widex Evoke.
Banana Split Analogy
Before we start, I'd like to do an exercise with you. I would like for you to think about the ingredients that you would use when building your own banana split. The most common ingredients would likely be bananas and ice cream, however, some of you may not like bananas. If you just want to have the ice cream, that's great. You may choose to add any number of toppings, such as hot fudge, caramel, marshmallow cream or sprinkles. You might add Reese's peanut butter cups and Heath bar crumbles, and put whipped cream and a cherry on top.
If you think about the ingredients that go into a banana split, we all get the same choices: ice cream, bananas, assorted toppings, such as sauces and sprinkles. You can use whatever you want, because it's based on what you like, on your preferences. If you are sitting next to a colleague right now, you may find that they've built a completely different banana split than you would. The one that we're going to enjoy the most is the one that we build, based on what we like. Similarly, this idea of preference is relevant to our topic today, as we think about and focus on the needs and preferences of our patients. 
History
I'm excited to talk about the first hearing aid in the industry that's using real-time machine learning in its technology. But before we dive into that, let me back up for a second and give you a brief history with regard to machine learning and artificial intelligence to understand where we have been and the challenges that we've faced.
- 1950: Alan Turing published paper “Computing Machinery and Intelligence.” He proposed via the Turing test (which allowed a computer to simulate human communication) that a computer is thought to be intelligent if a human judge can’t tell whether he/she is interacting with a human or machine. Based on Turing's premise, several developments followed.
- 1956: John McCarthy coined the phrase “artificial intelligence.” In that same year, he created a conference at the Dartmouth Academy (the Dartmouth Academic Conferences), where computer scientists rallied around the term Artificial Intelligence and the field of AI was born.
- 1960-1980: AI research flourished, but the technology was not ready to implement concepts, as they did not have computers that would be able to handle the level of processing required.
- 1980-2000: Integrated circuits in computers move artificial intelligence and machine learning from science fiction to science fact. Despite this technology surge, at that time, computers still did not have the power to allow them to do the sophisticated calculations required for AI/ML.
- 2000-Present: Deep Learning: Speech, Vision, Language and Pattern recognition
From the year 2000 to the present, primarily around 2015, there was a huge influx of advanced technology, integrated circuits, dual-core and quad-core technology, that pushed the concepts of artificial intelligence and machine learning to another level, to the point where we have what we call deep learning. We were able to create a computer that could speak. We were able to create a computer that had vision recognition, that could see and separate items. We were able to create a computer that could identify and recognize the language, as well as patterns and data trends.
The Artificial Intelligence Umbrella
Over time, we've witnessed changes in our ability to implement artificial intelligence and machine learning. Today, technology is so advanced that the use of this technology is second nature. The domain of AI can be thought of as the umbrella: the broader concept of making machines smarter and allowing machines to learn. Underneath that umbrella are several subsets, one of which is machine learning: the systems and algorithms that are designed to learn structures to predict future outcomes. A subcategory of machine learning is deep learning, which is more of a neural network. With deep learning, we're mimicking the human brain, in a sense. Deep learning is often used to analyze and learn from data, rather than complete a task.
Artificial Intelligence
Artificial intelligence is an attempt by scientists to use computers to mimic human neural structure and processing. They are designing a computer to work like our brain does. The human brain has neurons which are connected to each other, and they can share information. The idea behind AI is to try to mimic that neural communication to make a machine work similar to the way the human brain works by pooling these neural networks and creating smaller clusters of processes within this network that share information. IBM has coined the phrase "cognitive thinking" as a way of talking about artificial intelligence.
Machine Learning
On the other hand, machine learning is a scientific discipline that addresses the following question: how can we program systems (i.e., computers) to automatically learn and to improve with experience? Learning is recognizing complex patterns and making intelligent decisions based on data. Machine learning systems use algorithms that uncover knowledge from data and experiences, based off of statistical and computational principles. Using these algorithms allows a system to accomplish many tasks, such as:
- Vision to language processing: We can to talk to our smartphones and other devices (e.g., Siri, Cortana and "Hey Google") and the device can recognize our voice and it can speak back to us and understand language.
