
Learning Outcomes
After this course learners will be able to:
- Describe why background noise can impact speech understanding and patient-specific contributing factors.
- Describe the common levels of background noise and how this impacts speech understanding.
- Describe the improvements in satisfaction for understanding speech in background noise when hearing aids are used.
- Describe four different fitting issues that need to be attended to in order to ensure maximum benefit for understanding speech in background noise.
- Describe three recent hearing aid innovations that have helped speech understanding in background noise.
- Describe the advantages of split-band dual-stream processing.
V1.1: Some Background on Background Noise
What is background noise? It depends. The answer might be quite different if you ask someone in physics vs. astronomy vs. psychology. While we recognize that some background noises are desirable, soothing and relaxing, in the world of audiology we usually associate the term with a signal that is annoying, and/or impairs speech understanding. The impact of noise on speech understanding has been studied extensively by hearing scientists, going back to the early telephone work at Bell Labs.
Talker vs. Background Noise Level
We’ve all been in conversations where the background noise varied in intensity, and we usually change the intensity of our voice accordingly, in an attempt to maintain a positive signal-to-noise ratio (SNR) that allows for speech understanding. Research has shown, however, that this is not a linear relationship. The increase in the talker’s voice fails to equal the increase in the background noise, and therefore, in a typical conversation, as the noise goes up, the SNR becomes more adverse (Pearsons et al, 1977). As shown in Figure 1, when the noise is at average speech levels (55-60 dB SPL), the SNR is about +5 dB, a level which would be adequate for most with normal hearing, or even those with a mild-moderate hearing loss. But once the noise reaches 75 dB SPL, the talkers voice will start falling below the noise (SNR=- 1 dB), making communication very difficult, even for a young person with normal hearing. In conversations in background noise, therefore, this reduced audibility from the talker facilitates the masking effect of the noise.
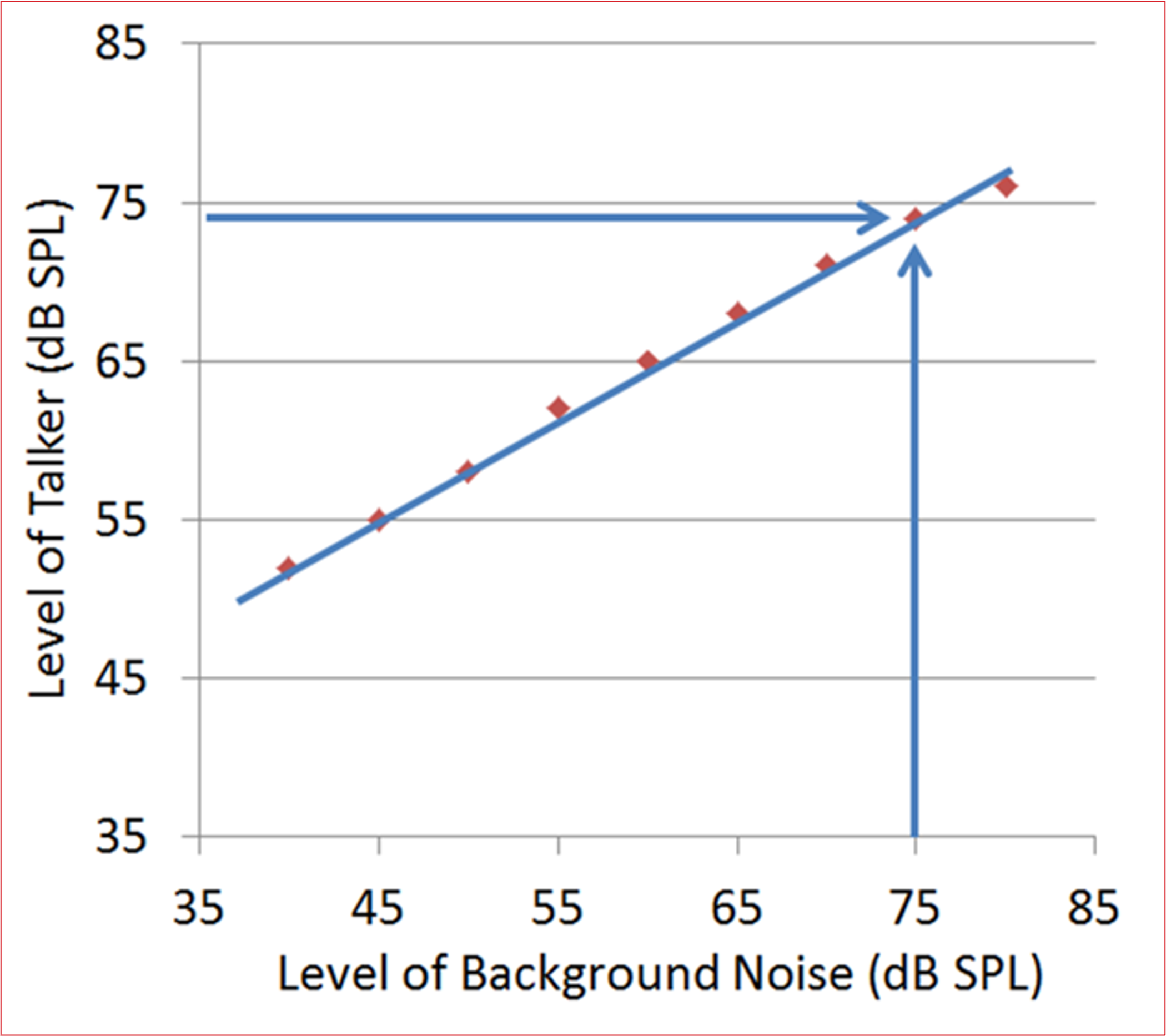
Figure 1. An illustration that when background noise increases, talkers do not raise their voice at the same rate, and the result is a poorer signal-to-noise ratio, reaching a negative value ~75 dB SPL (Based on data from Pearsons et al, 1977).
The Type of Noise Matters
While background noise often is simply referred to as “noise,” there actually are two different types, which affect speech understanding in different ways, as they have different masking effects. As reviewed by Mueller et al (2014), the first of these, energetic masking occurs when the neural excitation evoked by the competing signal (background speech or noise or both) exceeds the excitation produced by the target speech—for the most part, the masking effect is the energies and the synchrony of the energies of the two signals. You can think of energetic masking as the same principle as when narrow-band noise is used to mask out a cross-over signal while conducting pure-tone audiometry. In the real-world, an example would be someone trying to understand speech when a loud HVAC system or some motorized appliance like a vacuum is in use. In general, energetic masking is low frequency.
There is a second type of masking that will cause an additional interference, or interference independent of energetic masking, which also serves to reduce speech understanding. This is referred to as informational masking (also perceptual or central masking). As the name suggests, this type of masking has informational content, but in most cases, also has an energetic effect. This would be the masking effects of trying to understand someone, with the TV playing or when there is a second talker nearby. In this case, speech becomes noise, as it’s not the speech we want to hear, and it’s an effective masker as the speech spectrum is matched. Moreover, the brain will detect meaningful components from this background signal, interfering with the content of the target speech.
The real-world combination of informational and energetic masking that we commonly experience is party noise—so much so that a much cited research article from the 1950s dubbed this the “cocktail party problem,” although the concern at the time was not cocktail parties, but centered on air-traffic controllers understanding simultaneous messages from pilots over loudspeakers in the control tower (Cherry, 1956). Laboratory studies have shown that speech understanding is the poorest when both energetic and informational masking are present, and not surprisingly, this also is when hearing aid benefit is the poorest (Hornsby et al, 2006).
The Impact of Hearing Loss
It is reasonable to assume that when hearing loss is present, the deleterious effects of background noise is greater, and this has been supported by considerable research over the years.
The one-two punch that background noise and hearing loss delivers to speech understanding perhaps can be understood best by applying the Speech Intelligibility Index (SII). For our example, we’ll use the Killion-Mueller SII count-the-dot audiogram (Killion & Mueller, 2010). This specially-designed audiogram has the “speech banana” represented by 100 dots; the number of audible dots is the SII. The density of the dots is consistent with the importance function of that frequency for understanding speech (e.g., more dots in the 1500-3000 Hz region than in the lower frequencies and very high frequencies). We can use the SII to predict speech understanding for different speech materials—for this example we’ll use the performance-function for understanding words in sentences, a good metric to determine how well a person can follow a conversation.
