
The issue regarding the ideal number of "channels" has been a hot topic in rehabilitative amplification for over a decade. Despite the ongoing debate, conventional wisdom indicates more is better, and we have seen a surge in the number of channels in commercially available instruments over the last few years. Most recently, we have seen a number of advanced systems offering circuitry such as "anti-smearing filters," designed to reduce the deleterious effects of a large number of channels.
This article will consider the advantages and disadvantages of current multi-channel systems and describe the phenomena of "spectral smearing." We will then briefly describe a new system, developed for Bernafon's Symbio hearing system, that uses "unified signal processing."
What is multi-channel amplification?
Multi-channel systems split the incoming signal into frequency bands, much like an "equalizer" in stereo systems of years past. Each band typically has it's own compression circuit. Individual compression circuits allow these multi-channel instruments the flexibility to amplify each frequency band independently, to maximally correspond to the user's needs, preferences and their dynamic range. In addition, each channel may be set with unique attack and release times.
Currently, instruments with 2 to 15 channels are commercially available. It may appear that the larger the number of channels, the better the compensation for individual hearing impairment. However, increased numbers of channels may also have drawbacks, worthy of consideration.
Goals of amplification:
Among the main goals of amplification are making speech signals audible, accessible and comfortable for individuals with hearing loss. The "fitting philosophy" regarding how to best achieve these goals differ, e.g. speech optimization versus loudness normalization, but the goal is essentially the same - to establish, or to re-establish receptive communication disrupted by hearing loss.
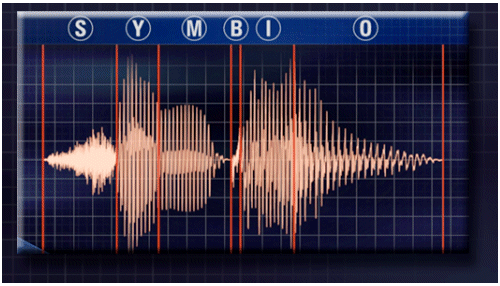
Figure 1. Waveform of /Symbio/
Speech can be thought of as (Figure 1) a dynamic stream of phonemes. Basically, phonemes are the smallest units of speech. Phonemes vary in spectral content (roughly from 100-8000 Hz), intensity (~45-75 dB SPL for average speech) and temporal characteristics (spectral, intensity and temporal features are key factors in the identification of phonemes at the microscopic level, and speech at the conversational level.
For speech to be understood, a sufficient portion of the speech signal must be audible. Of course, the brain can fill in some missing or ambiguous signals based on phonetic redundancy and knowledge of the language. Nonetheless, to maximally perceive phonemes and speech, the sounds must be audible and should be amplified in such a way that they are recognizable, i.e. that the key features of the phonemes used for identification (spectral, intensity and temporal, see above) are available to the listener.
Theoretically, multi-channel compression allows speech information to be maximally prescribed and amplified to achieve ideal audibility in each frequency band. Theoretically, multi-channel compression might also improve speech understanding by reducing the upward spread of masking and by preventing extraneous signals from dominating the applied gain.
However, there are potential drawbacks to multi-channel compression, such as the variable perceptual limits of the hearing impaired cochlea, and the possible distortion unintentionally introduced to the signal, through electro-acoustic amplification and interaction of multiple channels.
Distortion in the cochlea:
Distortion in the cochlea is not trivial. Although multi-channel amplification may present an apparent high quality signal as the output of the electro-acoustic amplification system, the hearing impaired cochlea has significantly less ability to use these sounds than does a normal healthy cochlea. Multi-channel amplification usually makes it possible to amplify all elements of the speech signal to audibility. However, in addition to loss of sensitivity for less intense (i.e., quiet) sounds, often sensorineural hearing loss also results in broadening of auditory filters, with the concomitant perceptual consequence that the frequency selectivity is reduced (Moore, 1998). Additionally, for hearing impaired listeners, the internal representation of acoustic signals has a lower signal-to-noise ratio than for normal hearing people (Leek and Summers, 1996). In cases of sensorineural hearing loss, multi-channel amplification may effectively bombard the cochlea with sound that has less spectral contrast, which is important for speech understanding (Boothroyd et al, 1996). Additionally, impaired cochlear frequency resolution means that despite audibility, spectral information may still not be useful to the listener (Smoorenburg, 2000).