- Pattern recognition: An example of pattern recognition is a system being able to recognize the traffic patterns within an area, and based off those patterns, redirect people to routes with less traffic and less congestion.
- Data mining: Data mining is popular in large companies. How do we look at all this data and make sense out of it, and find a pattern or a trend that we can use? This is a challenge for humans, as our brains can only process so many numbers. It's not a challenge for computers, however, because computers look at and analyze data all the time.
- Robotics: Robotics is becoming very popular, particularly in the automotive industry. Companies are building robots that work in tandem with a human; they work as an extension of what the human can do, allowing the human to lift larger things, to move objects, to work more efficiently.
What Does Data Look Like?
Data can take the form of many different things. For example, data can be numbers that we need to interpret, such as in the stock market, or home prices in a certain area as compared to other areas. Data can be information as to how different medications interact with one another. Restaurants like Pizza Hut and Domino's use predictive algorithms to locate where you are and the closest restaurant that will deliver to you. Cars now have the ability to identify other vehicles and use data to determine if it is a police car, or a sedan, or a truck, or a bus. They even have the ability to tell the difference between a cat and a dog. Systems are getting smarter at identifying and looking at data. A lot of the airlines now are using matrix systems to develop new bulkheads in their airplanes, to make them sturdier but lighter. Computers can quickly analyze and manipulate data into a variety of iterations and patterns and figure out which is the sturdiest. Humans would not be able to achieve that level of speed or accuracy.
As hearing care professionals, data that is relevant and important to us is acoustic information. For instance, being able to measure and track sounds in a hearing aid wearer's environment is important, so that we can get a good acoustic scene analysis of what's happening, in case we need to make adjustments to the hearing aids.
Big Data and the Cloud
The term cloud computing means storing and accessing data and programs over the Internet instead of a computer's hard drive. The cloud is just a metaphor for the Internet. Windows and Apple have cloud-based systems. A lot of music providers have cloud-based systems. Facebook uses a cloud-based system to store their data because there's so much of it.
Big data can be defined as extremely large data sets that may be analyzed to reveal patterns, trends, and associations, especially relating to human behavior and interactions. There's a lot of data out there to be analyzed, including data from our phones, our cars, prices of different items, things people are buying online. In the marketplace, if you can make sense of all that data, and find a pattern or a trend within the data, it gives you an edge. Making sense of this data is where machine learning and artificial intelligence comes into play.
Hearing in Real Life
When we talk about machine learning, what does that mean for us as clinicians working with patients in the office? One of the things that we probably all have in common when fitting a patient with the right technology is turning on the hearing aids in the office and hearing them say "Oh my gosh! Your voice sounds so good here! If everyone spoke like you, I wouldn't need a hearing aid." However, patients don't live in our office. Once they leave and go out into the real world, they experience hearing challenges, such as situations where it was too loud or too quiet.
Being able to get patients to articulate the difficulties they experience can also be a challenge if they aren't sound-savvy, or they're not an engineer or musician. It can be a challenge to fine-tune and modify those fittings, based on the information that the patient is able to tell us. They may not even remember those details by the time they get back to see us a few days to a week later. They may have forgotten all the elements in that environment that made it difficult for them to communicate. We want to look at the auditory ecology of what is happening in the real world so that we can create solutions for real-world scenarios.
Meeting Patients Where They Are
If we want to meet patients where they are, we need to keep in mind the intention of each patient. When we build the technology, we build it with the assumption that when a patient goes into a loud environment, it's going to turn down, and when they go into a soft environment, it's going to turn up. Those assumptions are based on what we think the patient wants. We need to give them the ability to attend, so we want to give them access to those sounds, but their intention in those moments in time is critical. If I decide I'm going to Starbucks, and I'm just going to read and relax, my intention is just to relax, to be in the environment. I don't want to hear all the conversation, but I still want to be there. That's my intention. If I go there with some colleagues and we're having a conversation, then my intention is to listen to my colleagues or those around me. It's the same environment, but my intention can change. That's the part of the equation that we sometimes miss: what is the patient's intention in those environments?
