
Learning Outcomes
After this course, participants will be able to:
- Describe the role of noise reduction technology in complex listening scenarios.
- Describe the difference between selective and divided attention.
- Describe the difference between a dual task and a paired comparison task.
Objective
Understanding in noise is more difficult, especially for the hearing impaired, because they do not receive the same signal quality as people with normal hearing. In more complex situations, such as in a restaurant or a cafeteria with more than one talker, it can be especially challenging for hearing impaired people. Of significant assistance for these individuals, is noise reductions systems in hearing aids. The current study compared three high-end hearing aids with different noise reduction schemes, in realistic complex listening scenarios, with one and with three talkers.
Design
The performances of three hearing aids were compared in complex listening scenarios with one and with three talkers. First, the hearing aids were compared on a technical level. Recordings with an artificial head were analyzed by a phase inversion technique to estimate the benefit in SNR compared to an unaided condition. Second, performance measurements with hearing impaired subjects in a complex listening task, where selective and divided attention is required, were done to evaluate the effect on intelligibility and detection. Third, subjects were asked to rate intelligibility and listening effort in a paired comparison to estimate the differences between the systems on a subjective level.
Results
Depending on the condition, the effect on SNR improvement varied between the different noise reduction schemes. These differences in technical SNRs did not result in different performance in a divided attention task. However, on a subjective level, clear differences were evident between the hearing aids. One hearing aid was clearly preferred with regard to intelligibility and listening effort.
Conclusions
On a technical level the SNR benefit was quite different between the different hearing aids. Interestingly, all systems lead to comparable performance results in the complex divided attention scenario. The informative power of the technical SNR estimations seems to be limited. However, on a subjective level, the Phonak device with a spatial noise reduction approach, is clearly preferred.
Introduction
When Abrams and Kihm introduced the MarkeTrak IX study, they showed that one of the most important obstacles to hearing aid satisfaction occurs in situations when the hearing impaired person has to follow a conversation in a restaurant, for example (Abrams and Kihm, 2015). Listening in the presence of such background noise is one of the most important but difficult acoustic situations. In the literature, the so called “cocktail party phenomenon” refers to a similar situation where the focus is on one particular auditory object while ignoring other stimuli. This means that attending to one object or stream is required while filtering out other stimuli. This is called “selective attention”. However, here, we simulated an even more complex situation in which an extra task was added, namely, the constant scanning of other people whether they ask for attention or not. In such a situation, the cognitive resources have to be divided between both tasks (“divided attention”). This is typical for a restaurant situation in a group conversation where the listener has to switch the attention from one talker to the other. It may be that when a conversation begins, listeners share their attention amongst speakers within a group in order to decide which person they most want to listen to or which conversation they would like to join. Once they have decided, they are likely to focus their attention on a single speaker and try to block out the other conversations and noise around them. However, if someone else would like to get their attention, it would still be useful for them to be able to hear speakers coming from other directions. In these typical group conversations, listeners are constantly shifting and focusing attention (Shinn-Cunningham, 2008). This results in a dual task. The listener wants to follow one person (task 1) but still wants to be aware of the other people (task 2). Often the result of such a dual task is that the overall performance is impacted, and one aim of this study was to estimate these dual task costs. The dual task costs indicate the loss of resources that go to the respective other task: Most likely the performance of each task drops when performing both tasks at the same time compared to the case when each task is carried out separately (Halverson 2013, Wagener et al 2018).
In complex, noisy environments such as in a restaurant or cafe, hearing aid users require a more favorable signal-to-noise ratio (SNR) than their normal-hearing peers to achieve the same level of performance (Killion, 1997) and therefore another question of this study was to evaluate whether hearing aids can improve the SNR in these situations. This is important, as we know that the ability to understand speech in noise has been found to correlate with hearing aid satisfaction. According to MarkeTrak IX, the most satisfied hearing aid users feel their hearing aids successfully minimize background noise, are comfortable to wear when listening to loud sounds and improve the ability to tell the direction of where sound is coming from (Abrams & Kihm, 2015).
Phonak implemented an adaptive directional microphone system (UltraZoom) which reduces the noise from the side and behind while keeping the wanted target speaker on focus. Other hearing aid manufacturers have implemented alternative spatial noise processing schemes in order to improve speech understanding. Here we measured the technical benefit in SNR provided by different hearing aid manufacturers compared to an unaided condition in an “Objective SNR estimation” part. The performance and the dual task costs in a complex cafeteria setup was measured in a “divided attention task” and subjective feedback was given by the subjects in a “subjective rating”.
Answers were sought to the following questions:
- How much do hearing aids with spatial noise reduction systems improve the SNR?
- What is the performance of the different hearing aids in a complex listening scenario with more than one talker?
- Do the different spatial noise reduction systems differ in terms of rated listening effort and speech intelligibility in these complex listening scenarios?
Methods
In the methods section we first describe the hearing aids and the cafeteria setup which was used in all three parts of this study.
Hearing aids
Participants were fitted with Phonak Audéo B90-312T (equivalent in performance to Audéo Marvel for the specific aspects tested in this study) hearing aids (in the following HA1), plus two premium hearing aids from two different competitors (in the following HA2 and HA3).