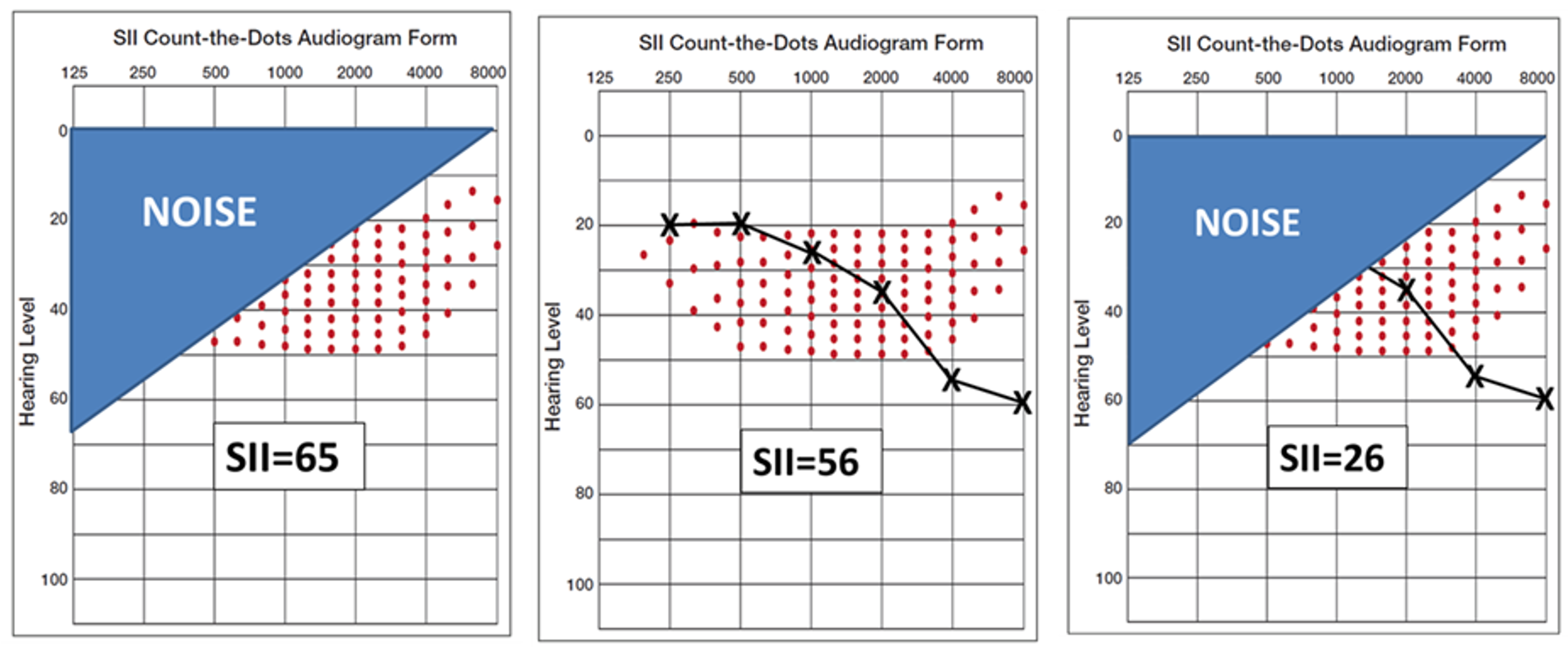
Figure 2. Example of how hearing loss and background noise can combine to reduce the Speech Intelligibility Index (SII).
Shown in the far left panel of Figure 2, is a simplified version of the impact of a background noise, predominantly low-frequency, on speech audibility. The resulting SII is .65—this is adequate for nearly 100% understanding of words in sentences. In the middle panel, we see that a common mild-to-moderate downward-sloping hearing loss will reduce the SII to .56—this is still adequate to understand >90% of words in sentences. But in the far right panel, we see the effects when this person with only a mild hearing loss is in background noise. The SII is now .26—a value that would result in only about 40-45% understandings of words in sentences, probably not good enough to follow a conversation.
The Impact of Aging
It is well understood, that speech understanding in background noise is poorer for the elderly. This primarily is due to one basic factor—elderly people have more hearing loss. But there are other factors that also contribute. As people age, structural and neural degeneration occurs throughout the auditory system. For example, binaural separation of signals becomes poorer, an important process for difficult listening situations. Moreover, cognitive decline can impact speech understanding. This includes processing involving working memory, attention, perception and executive function. A decline in these areas also can increase listening effort and cause listening fatigue, directly or indirectly impacting speech understanding for difficult tasks.
“Hidden” Hearing Loss
There is another group of individuals who have difficulty understanding speech in background noise, who are not elderly, and characteristically have normal pure-tone thresholds. Because of the normal hearing acuity, this has sometimes been referred to as a “hidden” hearing loss. One cause of this which has been studied extensively is cochlear synaptopathy—that is, cochlear synapses that were lost from noise exposure, aging, some form of ototoxicity, or their function was altered or disabled due to genetic mutation (Kujawa, 2017). There also are many other potential causes, such as central auditory processing disorders, cognitive decline or early dementia.
Survey results vary, but in general, it appears that approximately 10-20% of individuals with normal hearing thresholds report hearing difficulty (Temblay et al, 2015). Given that hearing sensitivity is normal, we assume that this mostly is related to understanding speech in background noise. While the research is limited, fitting hearing aids to these individuals with normal hearing thresholds has been found to be moderately successful (Roup et al, 2018).
A link to Dementia
In the past few years we have seen evidence revealing the association between hearing loss and dementia, and in fact, of the modifiable factors related to dementia, the treatment of hearing loss ranks the highest, 25% of the total (Livingston et al, 2020). Importantly, however, factors related to dementia are not necessarily factors that cause dementia. These findings need to be interpretated cautiously.
While not known precisely, it is believed that the relationship is because of changes in brain processing when optimum audibility is lacking, potential changes in brain structure, and the well-known social isolation that often accompanies individuals with hearing loss. Recently, data has emerged showing that poor speech understanding in background noise also is related to the increased probability of dementia (Sevenson et al, 2021).
Health data from more than 82,000 participants over the age of 60 were studied by experts from the University of Oxford who were looking for dementia risk factors. At the beginning of the study, participants were asked to identify spoken numbers against a background of noise. Based on this test they were grouped by the researchers into normal, insufficient and poor speech-in-noise hearing. Over 11 years of follow-up, it was found that insufficient and poor speech-in-noise word recognition was associated with a 91% increased risk of developing dementia, compared the group with normal performance on this test (Sevenson et al, 2021).
It is probable that many of these individuals also had hearing loss, but it also is likely that some did not. It could be that there was underlying auditory processing issues, and/or the inability to understand speech in noise prompted social isolation, even for those with normal hearing.
V1.2: How Big is the Problem?
As we have just described, there are many factors that impact the overall problem of understanding speech in background noise. One then might ask, how big of a problem is this issue? That’s an easy one to answer: A big problem. Perhaps the largest sample that we have of clinical speech-recognition-in-noise testing are the data published by audiologist Richard Wilson for 3430 veterans (6% had normal hearing) (Wilson, 2011). He reports that of the 3291 that were evaluated with the words-in-noise (WIN) test for both ears, only 7% exhibited normal performance (50% correct point of ≤6 dB SNR). This certainly is consistent with what commonly is reported by our patients. Interestingly, but not surprising, 50% of these individuals had speech-in-quiet scores (NU-6) of 90% or better. This illustrates the obvious—we only know about the problem clinically if we do the appropriate testing.
Common Speech Levels
Given that our primary concern regarding background noise is how it impacts the understanding of speech, it’s meaningful to first review the average (dB SPL) levels of speech that occur in normal conversations. This is shown in Figure 3 below.
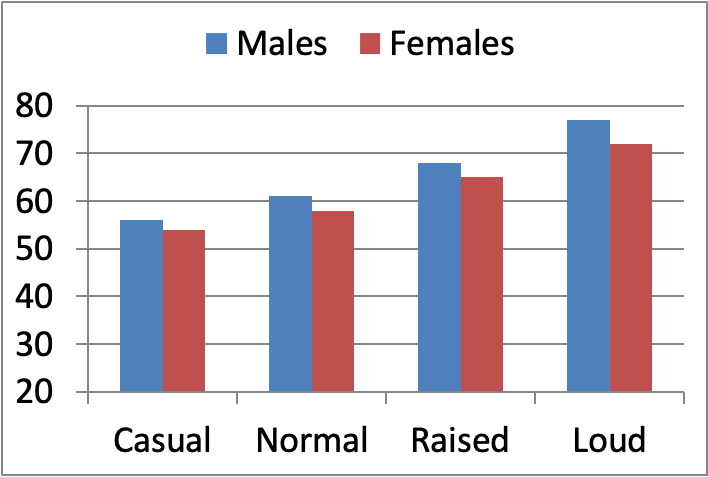
Figure 3. Average dB SPL (unweighted) levels of talkers at four different levels measured at a distance of 1 meter (based on data from Pearsons et al, 1977).
Shown in the above Figure 3 are the average dB SPL (unweighted) values for male and female voices, measured at a one meter distance from the talker (Pearsons et al, 1977). The differences between the male and female voices are consistent, but not large. As mentioned, these values are from a distance of one meter; many conversations take place at a distance greater than this, and in theory, the dB level would go down by 6 dB as the distance doubles.
It sometimes is tempting to think of a given speech signal such as average speech (which is around 60 dB SPL), of having a “flat” frequency response—that is, a level around 60 dB for all frequencies. This notion has been propagated by the conversion of SPL to HL for display on the audiogram, in which case, the intensities across frequencies are relatively equal. In the real world of person-to-person conversations, we of course are concerned with SPL, not HL, and the spectrum is far from flat. The speech spectrum shown in Figure 4 is that of the International Speech Test Signal (ISTS; overall level of 65 dB SPL) which has been shaped to represent the International Long-Term Average Speech Spectra (ILTASS) (Holube, 2015).
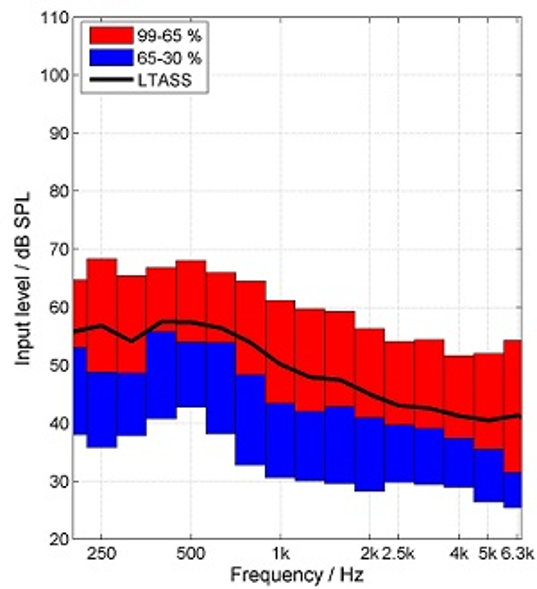
Figure 4. The International Speech Test Signal (ISTS; overall level of 65 dB SPL) which has been shaped to represent the International Long-Term Average Speech Spectra (ILTASS). Percentiles also are displayed (from Holube, 2015).