As a musician, I love music. I am passionate about music. I typically listen to music loud; I like to feel the music. My wife enjoys the same music as I do. However, she listens to it at a much lower volume. The way I listen to it and my intention is very different than hers.
Evoke Chipset System
What Evoke is able to do is now listen to the patient intent and meet patients where they are by allowing them to have a real-time control that is efficient and powerful, to hear what they are motivated to hear in each moment. Widex has built the hardware within the hearing aid that allows us to capture those elements and to do these incredible processes that we need. With our sophisticated chipset system, Widex Evoke is able to work together and offer real-time sharing of information with a smartphone.
Dual core. Our chipset system makes it possible for us to have two cores. First, we have the accelerated core. The accelerated core has allowed Widex to be the industry leader in battery efficiency. It has also allowed us to achieve excellent sound quality, along with all of our wonderful features. As we've built that out, we've now added another layer: the flexible core. By stacking these technologies together, the Evoke chipset allows us to do some things that we would not be able to do with just the one core by itself. In our system, we have variable speed compression, which allows us to have both fast and slow-acting compression working in tandem, and we are able to capture and shape the ideal sound for patients, based on their environment. In addition, we have 30 percent more processing power. With increased processing power, we can achieve an even faster assessment of acoustic environments and implement the best and most accurate processing strategies in multiple real-world situations.
Distributed computing. Furthermore, the chipset allows us to use what we call distributed computing. We are now able to share what's happening in the hearing aid to a smartphone. We're able to leverage the power of a smartphone and a hearing aid to work together in tandem. You can communicate the acoustic environment to the smartphone, where all the machine learning is happening. The processing power that we have today in smartphones is incredible. The smartphone is doing the heavy lifting of the machine learning, but sharing that back and forth with the hearing aid as we make these adjustments. Going a step further, we're taking that information in that environment and sending it to the Widex cloud. By doing that, we can create new features and more sophisticated algorithms based on our patients' preferences and what they like. We can learn from that, we can share that back with the smartphone and then send automatic updates (e.g., firmware updates, new implementations of features) from the phone directly to the hearing aid. Again, this distributed computing system allows us to do things that we've never done, including machine learning.
Automation. We have had automation in the industry for a while. Automation in a hearing aid gets us about 85 percent of where we need to be. But there's still 15 percent that we are missing when the patient is out in a real environment. Those moments tend to be the ones that our patients complain about and they want help with. The larger moments, like weddings and graduations, we plan for those; we've got that covered. But we want to give patients control over the unplanned and spontaneous moments. Using artificial intelligence and machine learning, we can now have visibility to those environments and can give our patients the opportunity to set the sound the way they like it, at the moment.
Our hearing aids are automatic, which takes some of the cognitive load off of our patients. They don't have to worry about how to make adjustments and changes to the hearing aids. That format is what we call a "baked" system, as in we have baked into that hearing aid what it needs to do. We programmed it, and it has learned what it needs to do when it goes into certain environments. But all it can do is what we have taught it; what it has learned and what's baked into the system.
Learned vs. Learning. Let's look at the differences between systems that are "learned" and those that are "learning". A learned system knows how to operate within the parameters of how it's been taught, and it will not step outside of that. A learned system is training a machine in a lab to make certain algorithms. Most of what you see in the industry from different manufacturers are learned systems. The Evoke has the capability to take in and process information, and make real-time decisions based on that information received. With machine learning in Evoke, we're looking at a learning system. The device continues to learn after the fitting. The learning occurs outside of the lab in the real world.
Why Use Machine Learning?
Why are we able to do this now? The reasons are threefold:
- Today's smartphones have the computing power of laptop computers.
- Increase in available algorithms and theories by machine scientists that can now be implemented into the device.
- More available data due to advancements in the internet, distributed computing, and the Cloud.
Using these advancements in technology, we're able to take machine learning to the next level in the hearing aid industry. We can use machine learning to develop systems (algorithms) that can automatically adapt and customize themselves to an individual user's preferences: what they like, the way they like to hear it. Machine learning can also allow us to discover new knowledge from users' data and preferences. This is something that you have likely been exposed to but may not have realized it. For example, there's a soft drink manufacturer that has a certain soda machine where you can customize your drink. You can mix an orange drink, diet Dr. Pepper, and ginger ale if you wanted to, to create your own concoction of flavors. That machine, when you create those combinations, it sends that information to the soda manufacturer, who can create new soft drinks based on your selections and how often others choose that same combination. They're learning what their customers like, based on user selections.