Cafeteria setup
Measurements were conducted in a free-field sound booth in the House of Hearing in Oldenburg, Germany. The booth has a length of 3.5 m, a width of 5 m, and a height of 2.5 m. The KEMAR artificial head and subjects were placed in the middle of a 12 loudspeaker array (Figure 1right side). The array consisted of twelve Genelec 8030B speakers that were connected to RME ADI8 -DS DA converters.
The cafeteria noise was a recording from the cafeteria of the Campus Wechloy of the University of Oldenburg, Germany. It had a very diffuse character with distant fluctuating components. Background noise and speech signals were presented using the Toolbox for Acoustic Scene Creation And Rendering (TASCAR, Grimm et al., 2016). Room acoustics of the cafeteria were modeled and applied to the speech signals. A first-order image-source model was used for the early reflections and a feedback delay network for the diffuse reverberation.
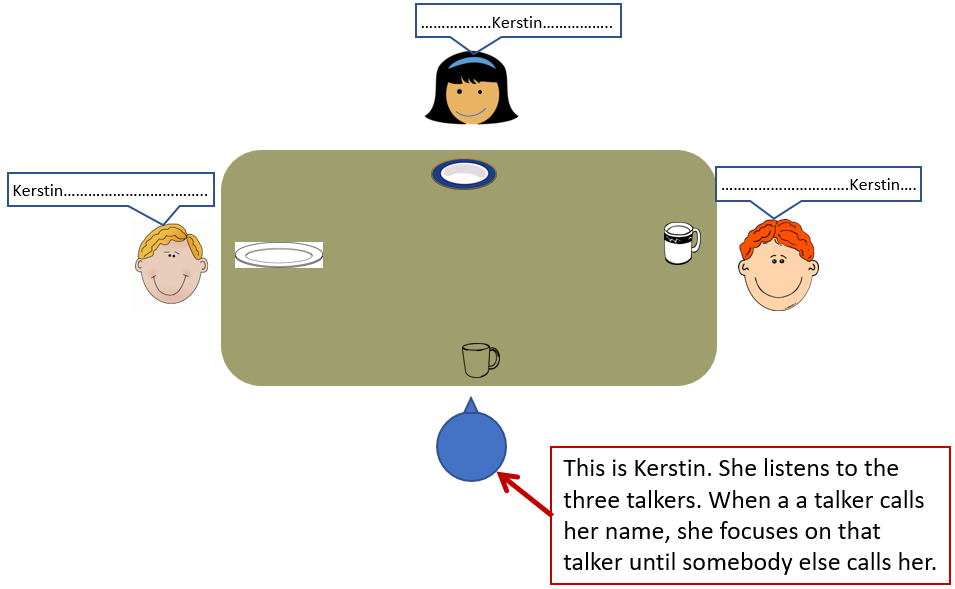
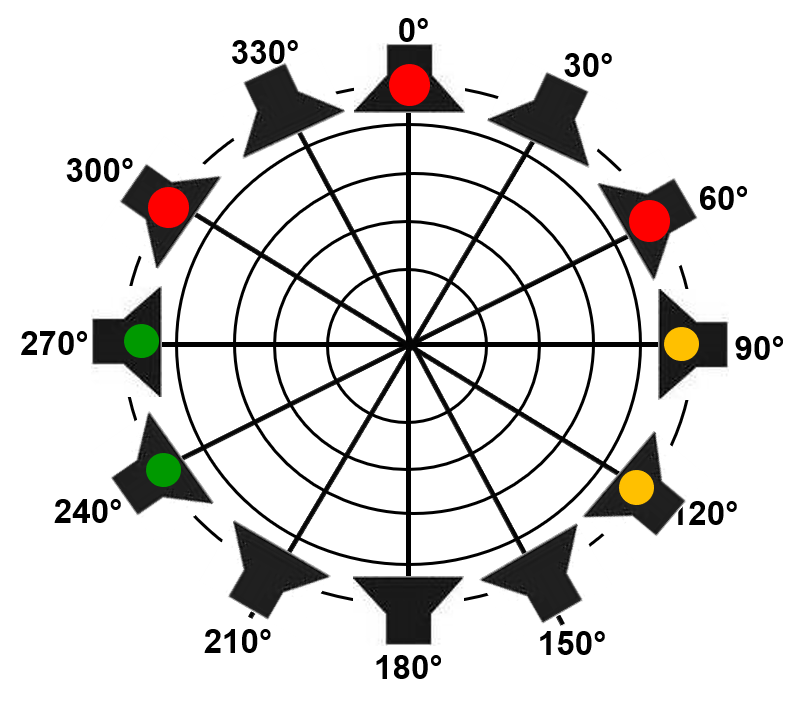
Figure 1. Setup of the cocktail party evaluation. From all loudspeakers a diffuse cafeteria noise, interfering non-target speakers (yellow and green dots) and from -60°, 0° and +60° target speaker (red dots) using the OLSA material was used.