Note that while the overall level for this measurement was 65 dB SPL, the greatest average output (LTASS) at any single frequency is 58 dB SPL (e.g. ~500 Hz), and in the higher frequencies (e.g., 2000-4000 Hz), the output is no more than 40-45 dB SPL. This clearly explains why it is so easy for background noise to mask out these high frequency components of speech, vitally important for speech understanding.
Levels of Background Noise
Noise is all around us, and in many cases the level is equal to or exceeds that of average speech. Consider the level of noises commonly heard around the house that could interfere with conversations: washing machine=55 dBA, dishwasher=58 dBA, hand-held mixer/blender=69 dBA, vacuum cleaner=72 dBA and hair dryer 77 dBA. What is of primary concern, however, to most people with hearing loss is not noises around the house, but the background noise that is present for many social situations, most commonly restaurants. While this might only make up a small percent of the patient’s total listening experiences, it often does make up a very large percent of the patient’s important listening situations. Inability to understand in these critical environments often leads to reduced socialization, which has been linked to progression of dementia.
If we look at the research regarding the noise levels of restaurants, it is clear why this atmosphere often creates an unfavorable listening experience. One study assessed noise levels in 30 restaurants in Orlando, FL, during a busy time of the day, usually the evening dinner hour (Rusnock et al, 2014). More than ½ of the restaurants had average noise levels over 75 dBA, and 5 (16%) had significant portions of their noise level above 80 dBA, with maximum SPLs over 85 dBA. Only 7 (23%) had significant portions of their SPL range below 70 dBA—a level that probably would allow for people to converse in normal or near-normal conversational levels. All 7 of the latter group were counter-service, only partially full, and did not have a bar—not a typical destination for a social dinner with friends.
Common Real-World SNRs
With modern-day measurement systems it’s easily possible to assess speech and noise levels that are experienced in the real world. Recent research did just that for older adults with mild to moderate hearing loss, who carried digital recorders for 5 to 6 weeks, recording sounds in their environment for 10 hours per day (Wu et al, 2018). The speech level, noise level, and SNR of nearly 1000 listening situations were then analyzed. The researchers found that as noise levels increased from 40 to 74 dBA, speech levels systematically increased from 60 to 74 dBA, and consequently, the SNR decreased from 20 to 0 dB. Most SNRs (62.9%) were between 2 and 14 dB. Situations that had SNRs below 0 dB only comprised 7.5% of the listening situations. Further analysis revealed that the mean speech level of the listening situations that were considered “quiet” was 62.8 dBA, and the mean SNR of the “noisy environments” was 7.4 dB (Speech=67.9 dBA). A subset of the noisy observations had lower SNRs (mean=4.2 dB).
Our previous discussion of restaurant noise would suggest that the SNR findings from the Wu et al research for noisy environments would be more adverse than +4 dB. However, this latter study was designed to examine the “typical” listening situations for older adults with hearing loss, who probably avoid noisy restaurants. Regardless, we would expect even a +4 dB SNR to prevent meaningful communication for most of the hearing impaired (who are not wearing hearing aids). Recall the data from Wilson (2011) that was reported earlier. His findings revealed that only 7% of his sample had normal performance on the WIN, which is a 50% correct point of ≤6 dB SNR.
Reported Problems Caused by Background Noise
Given that many clinics do not conduct routine testing of speech understanding in background noise, it often is necessary to rely on the patient’s report. Perhaps the most commonly used self-assessment scale for this purpose is the Abbreviated Profile of Hearing Aid Benefit (APHAB), which has a subscale specifically devoted to problems in background noise. The unaided normative data from the APHAB (individuals with mild-moderate hearing loss) shows the 50th percentile of percent-of-problems to be 75% of listening situations, with the 20th percentile still reporting 58% of problems (Johnson et al, 2010).
Of course, background noise also hampers speech understanding for those with normal hearing. APHAB norms reveal that these individuals’ 50th percentile is reported as listening problems 25% of the time—a reminder that even with well-fitted hearing aids, it’s reasonable to assume that 25% of the problems understanding speech in background noise still will be present for the average person.
The APHAB normative data for individuals with hearing loss are supported by the findings of MarkeTrak 10 (Carr, 2020). The survey included data for a large group of individuals who reported that they had a hearing loss, but do not wear hearing aids (n=2013).
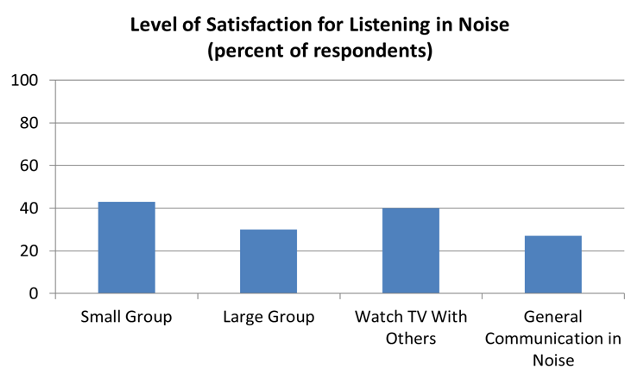
Figure 5. Percent of satisfaction for different listening-in-noise situations for MarkeTrak group of individuals (n-2013) with self-identified hearing loss, but who do not wear hearing aids (adapted from Carr, 2010).
Shown in Figure 5 are the percent of this group that are “satisfied” with their ability to understand speech in different background noise conditions. Observe that satisfaction is low for all environments, below 30% for the general category of listening in noise. In a related MarkeTrak 10 finding, only 31% of this group report that they regularly socialize—this can be compared to regular socialization of 52% for their peers who wear hearing aids. So yes, background noise is problem. That leads to the most important question: Do hearing aids help?
V1.3: Yes, Hearing Aids Work!
Over the years, there has been a general belief that hearing aids don’t work very well in background noise. While this might have been somewhat true decades ago, it certainly isn’t true today. To improve speech understanding in background noise, there are two general approaches: enhance the desired speech signal, or attenuate the unwanted background noise. In many cases, both approaches are used simultaneously, and the outcome is quite favorable.
Directional Processing Technology
Wearable directional hearing aids have been available for 50 years—earlier versions had a single directional microphone, whereas today, directionality is accomplished electronically with dual omnidirectional microphones on each hearing aid. The fundamental notion of directionality is that the target speech signal—typically the “look directional”—receives full amplification, and sounds from other azimuths, primarily the back, are attenuated. In earlier analog instruments, this would provide a ~3 dB advantage in the SNR, resulting in a noticeable improvement in speech understanding for some listening situations (Mueller, 1981).
With the introduction of digital hearing aids, advancements in directional processing followed. Instruments became automatic—that is, based on the signal classification system, they would automatically switch between omnidirectional and directional processing (Powers & Hamacher, 2002). In the years that followed we saw the development of adaptive polar patterns, allowing the null of the pattern to focus on a given noise source, and even track a moving noise source. This feature allowed for SNR benefit (compared to omni) as large as 7-8 dB when the noise was from behind the listener (Ricketts et al, 2005). Another processing advancement has been the ability to switch the directional focus from the look directional (usually the front of the listener) to the back and to the sides. A situation where this can be especially beneficial is when the hearing aid user is driving a car, talking to someone in the back seat. Laboratory studies have shown that a ~10 dB advantage in SNR is possible for speech from the back, when compared to traditional directional processing, where signals from the back are attenuated (Mueller et al, 2011; Chalupper et al, 2011).
A more recent innovation regarding directional processing is narrow directionality using bilateral beamforming, which can be accomplished using full-audio data sharing between microphones (Powers & Froehlich, 2014). This is particularly useful when the listener is surrounded by background noise, as there also is significant attenuation of background sounds from the front, except for a narrow-range (~+/- 45 degrees) in the look-direction. Research has shown that with this processing, on average, individuals with mild-moderate hearing losses will have better speech recognition in background noise than their normal-hearing peers—a finding supported by four independent studies over the past several years (Froehlich et al, 2015; Froehlich & Powers, 2015; Jensen et al. 2021). It has been suggested that this narrow focus will impair the understanding of speech from off-center azimuths, but research has shown this is not a significant problem (Picou et al, 2014)
Digital Noise Reduction (DNR)
A second approach to improving speech understanding in background noise is to reduce the noise. This is commonly accomplished through the combination of modulation-based channel-specific gain reduction and some form of fast-acting spectral subtraction, such as Wiener filtering. Perceptually, the effect that is the most notable to the patient is the reduction of channel-specific gain. This has been shown to improve ease of listening and the aversiveness of loud noises (Chalupper & Powers, 2007; Bentler et al, 2006). Because in general, DNR is an overall gain reduction for a given channel, the SNR will not be significantly improved, as both speech and noise are reduced equally. While reducing the speech signal might appear to make speech understanding worse, consider, that activation of this DNR feature only occurs when noise is the dominant signal (in a given channel), and hence, most useable speech signals for this region have been masked prior to the gain reduction. While the SNR remains mostly unchanged, many patients do report an improvement in speech understanding when DNR is implemented. This could be because of a reduction in the upward spread of masking (reduced noise in the lower frequencies), or because the patient is more relaxed, and their attention, lip reading skills and overall cognitive function is improved. When hearing aid users compare DNR “on” vs. DNR “off,” the large majority favor DNR “on” (Ricketts & Hornsby, 2005).