Growth of Machine Learning
Machine learning has grown immensely in the last few years, to the point where it is part of our everyday life. Many corporations use machine learning, such as Google, Amazon, Pandora, and Netflix. For example, once you watch a movie on Netflix, the machine learning behind the system pays attention to the actors, the rating, the genre, and looks for other movies that follow that same pattern. When you finish watching one movie, the system will have lined up other similar films for you to watch. Using those patterns, it's able to predict other movies that you might like. Music servers like Pandora or Spotify will recommend artists similar to the ones that you have previously select. Shopping sites like Amazon know what you have searched for and what you have already bought, and will make suggestions based on previous searches and purchases, and will also offer ideas as to what other people have ordered. Our phones now use facial recognition, as well as voice recognition. Clearly, looking for patterns and associations is part of our daily landscape today.
How Do Humans Learn?
In order to compare and contrast human vs. machine learning, let's first take a look at how humans learn. Depending on their preferences, humans learn through four modalities: visual, auditory, tactile or kinesthetic.
Visual preference. Sixty percent of students are visual learners. When they are learning a task or a job, these people learn best by being able to watch you do something. They have a visual preference for learning.
Auditory preference. People with an auditory preference learn things best by hearing and listening to verbal instruction. If they can hear the way you explain it to someone, then they understand it.
Tactile preference. Those who have a tactile preference learn best when they take notes during lectures or when reading something new or difficult. These people are hands-on learners. They have to feel it, touch it, put their hands on it, and do it themselves. Mechanics tend to be tactile learners. When they can get their hands on something and manipulate the parts themselves, they can remember how to fix things and put them together.
Kinesthetic preference. People with a kinesthetic preference learn best when they are involved and active. They learn the easiest when they are doing something, rather than watching it. Toddlers and babies are kinesthetic learners, in that they put things in their mouth. If they are handling a toy, they'll drool on it, put it in their mouth, touch it, hold it, and bang it on something, because they want to get fully immersed in that toy. Thankfully, we outgrow that oral exploration stage, but that's the way we learn as humans.
Generally, we have one dominant learning preference, but we can also have a secondary preference. For example, you may be a dominant visual learner, but your secondary modality might be an auditory preference.
How Do Machines Learn?
In contrast to humans, machines learn using three different modes of learning: supervised learning, unsupervised learning, and reinforced learning.
Supervised learning. Supervised learning is learning guided by human observations and feedback from known outcomes. This would be like me teaching a child to play the piano. I would sit the child beside me, and I then would explain to them that this is a piano in front of us. There are black and white keys. On one side of the piano, there are low notes; on the other side of the piano, there are high notes. If you push the piano notes softly, they play softly; if you push them hard, it plays loud. I have just labeled for that child what this instrument is. Then I'll give them direction on the patterns, of how you press different keys at the same time to form chords. I'm supervising the learning process for that child. As they continue to learn, with that supervision, they will accelerate and learn faster to the point where they'll take what I've taught them and they can expand that and learn on their own. That's supervised learning.
Unsupervised learning. Unsupervised learning relies exclusively on clustering data and modifying its algorithm (recipe) to its initial findings, all without the external feedback of humans. This would be analogous to a child playing the piano without instruction. They may figure out eventually that one end of the piano has low notes, and the other end has high notes. They may figure out that if they press the keys softly, then it plays softly, and if they push the keys hard, it plays loud. There's no supervision to guide them through this process. Using an unsupervised process, it would take longer for them to learn to play the piano, compared to if they were supervised.
Reinforced learning. Reinforced learning is learning that is established over time via trial and error. One example of reinforced learning is a baby learning to walk. This type of learning is also used in the video gaming world. For example, if you play Pac Man, you need to navigate the maze a certain way or you get killed by a ghost. If I go left down a certain corridor and a ghost pops out and I die, the next time I play it, I will learn not to go left. I'll go right, instead. Pac Man and other games are developed using reinforced learning.