Figure 1 shows schematically the cafeteria setup (left) and the implemented 12 loudspeaker setup in the lab (right). “Kerstin” sat in a cafeteria and spoke to three other people, a woman in front (0°) and two men at -60° and +60°. The corresponding 12 loudspeaker setup on the right side of the figure shows the implementation in the lab where the 3 red dots represented the three people talking to “Kerstin”. The diffuse cafeteria noise was presented from all 12 loudspeakers together with 4 additional interfering speakers (green and yellow dots). The distance of the loudspeakers to the middle of the head of the listener was 128cm.
Objective SNR estimation
To estimate the SNR, the phase-inversion technique first described by Hagerman and Olofsson (2004) was used. As a major goal of hearing aids is to improve the SNR in complex listening situations, the change in SNR provided by different noise reduction systems in comparison to the unaided condition was investigated in this study.
Here the measurement was conducted with two broadband recordings of the output of the hearing aid with an artificial head (G.R.A.S KEMAR artificial head with Torso and Ear Simulator Systems and the KB5000/KB5001 anthropometric pinnae, see also Figure 2): One recording with the original scene with speech in noise (A) and the other with original speech signal and in phase-shifted (by 180°) noise (B). The sum of the two recordings [SPEECH=(A+B)/2] cancels noise, leaving an estimate of the speech present. The difference between the two output recordings [NOISE=(A-B)/2] cancels speech, leaving an estimate of the noise. The comparison of SPEECH and NOISE allows calculating the output SNR. This output SNR may be compared to the input SNR or with the unaided output SNR as suggested by Bray et al (2005). In this study we compared the output SNR with hearing aids to the situation without hearing aids (unaided). An important prerequisite for this technique is that the hearing aids are programmed without compression. This means that the SNR estimation might be artificial and cannot directly be compared to real life.
| Figure 2. This figure shows the anthropometric pinnae of the KEMAR and the coupling of a hearing aid with power domes attached to the external receivers. |
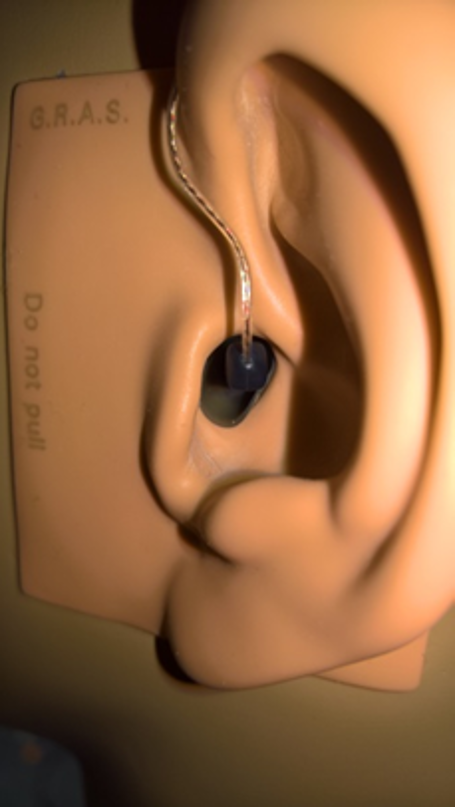
Fitting. For the objective measurements the hearing aids were fitted according to NAL-NL2 using coupler measurements with the Siemens Unity 2, and the Unity target curves for NAL-NL2 using the ISTS Signal (Holube et al., 2019). The hearing loss was set between N3 and N4 according to Bisgaard et al. (2010). A linear fitting for the SNR–tests was used. The major goal of a NAL-NL2 fit was to have comparable gain settings in all hearing aids. Therefore, the fitting was performed several times until a good match of all curves was achieved. Double domes were used to couple the devices to the artificial head (see also Figure 2).
Recordings. For the recordings, running speech was used for the three target speakers. One male and two female talkers from the positions -60°, 0° and +60° each (red dots in Figure 1right part). Two different SNR conditions were investigated: A condition with speech and background noise at 65 (S65N65) and a situation where the talkers were 10 dB louder (S75N65) to simulate a situation with a positive SNR. The situation S65N65 means that each of the three speakers spoke at a level of 65dB. The overall level of all three target speakers was approximately 4.8 dB higher.
Divided attention task
Participants. In the performance measurements and in the subjective paired comparison evaluations, 30 experienced hearing aid users with moderate hearing loss (Figure 3) were included. Four subjects had hearing aids from the same manufacturer as the HA1 device, 10 had hearing aids from the same manufacturer as HA2 and 6 used hearing aids from manufacturer of HA3. The other ten subjects used hearing aids from other manufacturers. Participants ranged in age from 44 to 86 years (mean age was 72.6 years). They had normal cognitive values which were assessed via the ‘DemTect’ test (m = 15.8; SD = 2.0; min = 12; Kalbe et al., 2004) and reported normal head-movement abilities.