A special application of DNR which does improve the SNR, and the patient’s understanding of speech, is to couple the strength of the DNR to the signal classification for directional processing. In general, DNR is not azimuth specific—but it can be! If the analysis for directional processing has determined that a listener has a primary speech signal from the front, it is then possible to apply more aggressive DNR to all sounds from the back of the hearing aid user. Often, the aggressiveness is tempered, because of the danger of also reducing important speech signals. But, if it is known that the desired speech signal is from the front, then more powerful DNR can be applied to the sides and the back. This has been shown to provide an additional SNR improvement of 2 dB or so—enough to significantly impact speech understanding for some listening situations (Powers & Beilin, 2013).
Listening Effort
When reviewing the benefits for using directional microphone technology and DNR we usually focus on improvements in speech understanding, but it’s also useful to consider the positive effects that these features have on listening effort. Increased listening effort can lead to listening fatigue, reduced cognitive function, which then often will indirectly lead to reduced speech understanding. Minimizing listening effort, is one of the goals of the hearing aid fitting. Multi-site research with bilateral beam forming hearing aids, using objective measures to assess listening effort (i.e, the listener’s EEG activity) has found that the use of these instruments significantly reduces listening effort, and in fact, results in listening effort for people with hearing loss that is equal to that of normal hearing individuals for the same speech-in-noise task (Littmann et al, 2017).
A cognitive issue related to listening effort is working memory. Working memory has a limited time capacity—it’s where we can hold information for short periods of time. It’s been suggested that we think of it as a temporary sticky note in the brain. Regarding speech recognition, it’s a place to store the portion of a sentence that we understood, while trying to figure out the word(s) that we missed. Background noise can impair working memory. Research in this area has shown that competing speech disrupts memory performance more than speech-shaped noise, but that the disruptive effects of a competing speech background can be cancelled by using DNR for persons with high working memory capacity (Ng et al, 2013). Again, while not directly related to speech understanding in background noise, an indirect benefit would be expected.
Real-World Benefit
To this point, we primarily have reviewed laboratory studies that have shown the advantages of modern signal processing for speech understanding in background noise, to the extent that for individuals with mild-to-moderate hearing losses, performance might be as good, or even better than their peers who have normal hearing. But, what about performance in the real world? We can examine this in at least three different ways: aided ratings for speech understanding in noise compared to normal hearing peers, overall satisfaction for specific speech-in-noise listening conditions, and satisfaction compared to peers with hearing loss who choose not to use hearing aids.
A standardized self-assessment inventory that often is used to quantify the benefits of hearing aids in the real world is the Abbreviated Profile of Hearing Aid Benefit (APHAB), which we discussed earlier in this paper. The APHAB has four different sub-scales; one of them is listening in background noise. APHAB norms show that the average hearing aid user will report that they have problems in background noise around 75% of the time (Johnson et al, 2010). One study which has assessed APHAB performance following the fitting of hearing aids (verified for the NAL-NL2 prescription) found an average 40% benefit for background noise—that is, 40% of the problems that existed for unaided were no longer present when hearing aids were used (Abrams et al, 2012). These aided findings for background noise reduced the percent-of-problems to the 80th percentile of older adults with normal hearing. A more recent similar study, even had better findings, showing average aided APHAB results for background noise in the real world no worse than individuals with normal hearing (Valente et al, 2018).
Perhaps the best source for tracking the effectiveness of hearing aid use in background noise is to examine the satisfaction data from the MarkeTrak surveys that have been conducted over the past 30 years. Figure 6 shows how satisfaction in these difficult listening situations has changed as hearing aid technology has improved.
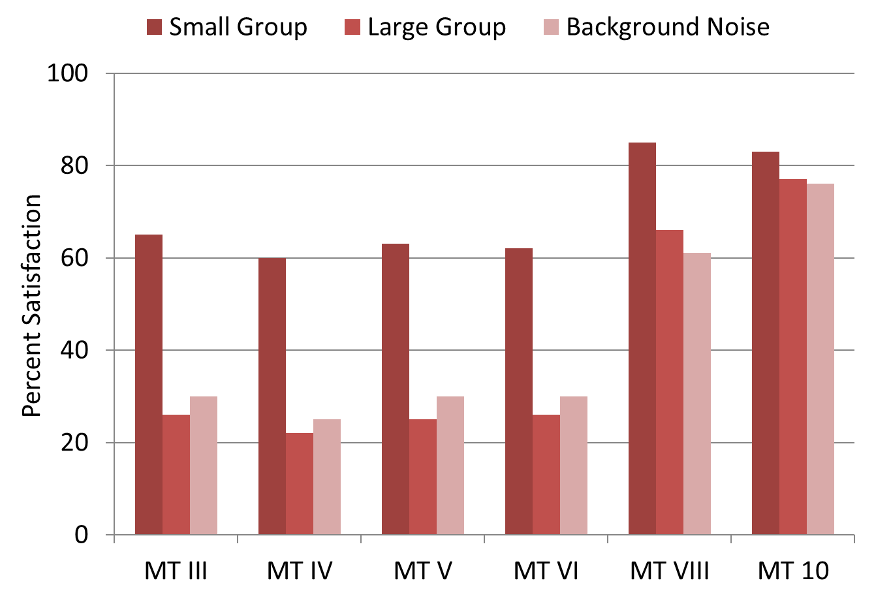
Figure 6. Percent of satisfaction for different noise conditions reported by hearing aid users on MarkeTrak surveys since 1991.
Clearly, the largest change in satisfaction occurred the first decade of the 2000s, the data for MarkeTrak VIII obtained in 2009. As shown by the MarkeTrak 10 data, we have continued to see improvement over the past ten years (Carr, 2020). It is possible, for a listening situation such as “small groups,” we have reached a satisfaction point that is nearing that of normal hearing individuals, and further improvement, therefore, isn’t realistic.
Another way to evaluate the real-world effectiveness of today’s hearing aids is to compare satisfaction for individuals who have recently purchased instruments, to their peers with self-identified hearing loss, who are non-owners. This was assessed by MarkeTrak 10, and is shown in Figure 7.
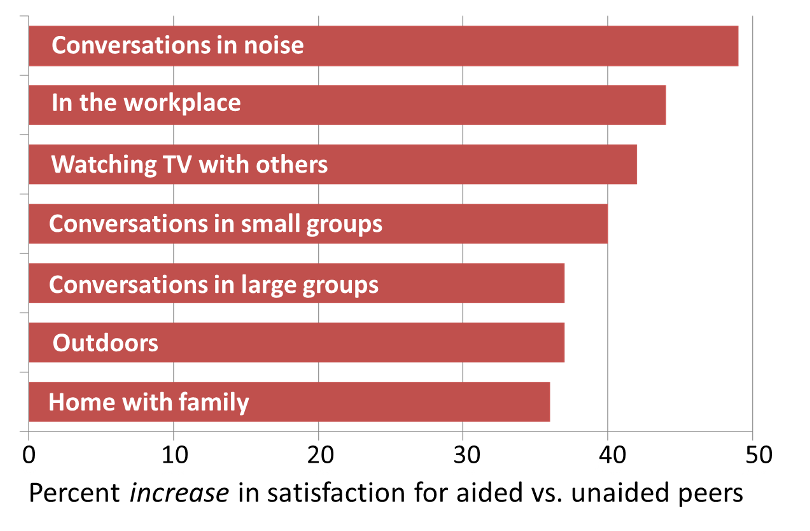
Figure 7. Shown for seven different listening situations, are data from MarkeTrak 10. Data represent the percent that satisfaction for people who wear hearing aids exceeds their peers with self-reported hearing loss who do not use hearing aids.
Importantly, what are shown here are not overall satisfaction values (which are much higher), but the degree that satisfaction for hearing aid users exceeded that of non-users. Advantages for the aided group were found for all categories surveyed; only those involving background noise are shown here. Most notably, for the general category of “conversations in noise,” the satisfaction is nearly 50% higher for the group using hearing aids. All this is good news! This technology, of course, only operates as designed when the hearing aids are fitted correctly—so let’s talk about that next.
V1.4: Ensuring Optimum Feature Benefit
As we discussed to this point, there is ample research evidence showing how hearing aids can improve speech understanding in background noise. Through the use of directional technology and digital noise reduction (DNR), we can expect that many individuals with mild-moderate hearing losses will perform as well, or even better than someone with normal hearing in several noise conditions when fitted with the appropriate technology. This is great news. But, these features only will work effectively if certain fitting guidelines are followed.
Optimizing Audibility
In general, once the appropriate technology has been selected, the over-arching theme of obtaining the desired benefit from hearing aids in background noise is to maintain appropriate audibility, especially in the critical 2000-4000 Hz range. Fortunately, based on decades of research, we have two prescriptive fitting methods, the NAL-NL2 and the DSLv5, that have validated fitting targets giving us the best possible blend of audibility, clarity, loudness, speech quality and listening comfort. When manufacturers conduct clinical trials that benchmark the “goodness” of various features, it is no surprise, therefore, that the products typically are fitted to one of these methods. If a hearing care professional (HCP) were to veer away from this standard, there is no guarantee that the feature will have the same benefit—in fact, it’s very probable that it won’t.
Some HCPs choose to use the manufacturer’s proprietary fitting algorithm, which nearly always will work against the benefit of noise reduction features, simply because less audibility is provided. An example of this is shown in Figure 8. This is for an individual with a typical downward sloping hearing loss, going from 20 dB in the lows to 70 dB in the highs.