Using these three types of learning, systems work very efficiently. Computers are able to do a lot of calculations, much faster and more efficiently than humans can. Humans are capable of solving mathematical problems and equations, but when they involve multiple decimal points and more than two or three columns of numbers, it is beyond a human capacity to process that many numbers very efficiently.
Listening Intention
Applying this information to the hearing aid industry, using machine learning as a background allows us to give our patients the power to select how they want to hear in each environment, based on their preference. In real life, users’ listening intention may vary, and in any given auditory scenario, a user might prefer to increase the overall sound quality, lower the conversation level, or something completely different. The intention to achieve an auditory-related task, or experience an event with a certain level of fidelity, we call listening intention. Based on what the patient likes or doesn't like, or what they want to hear or don't want to hear, they can make an adjustment with their app. Simply doing an A/B comparison, that will allow the machine learning to start looking for patterns in the patient's preferences. The system can quickly make sense of those patterns and refine the sound that they want to hear in that environment.
SoundSense Learn
To bridge this gap between auditory scenario, auditory intention, and hearing aid controls, we created SoundSense Learn to harness the power of machine learning through your smartphone. SoundSense Learn can quickly adapt advanced hearing aid settings to adjust hearing parameters – all driven by the end users preferences and intentions.
In the Widex SoundSense Learn Evoke System, we are using the three-band equalizer (bass, middle and treble) within the app (Figure 1).
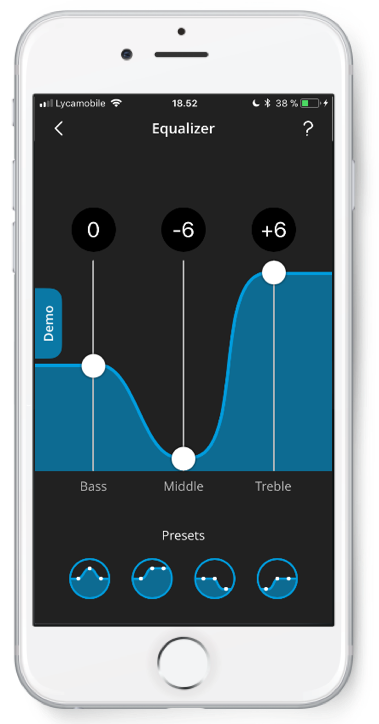
Figure 1. Three band equalizer.
There are 13 levels of adjustment per equalizer band (133) which comes out to 2197 comparisons, or adjustment combinations that we can use. When we use that figure in an A to B comparison (2197 x (2197-1))/2), the number of combinations goes up to 2,412,306 comparisons. Clearly, no patient is going to sit there and let you make two million adjustments in an environment. However, by leveraging the power of machine learning, we were able to refine that down to 20 adjustments that they can make with the app. Some patients can achieve their ideal setting within three to four adjustments. But if they want to refine it further, they can go up to as many as 20. Again, the ability to leverage the power of that smartphone to do the heavy lifting and computations is incredible. It allows the patient to personalize within moments what they like to hear. Based on their preference, based on what they choose to hear, based on if they're listening to voices or music, they have the power to adjust it.

More Control, Less Effort
When using the Evoke app, the user gets to choose between two settings, A and B (Figure 2). Behind each A or B selection is a sound profile with different hearing aid settings. This is where the system has started the machine learning in the background. The patient has to listen to two sound settings, and choose which one they like better. All they have to do is tap and listen, and then tap again. If they like it, they can slide the button over to the right or left, to A or B, to indicate which one they liked better. Or, if they don't hear a difference, they can leave it in the middle. They can continue to refine the sound, and as they do this, the machine learning is going to learn their preference and their style and what they like in hearing in those environments.