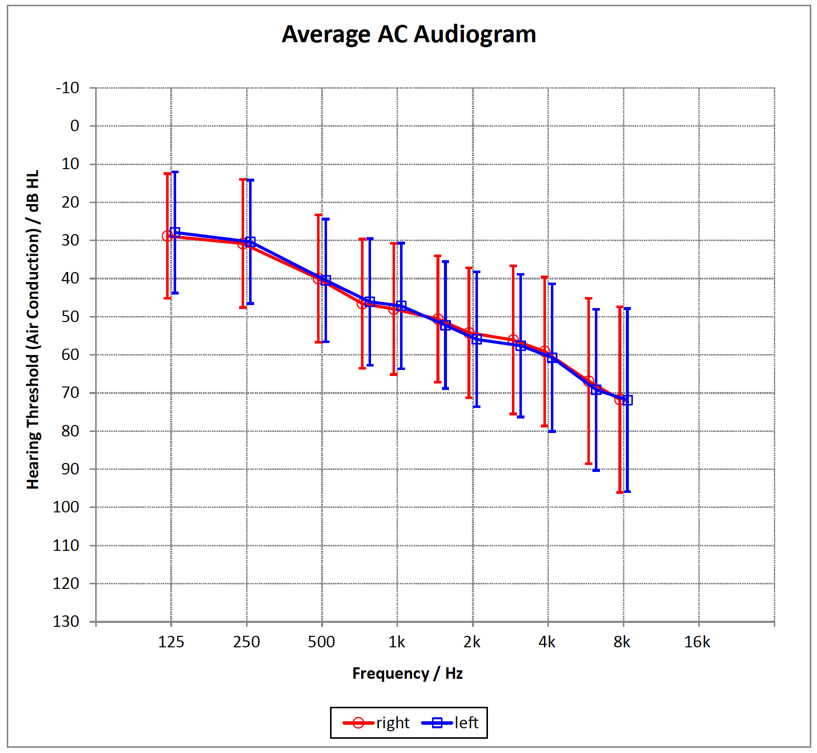
Figure 3. Mean hearing loss of the 30 subjects (error bars show the standard deviation).
Fitting. Hearing aids were fitted to the manufacturer’s default fitting formula and fine-tuning was only conducted if necessary (only overall gain was adjusted where subjects asked for it). Phonak devices were programmed with AutoSense OS. AutoSense OS is the automatic system from Phonak. Here AutoSense OSclassified the scene described below as Speech in Noise with UltraZoom being active. The competitive devices were also programmed with their automatic programs. Occluded SlimTips were used for all devices.
The task. For the divided attention test the target talkers were alternately speaking sentences of the Oldenburg sentence test (OLSA), which is a German matrix speech recognition test (Wagener et al., 1999). OLSA sentences have the structure, name-verb-numeral-adjective-object, and are composed from a set of ten words per category. The name „Kerstin” was defined to be the attention trigger, meaning a call for the participant’s attention. Thus, the occurrence of the word „Kerstin” indicates which of the talkers is the target, until „Kerstin” is spoken the next time. Participants were instructed to immediately repeat the last word of all sentences of the target talker during the ongoing presentation. The alternating presentation of sentences from the three talkers was timed with a defined overlap of 0.6 s. This way, the occurrence of the attention trigger „Kerstin“ and the target words for recognition were presented at the same time, resulting in a divided attention dual task.
In the same scenario, the two tasks were also measured as two different single-tasks: A “speech recognition” task for a fixed target speaker and trigger “detection” task without last word recognition. Comparing the results for single tasks and dual tasks yields the influence of divided attention on speech recognition.
For the first male talker (at -60°), speech recordings of the standard male OLSA were used (Wagener et al., 1999); for the female talker (at 0°) the standard female OLSA speech material (Wagener et al., 2014), and, for the second male talker (+60°) the multi-lingual OLSA was used (Hochmuth et al., 2015). Nominally, each talker’s speech was presented at 68 dB. The paradigm was defined for talkers with equal intelligibility. Signals were presented within the cafeteria scenario which was also presented at 68 dB.
For the divided attention task, participants were seated in the center of a horizontal loudspeaker array on a rotatable office chair. During the measurements, the experimenter was sitting behind the 0° loudspeaker with a touchscreen to enter the answers.
Subjective rating
The same subjects as mentioned above rated the different hearing aids in a paired comparison test, to assess ratings with regard to subjective intelligibility, listening effort and preference. For this test, the virtual hearing aid concept was applied (Helbling et al. 2013). The virtual hearing aid concept consists of 2 steps: (1) in situ recordings were made with the three hearing aids under investigation fitted to the individual participant’s ears (see fitting in divided attention task). (2) These recordings were played back to the participants via insert earphones.
The task of the participants was to directly compare the recordings of two hearing aids at a time (paired comparison). Among other attributes, subjective speech intelligibility (‘With which hearing aid can you better understand the female speaker?’), listening effort (‘With which hearing aid is it more effortful to follow the female speaker?’), and overall preference (‘Which hearing aid do you prefer’). These attributes were rated only in relation to the female voice at 0°. The recordings done with the head facing towards 0°were used to represent selective attention (Figure 4left). The recordings with the head facing -60°represented divided attention (Figure 4right). The latter is only a rough approximation, since although the male voice was present at the front, the subjects knew in advance that they only had to rate the female voice. Therefore, they did not need to “divide” their attention, but were able to focus in that direction all the time.