Distortion of the amplified signal:
Some speech sounds, such as vowels and diphthongs (combined vowel sounds) are recognized by the relative frequency and intensity of the formants (regions of focused vocalized speech energy) comprising them (Figure 2). In other words, formant identification is less dependent on the actual (static) frequency and intensity cues of the individual phoneme components, and more dependent on the (dynamic) differences among and between them for formant, phoneme and eventually, word identification and recognition.
Theoretically, when vowels, diphthongs and other phonemes are processed by a multi-channel instrument, their key formant sounds may be managed and resolved by different channels, receiving more or less amplification and compression than was originally present and intended. This possible outcome distorts relationships among formants, and potentially other key features of vowel, phoneme and word recognition.
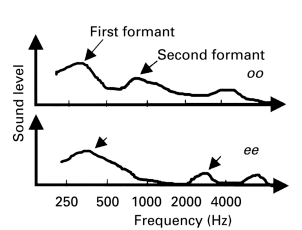
Figure 2. Annotated diagram of vowel spectra (Dillon, 2001) Modified with permission.
Spectral cues in general, are perhaps the most relevant feature for speech reception - distorted spectral coding appears to be related to reduced speech perception in noise, whereas distorted intensity and temporal cues are not (van Schijndel et al, 2001). Therefore, it can be concluded that spectral cues ideally should not be altered or degraded, as would possibly be the case (at least to some degree) in multi-channel hearing instruments (Figure 3).

Figure 3. Schematic of channel splitting versus unified signal processing.
Another consideration is that the number of channels, compression ratios, and their time constants (attack and release times) all interact. Taken to an extreme, a large number of channels with high compression ratios can result in an amplified signal (Plomp, 1988), stripped of many of the identifiable speech elements. This effect is known as "spectral smearing." Because of the distorted formant information, spectral smearing is most deleterious to "place" of consonant articulation (e.g. difficulty discriminating between /b/, /d/ and /g/), and increases susceptibility to noise (Boothroyd et al, 1996).
Boothroyd and colleagues (1996) found that "Spectral smearing with bandwidths of 707 and 2000 Hz elevates phoneme recognition threshold in noise by about 13 and 16 dB respectively" (italics inserted). In addition, spectral smearing has greater degradation on word, rather than phoneme performance due to the non-linear relationship between these two measures. This implies that the real-world deleterious effect on speech-in-noise would likely be extreme.
Spectral smearing is more severe when fast attack and release times are used in conjunction with multiple independent amplification channels.
In fact, spectral smearing alone can reduce phoneme recognition to only 12% (Boothroyd et al, 1996). This finding is consistent with the results of van Schijndel et al (2001) who found that distorted coding of spectral cues was the main factor associated with reduced speech discrimination in noise for hearing impaired subjects. Distorted coding of spectral cues had greater negative impact than did distorted temporal or distorted intensity cue coding. When the input signal is broken into channels, the spectro-temporal characteristics become distorted and important speech transition information is lost, which has been found to impair speech understanding (Boothroyd et al, 1996).
In addition to the impact of multi-channel processing on speech signals, such processing might disturb other signals - in particular music. An important part of music appreciation is the timbre of the musical instruments played. Timbre is generated by the relationship between harmonics of the fundamental frequency at any moment in time. According to the resonances of the instrument, the same pitch, or note, created by the fundamental frequency, is identified as different instruments based on timbre. The timbre brought about by the resonance of different harmonics allows listeners with normal hearing to distinguish between a flute, a piano or a violin, all playing the same note. In a multiple channel instrument the independent action of compression circuits may reduce the contrast between these resonances, reducing the distinctive timbre of the musical instrument and consequently the listener's enjoyment of the sound.