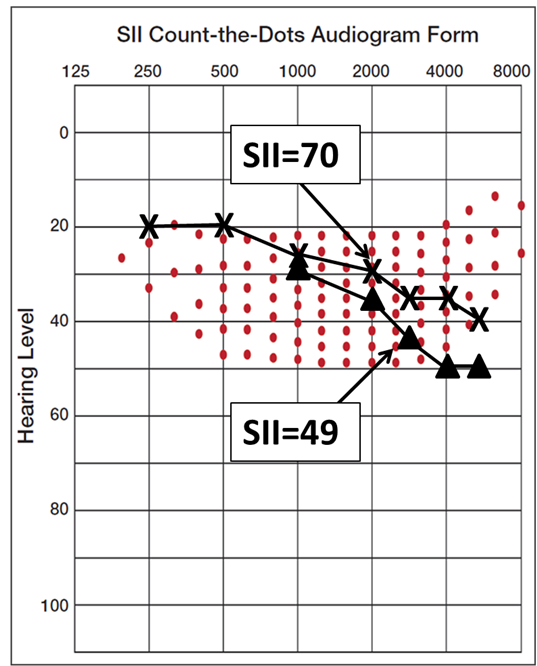
Figure 8. Projected aided thresholds and resulting SII for a fitting to the NAL-NL2 algorithm (upper plot) vs. to a manufacturer’s proprietary fitting.
What is shown on the upper plot (X—X) are the predicted aided thresholds if this person was fitted to the NAL-NL2 prescription. Note that the SII would be .70. If we use the data from recent research of Valente et al (2018) which documents the degree of under-fitting (5-15 dB) for a proprietary fitting, we have the lower plot (triangles), which would give us an SII of .49—a large reduction in audibility. Little of the speech signal above 2000 Hz is audible. To state the obvious, if the important high-frequency speech sounds are not audible, it doesn’t matter how good the noise reduction feature for this frequency range is performing—the patient won’t hear the desired speech signal.
An interesting clinical study compared the premier hearing aids from the leading six manufactures using a speech-in-noise task (Leavitt & Flexer, 2012). All products were equipped with the latest directional processing and DNR. The hearing aids were first programmed to each manufacturer’s proprietary fitting, and the SNR for SRT-50 for a group of individuals with hearing loss was obtained. The average SRT-50 for the participants across manufacturers was ~16 dB—that is, to understand 50% of the words, the speech needed to be 16 dB louder than the background noise. The hearing aids were then re-programmed to the NAL fitting algorithm and the group was retested. The average SRT-50 across hearing aids was now 9 dB (a seven dB improvement), with an improvement of 10 dB for two of the products. One product which appeared to have the worst technology when programmed to that company’s proprietary fitting, actually had the best performance of all six when programmed correctly to the NAL. Audibility matters!
Adaptive Feedback Control
Directly related to the issue of adequate high-frequency audibility is the sophistication of the product’s acoustic feedback control circuit. The effectiveness of this feature varies considerably among manufacturers, and hence, the choice of manufacturer can greatly impact the benefit the patient obtains from the hearing aids for understanding speech in background noise. Some research has shown a “gain-before-feedback” difference as large as 20 dB among different leading manufactures (Ricketts et al, 2019). Recent data, shown in Figure 9, does not show differences this large, but still large enough to make a significant difference in speech understanding (Marcrum et al, 2018).
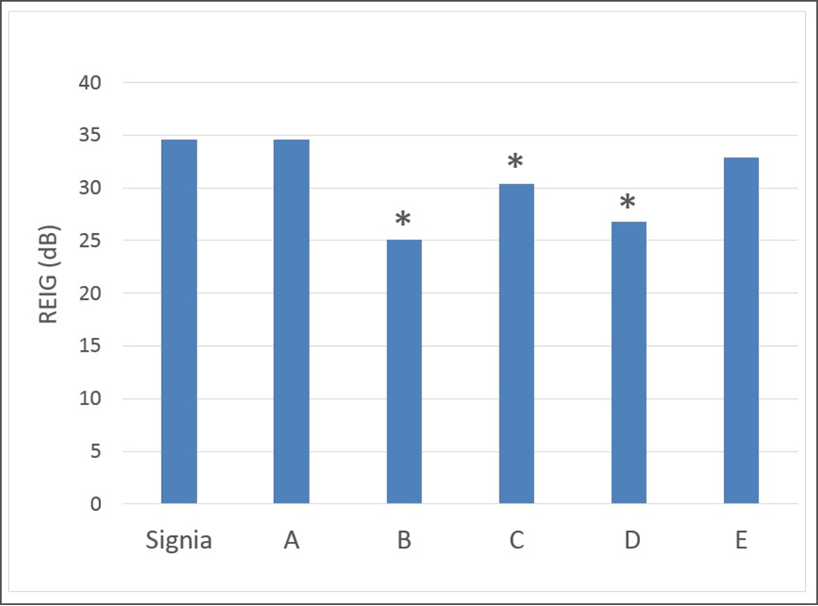
Figure 9. A comparison of gain-before-feedback for the premier hearing aids of the six major manufacturers when an open fitting was employed (adapted from Marcrum et al, 2018).
Shown here is the amount of gain for an open fitting, with adaptive feedback suppression activated, that can be obtained before feedback occurs. Notice that for the Signia product, the feedback-free gain is as much as ~10 dB greater than for two other leading products. For individuals with downward sloping hearing losses, 10 dB in the higher frequencies can make a significant difference—audible vs. not audible. Going back to Figure 8, the HCP might be attempting to fit the hearing aids to NAL-NL2, but because of feedback, is not able to obtain this degree of feedback-free gain. Choosing the right product is critical.
Ear Tips, Domes and Molds
Several factors go into the decision regarding what type of ear coupling should be used for a typical RIC hearing aid fitting. In general, the most common mistake made today is that the fitting is too open. This could be because the HCP believes the fitting needs to be open to make the patient’s voice sound natural (which may not be necessary when the hearing aid’s own voice processing is applied) or the HCP believes that a fitting dome labeled “closed” is really closed.
What sometimes is not taken into consideration, is that when an open, or partially open fitting tip is used, the resonance of the ear canal is maintained (usually around 2000-3500 Hz), and this often is as large as 15-20 dB. Imagine a listener with background noise (speech babble) of 60 dB SPL in the 2000 to 3000 Hz range originating from behind. It’s possible that good directional technology will reduce the amplification for this noise by 15-20 dB, compared to speech from the front. But what if the ear is open? The noise has a clear path to the eardrum. And . . . when it reaches the eardrum it no longer will be 60 dB SPL, but 75-80 dB SPL because of the boost from the residual earcanal resonance. Therefore, one advantage of a closed fitting is to alter the earcanal resonance. Yes, this also means that the desired speech signal from the front doesn’t receive the resonance boost, but that easily can be accounted for by programming more amplifier gain.
If the fitting is truly closed (e.g., a tight fitting custom earmold) an additional advantage will be that the earmold will act as an earplug for surrounding noise. This does not impact the desired speech signal, as it has a different pathway to the earcanal via the hearing aid receiver. Using probe-microphone equipment the real-ear occluded response (REOR) measure can be conducted, and this will provide very precise information regarding the openness of the fitting, and reveal the attenuation attributes of the ear coupling that might be present (Mueller et al, 2017).
Much of background noise is in the lower frequencies, in which case the residual earcanal resonance is not a factor. What is still a factor, however, is the open pathway for noise to travel directly to the eardrum, and also, the leakage out of the ear of the amplified speech signal—both factors reduce the at-the-eardrum SNR. An SNR that might be +10 dB or better in the lower frequencies with good DNR processing and a closed earmold, likely will be 0 dB SNR if the fitting is open. The bottom line is that if we want the sophisticated processing of the different features to function optimally, then we do not want direct sound to have a pathway to the eardrum.
The adverse effects on speech understanding in noise when the earcanal is even partially open has been documented in research. Shown in Figure 10 is the aided performance (50% correct SNR for speech in background noise) for hearing aids programmed identically, but fitted with ear couplings that had four different levels of “openness.”
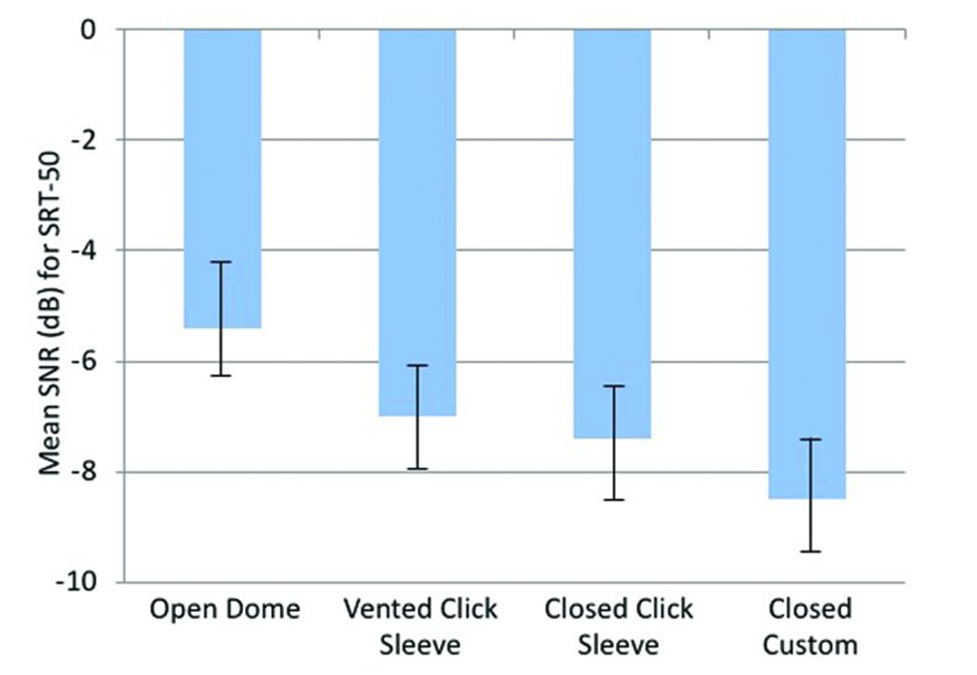
Figure 10. Effects of different types of ear couplings on speech understanding in background noise, as assessed using the SRT-50 (adapted from Froehlich & Littman, 2019).