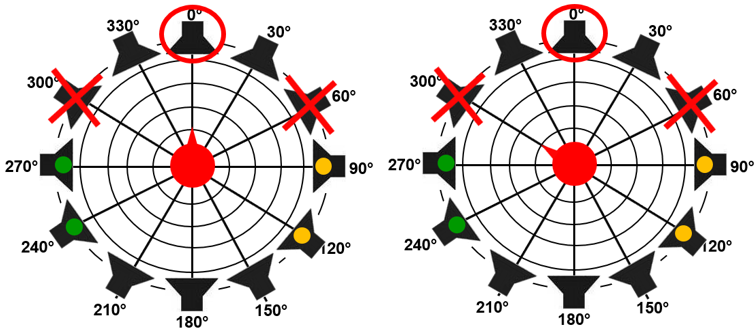
Figure 4. Setup for the paired comparison test: Cafeteria noise was presented from all 12 loudspeakers simultaneously. In addition, OLSA speech material was presented from the speakers marked with a red cross (male voice, signal defined as interferer) or circle (female voice, signal defined as target). The scene on the left where the participant faces and focuses on the female speaker at 0° represents selective attention. The scene on the right where the participant faces -60° but focuses on listening to the female speaker at 0° represents divided attention. Green and yellow dots symbolize additional distracting talkers.
Results
Objective SNR estimation
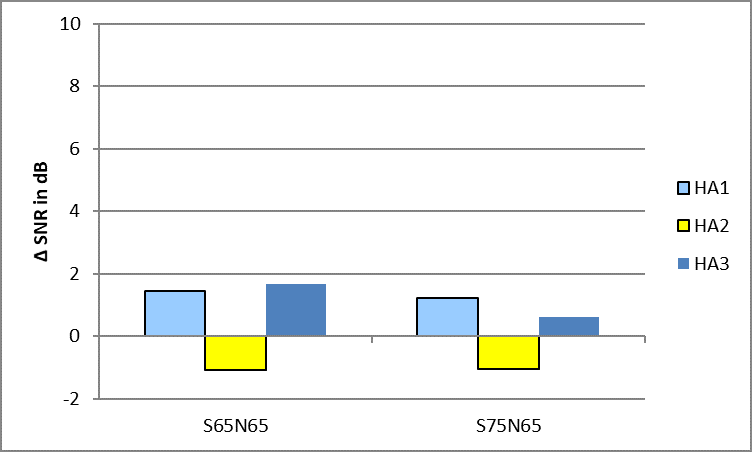
Figure 5. Results of the SNR estimation for one speaker at 0° as target. Results are shown for the two conditions S65N65 and S75N75. The SNR is shown as a benefit compared to the unaided condition.
Figure 5 shows the results for the objective SNR estimation. To quantify the effect of any signal processing in the hearing aids, the SNR of the aided signals were compared with the unaided signals recorded via the artificial head. In the case that just the frontal speaker is defined as the target and the lateral speakers are defined as interferer, the benefit is about 1.5 dB for HA1 and HA3. For the HA2, the benefit is negative meaning that the hearing aid technically reduces the SNR of the unaided signal. The reason for these results: the suppression of the speakers at -60° and +60 (meaning their acoustical energy) is only limited due to the broader beam of the spatial noise reduction schemes of the different hearing aids.
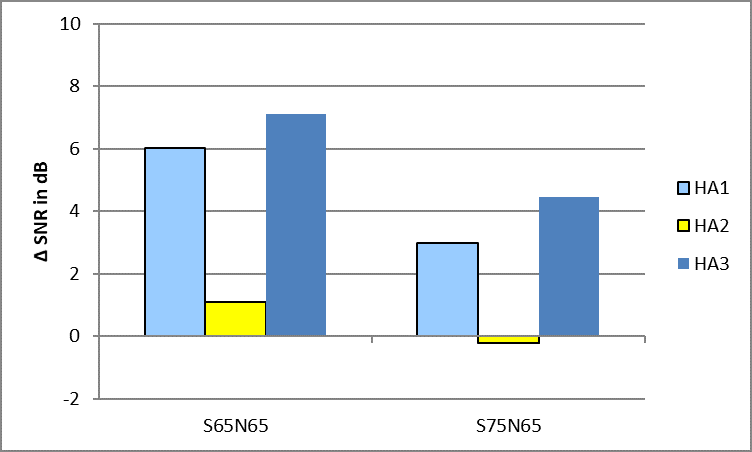
Figure 6. Results of the SNR estimation for three speakers at -60°, 0° and +60° as target. Results are shown for the two conditions S65N65 and S75N75. The SNR is shown as a benefit compared to the unaided condition.
In the case that all three talkers are defined as target signals, the SNR benefit turned out to be much higher for each hearing aid (Figure 6). Interestingly, not only the absolute benefit but also the difference in benefit between the hearing aids is increasing. In Figure 5 the difference between the best and worst SNR benefit is about 2.5 dB whereas in Figure 6 the difference is twice as large (about 5 dB).
Divided attention task
The SNR estimation showed technical differences in SNR benefit between the hearing aids. However, the question arises whether these differences have an impact on the performance in a realistic setup? To answer this question a realistic divided attention paradigm was implemented.