Unified Signal Processing
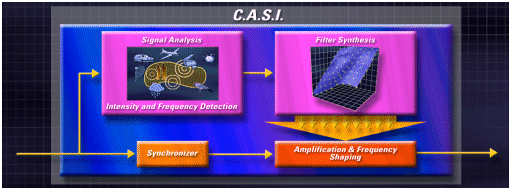
Figure 4. Functional-block diagram of CASI
Discussion:
In light of the concerns above, and with particular attention to the known smearing effect associated with multiple channel amplification, a new signal processing strategy has been developed by Bernafon.
This unique processing strategy satisfies the frequency-specific compressive requirements of sensorineural hearing loss, while retaining the intra-signal spectral contrasts important for formant, phoneme and speech recognition (Figure 4). We refer to this new signal processing strategy as Continuously Adaptive Speech Integrity (CASI).
CASI offers unique frequency shaping for optimal hearing-loss appropriate frequency response curves. Flexible input-dependent filter characteristics are applied to the whole signal, allowing frequency-dependent compression, without splitting the signal into channels and incurring the consequent spectral smearing potentially present in many-channel instruments. In addition, this unified signal processing occurs perceptually instantaneously, with appropriate gain characteristics calculated and applied to each incoming signal.
CASI analyses incoming signals according to their intensity and dominant spectral elements, and calculates the corresponding gain characteristic to be applied. Spectral characteristics of speech are maintained resulting in more "natural" sounding amplification. CASI signal processing allows excellent sound quality for speech and music signals.
Additionally, because CASI maintains the natural signal structure, adaptation time may be less for the patient using CASI than for those using more typical multi-channel amplification (Yund and Buckles,1995). We believe CASI offers the benefits of multi-channel processing, without the above-described drawbacks.
We hope to publish an article discussing the temporal behavior of CASI in the next few months. This additional information will be released to Audiology Online as soon as it is available for further exploration of this technology.
References:
Boothroyd, A., Mulhearn, B., Gong, J. and Ostroff, J. (1996). "Effects of spectral smearing on phoneme and word recognition," J. Acoust. Soc. Am. 100(3), 1807-1818.
Dillon, H. (2001). Hearing Aids (Boomerang, Sydney).
Leek, M.R. and Summers, V. (1996). "Reduced frequency selectivity and the preservation of spectral contrast in noise," J. Acoust. Soc. Am. 100(3), 1796-1806.
Moore, B. C. J. (1998). Cochlear Hearing Loss (Whurr, London).
Pearsons, K.S., Bennett, R.L. and Fidell, S. (1977). "Speech Levels in Various Noise Environments," Environmental Health Effects Research Series. EPA report # EPA-600/1-77-025
Plomp, R. (1988). "The negative effect of amplitude compression in multichannel hearing aids in the light of the modulation-transfer function," J. Acoust. Soc. Am. 83(6), 2322-2327.
Smoorenburg, G. F. (2000). "A physiological basis for hearing aid processing," in Referate des Hörgeräte-Akustiker-Kongresses 2000 (Median-Verlag, Heidelberg).
van Schijndel, N. H., Houtgast, T. and Festen, J. M. (2001). "Effects of degradation of intensity, time, or frequency content on speech intelligibility for normal-hearing and hearing-impaired listeners," J. Acoust. Soc. Am. 110(1), 529-542.
Yund, E.W. and Buckles, K.M. (1995). "Discrimination of Multichannel-Compressed Speech 8in Noise: Long-Term Learning in Hearing-Impaired Subjects," Ear and Hearing 16, 417-427.
Click here to visit the Bernafon website.