As clearly shown, left to right on the chart, as the coupling becomes more closed, speech understanding is improved (a more negative SNR for 50% correct), with a 3 dB SNR difference from poorest to best. From a practical standpoint, think of this meaning that if a product with the latest directional technology was advertised as having a 6 dB SNR benefit (tested with a closed earmold)—a very impressive outcome—this same product might only have a 3 dB benefit when an open fitting is employed—a directional benefit no greater than the hearing aids of the 1970s.
Counseling
As with all aspects of the hearing aid fitting, appropriate patient counseling is critical regarding speech understanding in background noise. The primary key is “realistic expectations.” For example, investigations (and clinical experience) have shown that new hearing aid users will report more annoyance from noise using their hearing aids, than when they were unaided, even when the hearing aids have noise reduction (Palmer et al, 2006). This simply is an audibility issue—you can’t be annoyed by what you don’t hear.
Patients need to know, however, that research also has shown that when individuals with hearing loss have been fitted with hearing aids with effective DNR, their annoyance ratings for different types of background noise are no worse than those for young adults with normal hearing (Palmer et al, 2006). It’s something that the brain will acclimatize to. The potential maladaptive behavior of turning down gain to make the noise softer needs to be prevented. Consider the adage: “You have to hear what you don’t want to hear to know what you don’t want to hear!” A good one for patients to remember.
As previously stated, setting realistic expectations for understanding speech in background noise when using hearing aids probably is the most important. This can best be guided by conducting an unaided speech-in-noise test, such as the QuickSIN. This is a pre-fitting measure for each ear independently, using earphones, conducted at a relatively high presentation level (e.g., ~5 dB or so below the patient’s LDL). The QuickSIN provides the SNR where a person is correctly identifying 50% of words in sentences—a performance level where one can just follow a conversation. Conventional scoring for the QuickSIN is “SNR-Loss.” That is, how much worse is the 50% SNR level for a given patient vs. someone with normal hearing? This involves subtracting 2 dB from the SRT-50. When comparing a patient’s QuickSIN score to a real-world listening situation for counseling purposes, to compare apples to apples, we usually use the SRT-50, not the SNR-Loss.
We know that many large groups and restaurants have an SNR of around +5 dB (Smeds et al, 2015). We also know that in these difficult listening situations (e.g., reverberation, noise from multiple azimuths), if listeners are positioned optimally, they should achieve a speech-in-noise benefit from their hearing aids of ~3-4 dB. If their QuickSIN SRT-50 was 6-7 dB, we would then predict that they would do okay in this +5 dB type of speech-in-noise environment. If however, their QuickSIN SRT-50 scores were 10-12 dB, then clearly, they will not be able to follow a conversation in this setting, regardless of the sophistication of their hearing aids. It is helpful to inform the patient of this in advance. The solution would be to use remote microphone technology, or for the patient to visit a restaurant with a more favorable background noise level. We’ll talk more about how the QuickSIN can be used for patient counseling in Quick Takes Volume 6 (Part 1).
The bottom line is that with the combination of good technology, good fitting practices and good counseling, the majority of hearing aid users will be very successful understanding speech in background noise settings. In recent years, we’ve seen some new innovations which broaden our abilities to provide speech-in-noise solutions.
V1.5: Recent Innovations and Insights
When we think of the on-board technology that has driven the hearing-aid-related advancements in understanding speech in background noise, the focus usually falls on directional microphone processing, available since the early 1970s, and also digital noise reduction, available for over the past two decades. While the basic principles of these features have remained, several recent advancements and innovations have broadened the application and situational effectiveness.
Directional CROS and BiCROS
The CROS fitting application is designed for individuals who have one unaidable ear, and normal hearing in the “good” ear—it’s a fitting application dating back to the 1960s (Harford & Barry, 1965). Many patients, however, with an unaidable hearing loss in one ear, also have some hearing loss in the good (“best”) ear. If, when viewed independently, the best ear would be considered aidable, then the fitting would be a BiCROS; bilateral microphones with the signal of the worse ear routed contralaterally to the best ear for final processing (Mueller et al, 2014). What has changed in recent years with manufacturers like Signia, is that the physical technology the patient wears is the same for a CROS and a BiCROS application. What then differentiates the two fitting approaches is the programming. That is, a CROS easily can be converted to a BiCROS with minor programming changes.
A recent development in this area is to conduct pre-processing on the side of the bad ear, such as using directional microphone technology. The notion is to deliver the best signal-to-noise (SNR) ratio possible to the good (“best”) ear. Advancements in e2e Wireless technology have allowed for binaural beamforming, technology which can be used to create a very effective wireless CROS/BiCROS solution. It provides unique directional processing for both the transmitter and receiver side (see Figure 11 for polar plot example) (Petrausch et al, 2016). This bilateral directionality pattern is designed so that the better ear has maximum directionality to the front, but the directionality for the off-side microphone is slightly skewed toward the side of the poorer hearing (i.e, the side that the transmitter is worn).
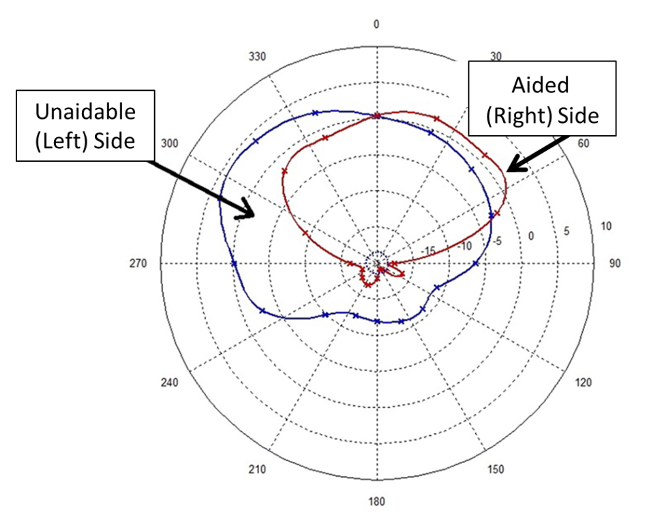
Figure 11. Examples of directional polar patterns for a BiCROS fitting with the transmitter on the left (unaidable) ear, and the fitting to the aided right ear. Note that for the unaidable side, the pattern is skewed somewhat to that direction, while still reducing amplification from the rear hemisphere (adapted from Petrausch et al, 2016).
The effectiveness of this innovative CROS processing was assessed in a clinical study (Petrausch et al, 2016). A worse-case listening scenario was implemented, with target speech originating from the poor-hearing side of the participant, with the competing noise directed toward the better-hearing ear. Testing was conducted with the transmitter microphone “on” versus “off” to establish an SNR benefit score. The benefit for the Signia CROS was 5.8 dB SNR, an advantage that could improve speech understanding by 60-80% for some listening situations. This SNR improvement also was significantly better than the comparative CROS products tested in this research.
With the BiCROS feature implemented, a field study was conducted for a different group of participants, who all had an unaidable ear, but also had hearing loss in the better ear. The participants were all full-time users of a comparative BiCROS product. Based on several weeks of comparative testing, strong preferences were noted for the Signia product for understanding in both quiet and in background noise, and also for speech quality.
OneMic Directionality
The term “one-mic” is somewhat misleading, as the use of a single microphone for directionality is certainly not new or innovative. It dates back to the 1970s, when a pressure-gradient microphone was used, that was sensitive to sounds from both sides of the membrane via a front and back inlet port. This design, while reasonably effective, requires two inlet ports and appropriate port spacing. This has limited the application of this directional approach to BTEs, and at the smallest, the ITC style. The same limitation applies to today’s use of dual microphones to accomplish directivity, which also requires two inlet ports.
The question then becomes, with the current use of effective wireless streaming of audio signals between hearing aids, would it be possible to develop a directional algorithm using only one microphone in each hearing aid? And if so, since only one input port would now be required, could this technology be applied effectively in small completely-in-the-canal (CIC) instruments? The answer to both questions is “yes.”
Having bilateral CIC instruments with bidirectional ear-to-ear wireless audio data transmission allows for careful weighting and combining both available microphone signals, and by imposing an appropriate optimization criterion for the adaptive weighting rule, it is possible to generate an enhanced output signal where interfering lateral noise sources can be efficiently attenuated, while the frontal desired signal remains untouched.
In the past, with CIC technology, the only form of directionality that was present was that provided by the pinna in the higher frequencies. If we were to compare the new OneMic CIC directionality with the dual-mic technology of the RIC BTE product, and this comparison was assessed for the hearing aids “off-the-ear,” the dual-mic product would be significantly better. But, and this is an important point, when the microphone is placed at the opening of the earcanal, there is considerable “free” directionality from the pinna, which is not present with the RIC product. When we then combine the OneMic directionality with the natural pinna directionality, we see results that are similar to dual-mic RIC BTE directionality. This is displayed in Figure 12.
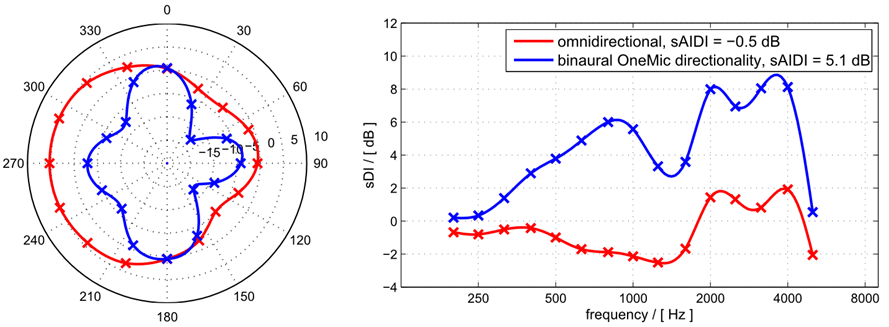
Figure 12. Illustration of the polar-pattern (left panel) and the resulting AI-DIs (right panel) for the OneMic directionality compared to omnidirectional.