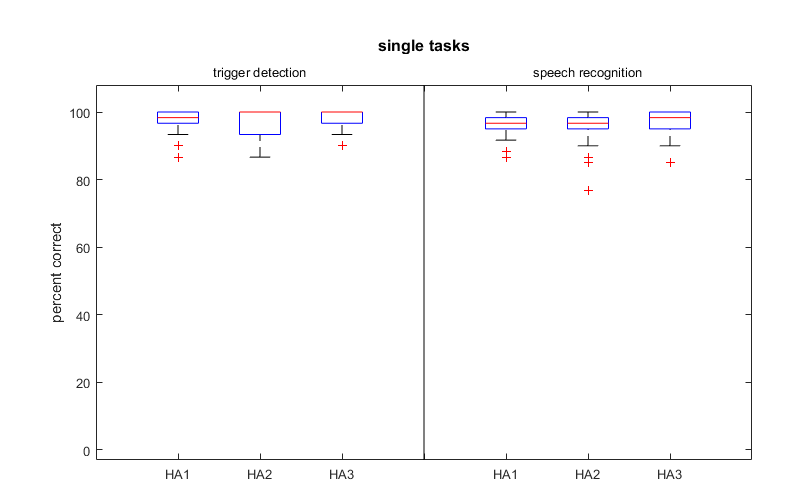
Figure 7. Results for the singles tasks (boxplot with medians and interquartile ranges).The left graph shows the results for the detection task in % correctly identified triggers and the right shows the number of correctly recognized words in %.
Figure 7 shows the results for the two single tasks “detection” and “speech recognition” separately. In the detection task subjects had to listen to all three speakers with the goal to answer from which direction they heard the trigger word “Kerstin”. In the speech recognition task they had to focus just on one speaker and repeat the last word of each sentence. The results indicate that all participants were able to perform the tasks almost perfectly with all hearing aids. No significant differences occurred.
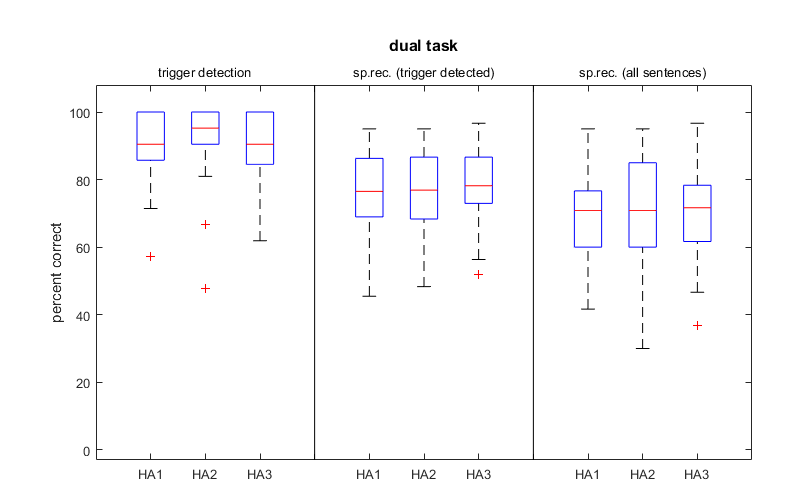
Figure 8. Detection and recognition results in the dual task condition. The left side shows the results for the detection task in % correct detections. In the middle, only the % recognized words when the trigger was detected is shown and the right shows the overall number of correctly identified words in %including answers that were incorrect due to missed triggers.
In Figure 8 the dual task data are shown. Like in the single tasks, most of the participants had only minor difficulties to perform the trigger detection. A large difference compared with the single task was found for speech recognition. While participants were able to perform almost 100% correct in the single task, the dual task values for speech recognition (trigger detected) range from 45-96%, with medians around 80% for all hearing aid conditions. The total speech recognition performance, including answers that were incorrect due to missed triggers, is between 30% and 96%, with medians of 70-72%. No significant differences between the hearing aid conditions were measured.
Subjective ratings
The test devices have been directly compared in a complete and fully randomized paired comparison (i.e. the order in which the pairs were presented was randomized, and within pairs the order in which devices were presented was randomized, too) according to a couple of dimensions. Figure 9 shows the results of this test when the subjects were rating subjective speech intelligibility. HA1 is rated significantly better than HA2 for both selective and divided attention, whereas HA1 is better than HA3 for both attention conditions as well, but the difference is not significant.
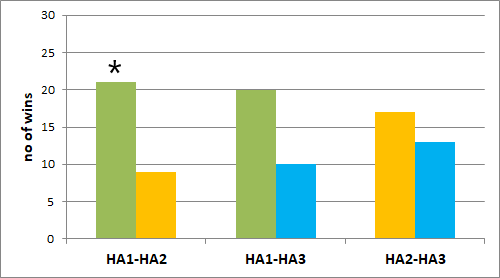
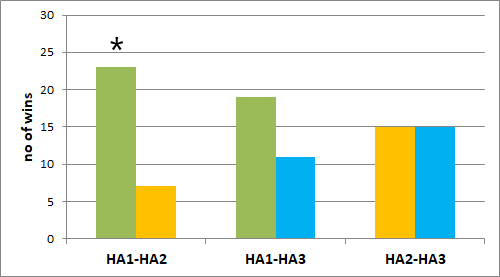
Figure 9. Listening Subjective speech intelligibility (paired comparison), displayed as the number of participants who preferred the respective hearing aid of the given pairs. The graph on the left is for the selective attention condition (head facing 0°) and the graph on the right is for the divided attention condition (head facing -60°). * = significant difference (p<0.05).