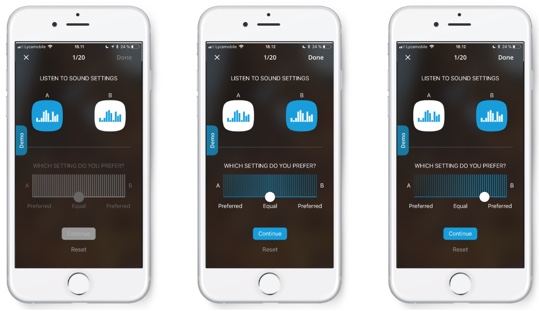
Figure 2. Sound setting selection.
The fitting of the Evoke remains the same as what you've done in the past. If you do real ear measurements, if you do a verification, if you do a sensogram feedback test -- none of that changes. We are not affecting the work of the audiologist. Nothing overwrites their original fitting. We simply let the app adjust the equalizer within the available range. The main difference is now the user points to what sounds better. If they like it, they can use that program in that current situation, or they can save that program as a favorite for a future outing to their favorite restaurant or to a sporting event.
User Feedback
We conducted some field trials, working with patients and letting them listen in different environments. Those patients gave us feedback on what they experienced. The following are a few of the comments that we received:
“I was at a department lunch for more than 25 people. For the first time, I was able to hear and understand all the comments from the Department Head, as well as more of the comments from around the table than before!”
“While sitting in the lounge with my children, I can hear even more of what they say to each other, as well as hear the television - a revelation!”
“I managed to create a program at the swimming pool just prior to my son's swimming lesson. This allowed me to have conversations with other parents, and my son's swimming teacher, whilst largely excluding the 'water' sounds and the many 'echoing' sounds of the children having fun. Really wonderful, and so much less stress.”
I want to address the last comment from the gentleman who created a program for his son's swimming lesson. He was able to clearly hear conversations in that noisy swimming pool environment, and he stated that it was much less stressful than it had been before. That is a powerful testimonial. When our patients are trying to hear and attend, if they're challenged, they have to work very hard. At the end of a conversation, they could become exhausted, simply from trying to hear in different, challenging environments. This is a powerful representation of the freedom and the power that can be achieved with SoundSense Learn.
Proof of Benefit
We did another study with 19 subjects where we had them rate improvement in both comfort and sound quality wearing our hearing aids in three conditions: with the sound, classifier not active, with the sound classifier active, and finally using SoundSense Learn to make an adjustment (Figure 3).
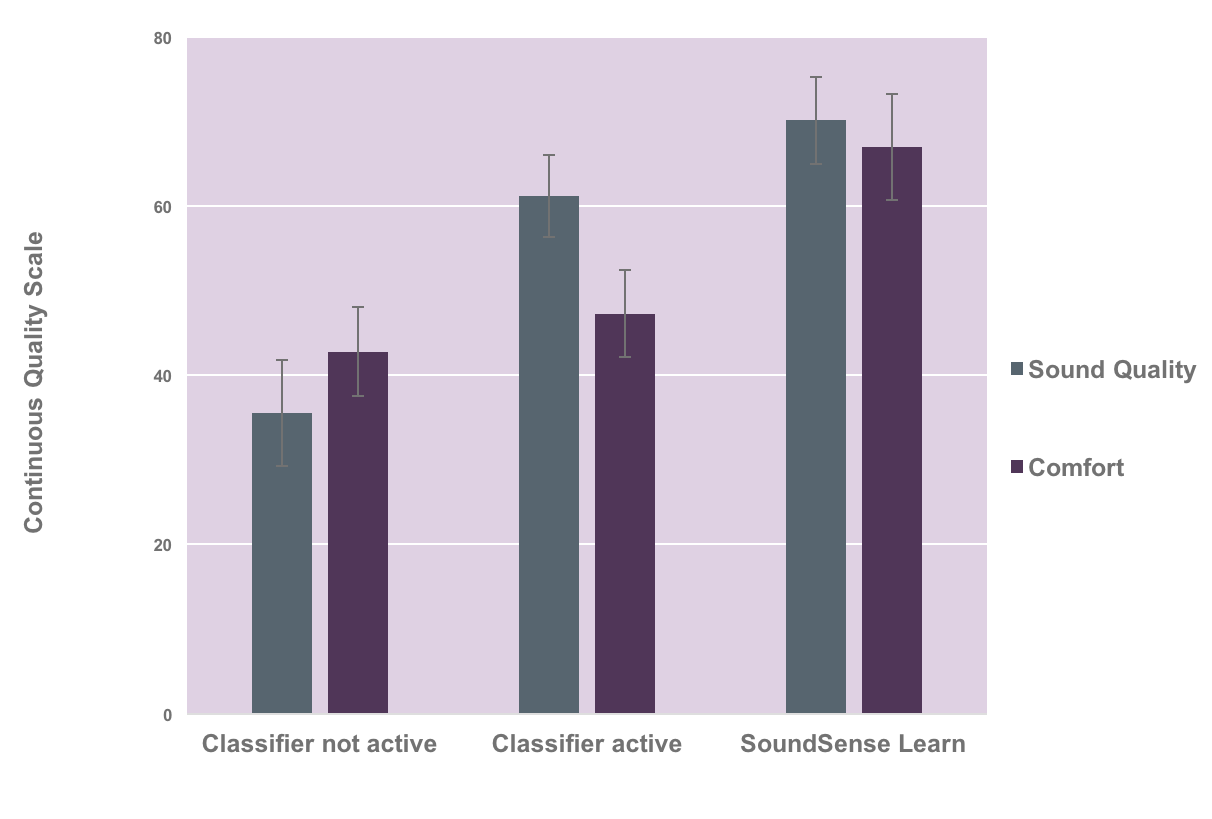
Figure 3. Subjective improvement ratings: comfort and sound quality.
As a result of this study, we found that:
- 84 percent of subjects felt that SoundSense Learn improved their comfort
- 86 percent of subjects felt that SoundSense Learn improved their sound quality
Even as compared to having the sound classifier active, we can see the perceived benefit of using SoundSense Learn. It made marked improvements in the subjects' perception of what they heard.