The left panel of Figure 12 (red tracing) shows the omnidirectional polar pattern for a CIC OneMic product placed in the left ear of the KEMAR. Notice that no attenuation is provided for signals from the left, and little for those from the back. The attenuation for signals from the right are due to the head-shadow effect. By comparison, note the effective attenuation for the OneMic directional (blue tracing) for both the right and left sides, yet maintaining optimum amplification for signals from the front. The right panel reveals the resulting AI-DIs, with values as high as 6-8 dB for the important high frequencies. While there is not a direct one-to-one relationship, in general, the AI-DI correlates with the SNR advantage for a surrounding noise. This CIC bilateral OneMic directionality is automatic, steered by the signal classification system in the same way as its BTE RIC cousins.
Directionality and Motion
While we know that directional technology is beneficial for most all speech-in-noise conditions, patient’s intentions can vary depending on the noise level, reverberation effects, and listening situation. For this reason, a variety of polar patterns, automatic switching algorithms and other assorted processing strategies have been employed to optimize performance.There are many factors to balance.
One such factor is whether the wearer is stationary or moving. Imagine wearing hearing aids while attending a busy street fair. Because of the background talkers and music, the hearing aids will automatically switch to directional processing. This of course, is advantageous when talking to a specific vendor, but what about when walking through the crowd? The basic idea of motion-based beamforming is that when a wearer is moving, their preference is to hear sounds equally from all directions, and therefore, they require a more omni-directional pattern. When the wearer is stationary, and the talker of interest is coming from the front (or the “look-direction”), the hearing aids transition into a directional pattern.
A recent innovation is to include on-board motion sensors to assist in the signal classification process. The acceleration sensors conduct three-dimensional measurements every 0.5 milliseconds, with the post-processing of the raw sensor data occurring every 50 milliseconds, and is in turn used to control the hearing aid processing.
To evaluate the effectiveness of this motion-sensor-driven processing, a clinical study examined speech understanding and listening effort for participants for a listening situation designed to simulate a hearing aid user walking on a sidewalk on a busy street, surrounded by traffic noise (65 dBA), with a conversation partner on each side (Froehlich et al, 2019). With the traffic noise present, speech was presented randomly from 110° (male talker) and 250° (female talker) at 68 dBA (+ 3 dB SNR). Testing was conducted with the motion sensor “on” versus “off.” Results revealed a significant advantage for both speech understanding and listening effort when the signal processing was steered by the motion sensor (See Figure 13). When the participants were asked if they would recommend the product to a friend, 84% said yes when the motion sensor was active, but only 38% reacted positively when the motion sensor was off.
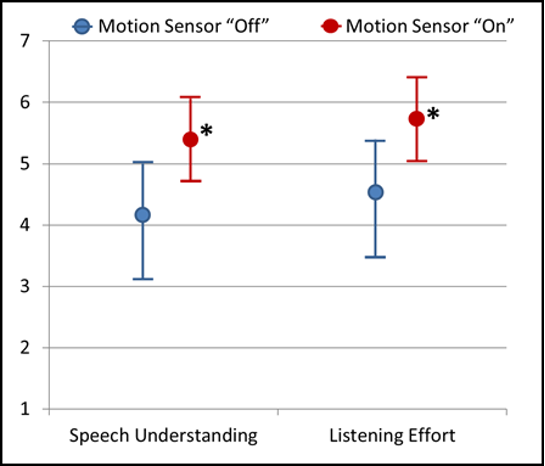
Figure 13. Results for listening to target speech from side azimuths in the presence of traffic noise, with the motion sensor “on” versus “off”. Ratings were conducted on 13-point scales ranging from 1=Strongly Disagree to 7=Strongly Agree, including mid-point ratings. The ratings were based on two statements related to different dimensions of listening: Speech understanding—“I understood the speaker(s) from the side well.”—and listening effort—“It was easy to understand the speaker(s) from the side.”
A separate study examined the real-world effectiveness of motion-driven signal processing (Voss et al, 2021). Measures included self-reported speech understanding, environmental awareness, overall listening and sound quality metrics, all gathered in a simulated real world listening condition. Measures of speech understanding and localization were significantly better for the motion-based processing. More participants also preferred the motion-based rather than conventional beam-former processing for environmental awareness, overall listening, and sound quality (Voss et al, 2021).
Understanding speech in the presence of background noise remains a challenge for many patients. Fortunately, incremental innovations in hearing technology such as motion-based beamformers help us more effectively thread the needle on the benefits and reduce the limitations of directional microphone technology.
V1.6: Unique solutions from Signia
We have reviewed the issues related to understanding speech in background noise, and presented many of the technology solutions, including some recent applications and innovations. Some of the algorithms used, such as conventional dual-mic directionality in RICs, and modulation-based digital noise reduction (DNR), are relatively generic, and can be found in products from most major manufacturers. Some features, however, which enhance the more conventional signal processing, are unique to Signia. For example, earlier we reviewed the on-board motion-sensor-driven technology, pioneered through Signia research and development. In this final section of Volume 1, we review two other effective methods of improving speech understanding in background noise, that are unique to Signia products.
Enhanced Acoustic Scene Analysis
The effectiveness of most speech-in-noise algorithms is determined by the precision of the signal classification system. One area of interest, therefore, centers on improving the importance functions given to speech and other environment sounds when originating from azimuths other than the front of the user, particularly when background noise is present. In general, improved identification and interpretation of the acoustic scene to better match our listening intentions is achieved with today’s signal classification system. Our listening intentions often are different in quiet vs. noise, when we are outside vs. in our homes, or when we are moving vs. when we are still. Can we design hearing aid technology to automatically achieve the best possible match between the listener’s intentions and the hearing aid’s processing? A 100% match is probably not possible, but improvements continue to be made.
Signia recently introduced an enhanced signal classification system which considers such factors as overall noise floor, distance estimates for speech, noise and environmental sounds, signal-to-noise ratios, azimuth of speech, and ambient modulations in the acoustic soundscape (Froehlich et al, 2019a; Froehlich et al, 2019b; Powers et al, 2019). To evaluate the patient benefits of this new processing feature, a laboratory study was designed that would simulate a typical restaurant scenario. Specifically, in the presence of background noise, a hearing aid user is engaged in a conversation with a person directly in front, and unexpectedly, a second conversation partner, who is outside the field of vision, enters the conversation. This is something that might be experienced at a restaurant when a server approaches.
For this simulated condition, the target conversational speech was presented from 0° degree azimuth (female talker; 68 dBA) and the background cafeteria noise (64 dBA) was presented from four speakers surrounding the listener (45°, 135°, 225° and 315°). The unexpected male talker (68 dBA) was presented randomly, originating from a speaker at 110°.
The participants conducted ratings on 13-point scales ranging from 1=Strongly Disagree to 7=Strongly Agree, including mid-point ratings. The ratings were based on two statements related to different dimensions of listening: Speech understanding—“I understood the speaker from the side well.”—and listening effort—“It was easy to understand the speaker from the side.” Testing was conducted with the new signal classifier “on” versus “off.”
Participants had little trouble understanding the conversation from the front, with median ratings of 6.5 (maximum=7.0) for both the “on” versus “off” setting, with no significant difference between the two types of processing for this condition. This was the expected finding. As shown in Figure 14, for the talker from the side, however, there was a significant advantage for the “new processing on” for speech understanding, and also for ease of listening. These findings support the enhancements to the signal classification system, with the goal of making processing decisions consistent with the intent of the wearer.
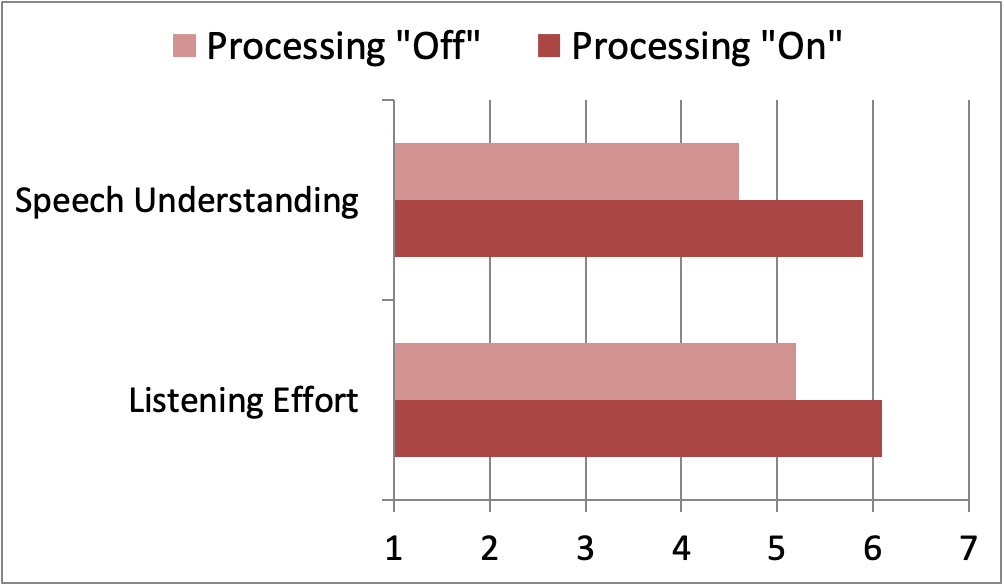
Figure 14. A significant advantage for both speech understanding and listening effort for listening to “off-center” speech in background noise was obtained for the new Signia signal classification processing.