Figure 10 shows the results of the paired comparison test with respect to listening effort. The HA1 required significantly less listening effort than both other test devices when focusing on the speaker to the front (selective attention condition). When listening to the speaker at -60° (divided attention condition), HA1 also required less listening effort than both other test devices but the difference was only statistically significant when HA1 was compared to HA3
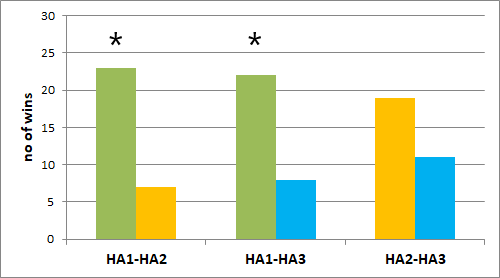
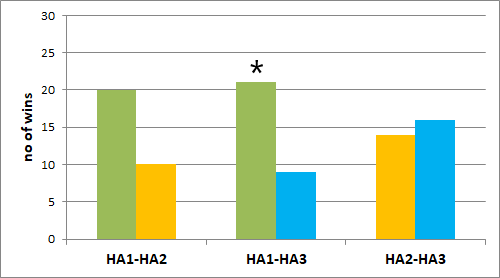
Figure 10. Listening effort (paired comparison), displayed as the number of participants who preferred the respective hearing aid of the given pairs in terms of less listening effort. The graph on the left is for the selective attention condition (head facing 0°) and the graph on the right is for the divided attention condition (head facing -60°). * = significant difference (p<0.05).
The results for the overall preference rating are shown in Figure 11. The results were not significant but at least on a descriptive level, HA1 was preferred by most participants when compared to HA2 and HA3.
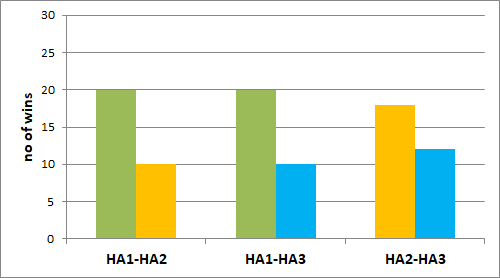
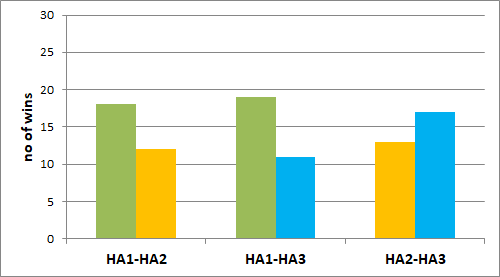
Figure 11. Overall preference (paired comparison), displayed as the number of participants who preferred the respective hearing aid of the given pairs in terms of overall preference. The graph on the left is for the selective attention condition (head facing 0°) and the graph on the right is for the divided attention condition (head facing -60°). No significant difference (p<0.05) occurred for the overall preference.
Discussion
The goal of this study was to compare different noise reduction schemes in three different premium hearing aids. This was done on a technical level, on a performance level and with subjective assessment. An important aspect of this study was the selected sound scenario. A cafeteria or restaurant scenario was chosen, as this is still one of the most challenging and important situations for hearing impaired people even when fitted with hearing aids. Typical levels for such situations are described. in Hodgson et al (2007). They measured the equivalent sound pressure levels in ten different eating establishments which vary from 55.3 to 74.5 dB (A). In the students’ cafeteria they measured 69.8 and 70.4 dB (A), which shows that the selected levels were ecologically valid.
The objective evaluations showed that the SNR benefit is limited for all hearing aids when two lateral speakers at -60° and +60° are defined as interferer. The spatial noise reduction systems are not able to fully suppress these interferers. The technical SNR benefit is even negative for one hearing aid, meaning that the hearing aid technically reduces the SNR compared to an unaided situation. However, in a situation where all of the three talkers are defined as being interesting, the spatial noise reduction is much more beneficial (about 5 dB SNR improvement). Even in situations with an already positive SNR (right bars in Figure 6 with S75N65) the noise reduction can further improve the SNR, which might be very useful in terms of listening effort in situations that are typical of real life.
An important prerequisite for the SNR estimation according to Hagermann & Olufsen (2004) and Bray and Nilson (2005) is that the hearing aids are programmed without compression. This means that the SNR estimation might be artificial and cannot be compared directly to real life. This might lead to a mismatch between objective and subjective measurements as the subjective measurement has to be conducted using compression due to the reduced dynamic range for the participants. Therefore, the hearing aids were fitted with the manufacturers’ default fitting strategies for the subjective measurements.