In the Widex Evoke, we have SoundSense Learn, which gives us real-time, user-driven learning for the patient, that is also using distributed computing for more cloud-based network learning. We also have SoundSense Adapt, which uses gradual, long-term learning that allows the system to learn how the patient likes to hear. With SoundSense Learn, we are the industry's first with regard to real-time machine learning in a hearing aid. With SoundSense Adapt, we're the industry's best, because the system only permits gradual adjustments equal to a maximum of 50% of the preference control range selected by the clinician. Our competitors have tried to implement this in their hearing devices, but have been unsuccessful. As a clinician, you can also see the SoundSense Adapt adjustments within Compass. You can monitor where the patient started and where they went up or down within the system. By being able to see their activity, you can guide them and maybe make changes to their program, if need be.
Summary and Conclusion
Machine learning is an important area for hearing care clinicians to be familiar with. Not only has hearing evolved, but hearing technology has evolved. A symbiotic collaboration between clinicians and machines is now part of our industry. That being said, hearing healthcare providers and professionals will not be replaced by technology. However, hearing healthcare professionals and providers who don't understand, use, and incorporate technology into their practices will be outperformed by those who do.
Advancements in technology provide us the ability to see things that we would not otherwise see. We have had the opportunity to fit patients and test them in different environments. Using SoundSense Learn, we have seen unique patterns and configurations that we may have never thought to give our patients, but that the patient has chosen and prefers. Their preference is not our preference. What they like and what gives them the ability to hear in those environments is unique. Not based on our biases, or the way we think of sound and frequency, but based on what they prefer and they like, in those environments. That is a powerful tool for your patient that will change the way we do business in the hearing healthcare industry.
In conclusion, SoundSense Learn is the industry's first, real-time machine learning application in a hearing aid, with its own cloud-based, networked learning. Our goal is to be intelligent today, smarter tomorrow. By incorporating machine learning, SoundSense allows us unlimited possibilities for the future which will revolutionize what we do in our field. Understanding and incorporating this technology will give you the leveraging power to help your patients, not only while they're in your clinic, but also when they're out in the real world.
Citation
Martin, J. (2018). Intelligent today, smarter tomorrow: machine learning in Widex Evoke. AudiologyOnline, Article 23476. Retrieved from https://www.audiologyonline.com