In contrast to the objective SNR estimations, no clear differences were evident in the detection and recognition performance between the three hearing aids. The dual task costs are quite evident when the recognition scores of the single task are compared to the dual task recognition scores. Even when the trigger words were correctly detected, the recognition score dropped by about 20%. It seems that it is much more difficult for hearing impaired people to follow a conversation when the attention has to be divided and cannot be focused to just one talker. There were no differences in the dual task costs between the hearing aids, showing that they all lead to similar results. However, as only the last word had to be remembered in the divided attention task, it might be that the method was not sensitive enough to reveal the differences between the systems.
In subjective preference ratings, subjects clearly preferred the Phonak device (HA1) with regard to intelligibility, listening effort and overall preference. As it was not possible to implement a real divided attention situation in these paired comparison conditions, the result cannot be compared directly to the divided attention performance task. However, they still show that both, when the speaker is directly in front and also if the speaker is at the side, the Phonak device seems to be beneficial.
Conclusion
The objective SNR estimations showed quite varied benefits between the different hearing aids. However, all systems led to comparable performance results in the divided attention task. It might be that the informative power of the technical SNR estimations is limited for these kinds of noise reduction schemes especially because of the need to fit the hearing aids in a linear mode. The dual task costs in the divided attention task were quite evident. The reduction in overall performance of about 20% shows that this is a relevant effect which needs further attention in the future. Interestingly, on a subjective level, clear differences came to light. The Phonak device with a spatial noise reduction approach was clearly preferred.
Acknowledgments
The authors would like to thank Müge Kaya from Hörzentrum Oldenburg GmbH for her support in conducting the experiments.
Conflict of Interest Declaration
The authors declare that there is no conflict of interest. However, please note that the hearing aid algorithm used for testing in the current study is integrated in commercially available hearing aids. The study received financial support by Sonova AG and one of the co-authors is employed by Phonak AG (ML).
References
Abrams, H. B., & Kihm, J. (2015). An introduction to MarkeTrak IX: A new baseline for the hearing aid market. Hearing Review, 22(6), 16.
Bisgaard, N., Vlaming, M. S., & Dahlquist, M. (2010). Standard audiograms for the IEC 60118-15 measurement procedure. Trends in amplification, 14(2), 113-120.
Grimm, G., Kollmeier, B., & Hohmann, V. (2016). Spatial acoustic scenarios in multichannel loudspeaker systems for hearing aid evaluation. Journal of the American Academy of Audiology, 27(7), 557-566.
Hagermann B., Olufsen A. (2004). A Method to Measure the Effect of Noise Reduction Algorithms Using Simultaneous Speech and Noise. Acta Acustica united with Acustica 90(2):356-361
Bray, V., & Nilsson, M. (2005). A new definition for modern hearing aids. AudiologyOnline, Article 1036. Retrieved from https://www.audiologyonline.com
Helbling T., Vormann M., & Wagener K. (2013). Speech priority noise reduction: A digital noise reduction preference study. Hearing Review, 10(11), 34-43.
Hochmuth, S., Jürgens, T., Brand, T., & Kollmeier, B. (2015). Talker- and language-specific effects on speech intelligibility in noise assessed with bilingual talkers: Which language is more robust against noise and reverberation? International Journal of Audiology, 54(2), 23-34.
Hodgson, M., Steininger, G., & Razavi, Z. (2007). Measurement and prediction of speech and noise levels and the Lombard effect in eating establishments. The Journal of the Acoustical Society of America, 121(4), 2023-2033.
Kalbe, E., Smith, R., Passmore, A. P., Brand, M., & Bullock, R. (2004). DemTect: a new, sensitive cognitive screening test to support the diagnosis of mild cognitive impairment and early dementia. International Journal of Geriatric Psychiatry, 19(2), 136-143.
König, G., & Appleton, J. (2014). Improvement in speech intelligibility and subjective benefit with binaural beamformer technology. Hearing Review, 21(11), 40-42.
Shinn-Cunningham, B. (2008). Objective-based auditory and visual attention. Trends in Cognitive Sciences, 12(5), 182-186.
Wagener, K. C., Hochmuth, S., Ahrlich, M., Zokoll, M. A., & Kollmeier, B. (2014). Der weibliche Oldenburger Satztest 17th annual conference of the DGA Oldenburg, CD-Rom.
Wagener, K. C., Brand, T., & Kollmeier, B. (1999). Entwicklung und Evaluation eines Satztests in deutscher Sprache III: Evaluation des Oldenburger Satztests. Z Audiology, 38(3), 86-95
Wagener, K. C., Vormann, M., Latzel, M., & Mülder, H. E. (2018). Effect of Hearing Aid Directionality and Remote Microphone on Speech Intelligibility in Complex Listening Situations. Trends in hearing, 22
Citation
Schulte, M., Latzel, M., Heeren, J., & Vormann, M. (2019). Noise reduction systems in complex listening situations. AudiologyOnline, Article 25937. Retrieved from https://www.audiologyonline.com