Augmented Focus and Split-Processing
One long-standing problem associated with hearing aid noise reduction algorithms is that signals are mixed in the final processing stage where gain and compression is applied. It is reasonable to assume, that if we process the sound the wearer wants to focus on, which is typically speech, completely separately from the surrounding sounds, a more advantageous SNR could be obtained. This split processing increases the contrast between the focus and surroundings and makes the speech stand out as being clearer and easier to understand.
Specifically, using beam-former technology, one stream contains sounds coming from the front of the wearer, while the other stream contains sounds arriving from the back. Both streams are then processed completely independently. This means that for each stream, a dedicated processor can be used to analyze the characteristics of sound from every direction and process the sound in 48 channels. Thus, split processing helps determine whether the signal contains information the wearer wants to hear in the Focus stream, or, in contrast unwanted or distracting sounds, which are processed separately in the Surrounding stream. Compared to conventional single-stream processing, a speech signal can be processed with more linear gain, and more effective compression, while noise reduction can be applied to a surrounding noise signal, without compromising the speech processing. This is illustrated in Figure 15.
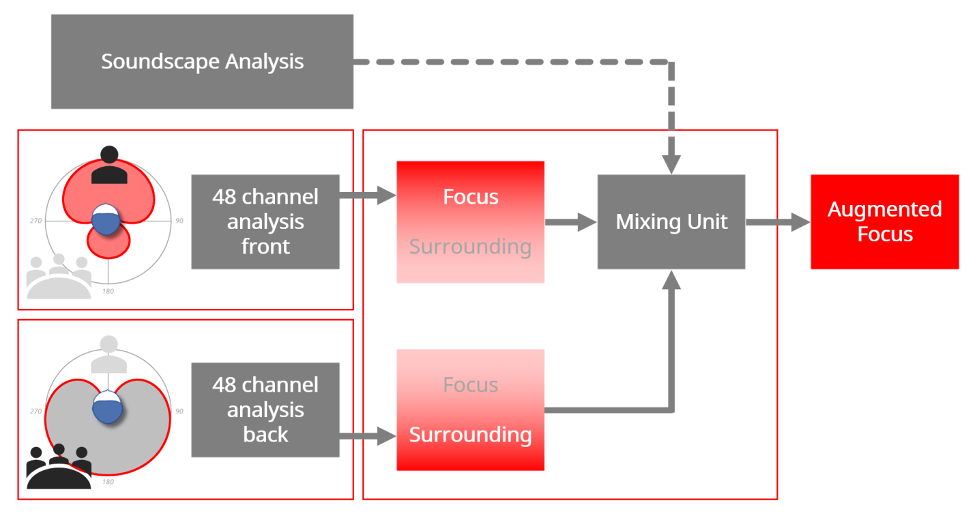
Figure 15. Schematic illustration of the split processing. In this example, the speech coming from the front is detected and processed as a Focus stream, while the noise from multiple talkers behind the wearer is detected and processed as a Surrounding stream.
In addition to the expected SNR benefits, the augmented processing also enhances the wearer’s perception of background sounds by providing a fast and precise adjustment of the gain for surrounding sounds. This improves the stability of the background sounds, and consequently, the wearer’s perception of the entire soundscape is enhanced.
Research with this new processing has examined such things as: the effects of processing “on” vs. “off” for speech in noise understanding, comparison of processing “on” to competing products that do not have this processing, and real-world assessment of the advantages of the processing (Jensen et al, 2021a; Jensen et al, 2021b).
In laboratory testing, a restaurant situation was simulated, and individuals were tasked with repeating back sentences in background noise; the SNR where 80% correct was obtained was determined. The participants were surrounded by the noise, with target sentences presented from the front. At varying intervals, recorded laughter of 76 dBA was presented from one of three randomly selected loudspeakers located behind the participant (135°, 180°, or 215°). A few seconds after the onset of the laughter, the target sentence was delivered. After each sentence, there was a pause in the laughter, until it was again presented (from a different loudspeaker) to coincide with the next sentence. This scenario was used to compare “on’ vs. “off” and also for the comparison to competitive products.
The results for “on” vs. “off” are shown in Figure 16. Observe that this new feature had a significant benefit for speech recognition, improving the SRT-80 by 3.9 dB SNR. Importantly, this is in addition to the advantages of Signia’s directional processing, which was active in the “off” condition.
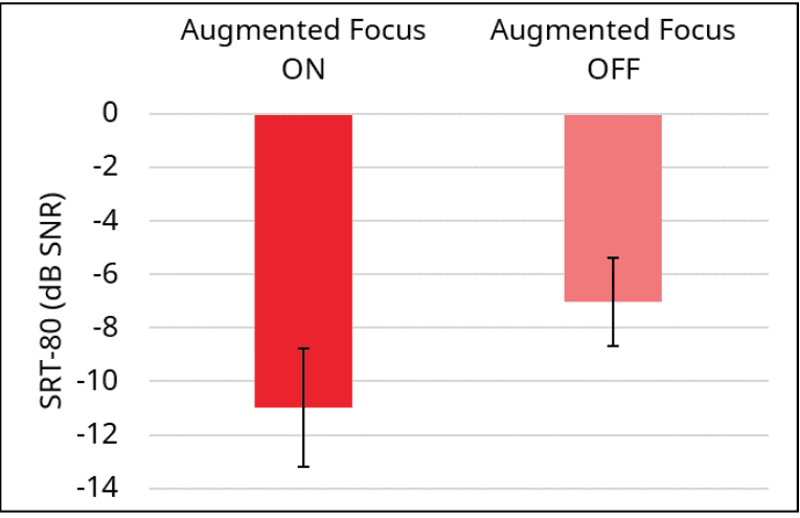
Figure 16. Mean speech recognition scores (SRT-80) with the new split-processing feature “on” vs. “off”. Testing conducted in the Restaurant Scenario. Error bars represent 95% confidence intervals.
With the augmented focus feature activated, the new Signia split-processing was compared to two leading competitors, labeled Brand A and Brand B in Figure 17. The same restaurant simulation test condition was used. The resulting mean SRT-80 for Signia was 2.1 dB (SNR) superior to Brand A, and 7.3 dB (SNR) superior to Brand B. Importantly, all products were programmed to the NAL-NL2 algorithm, verified with real-ear measures, to ensure that the differences observed were due to speech-in-noise processing, not variances in programmed gain and output.
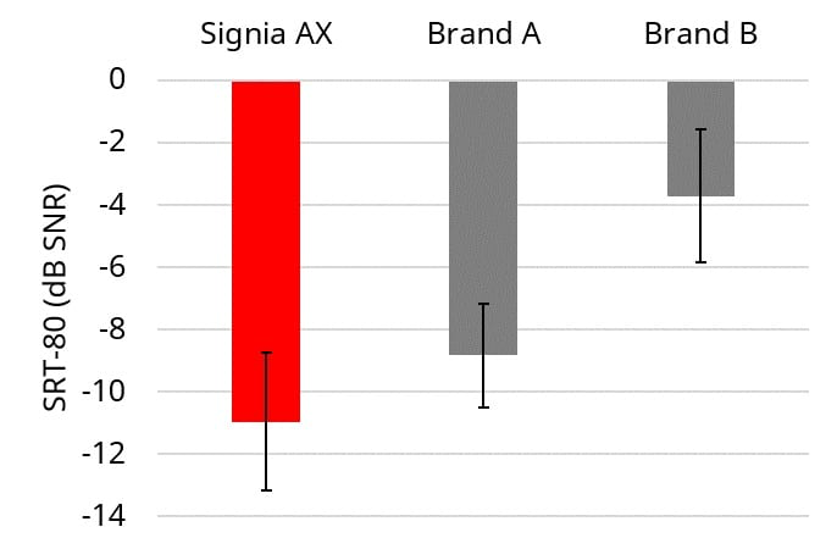
Figure 17. Mean scores (SRT-80) for the Signia, compared to two leading competitive products, labeled Brand A and Brand B. Testing conducted in the Restaurant Scenario. Error bars represent 95% confidence intervals.
In a separate laboratory study, bisyllabic speech (/ba-ba/ and /ba-da/) were presented at 65 dB SPL from a loudspeaker located in front of the participant, and at the same time, temporally offset recordings of 4-talker babble were played through each of two loudspeakers located behind the listener at 135° and 225° (Slugocki et al, 2021). The participant’s task was to determine if the /ba-ba/ was the same as or different from the /ba-da/ speech signal. The babble noise was varied adaptively, and an aided SNR was established for the new augmented focus split-processing feature “on” versus “off.” The results revealed a mean improvement in the SNR of 3 dB when the split processing was activated. This is similar to the 3.9 dB advantage reported earlier for this feature, obtained in other independent research (Jensen et al, 2021a).
In addition to the laboratory studies, the new Signia split-processing feature also was tested in real-world use conditions (Jensen et al, 2021b). Participants used their hearing aids for several weeks, and at the conclusion of the trial, completed questions from the Speech, Spatial and Qualities of Hearing self-assessment scale (SSQ) (Gatehouse & Noble, 2004). This scale uses a 10-point rating for various listening situations involving speech understanding, sound quality and localization. There are normative data available for this scale for older adults with normal hearing (Banh et al, 2012). In Figure 18, specific questions from the SSQ used in this research which involve listening in background noise have been selected, and shown are the mean ratings from the participants compared to those of normal hearing group (Jensen et al, 2021b). Observe in all cases, performance with the new Signia processing was either equal to, or just slightly below that of the normal hearing group. This of course is consistent with the laboratory data, discussed earlier in this paper. Clearly, while hearing aid technology such as directional microphones have been available for over 50 years, new algorithms continue to emerge to assist in the constant battle of understanding speech in background noise.
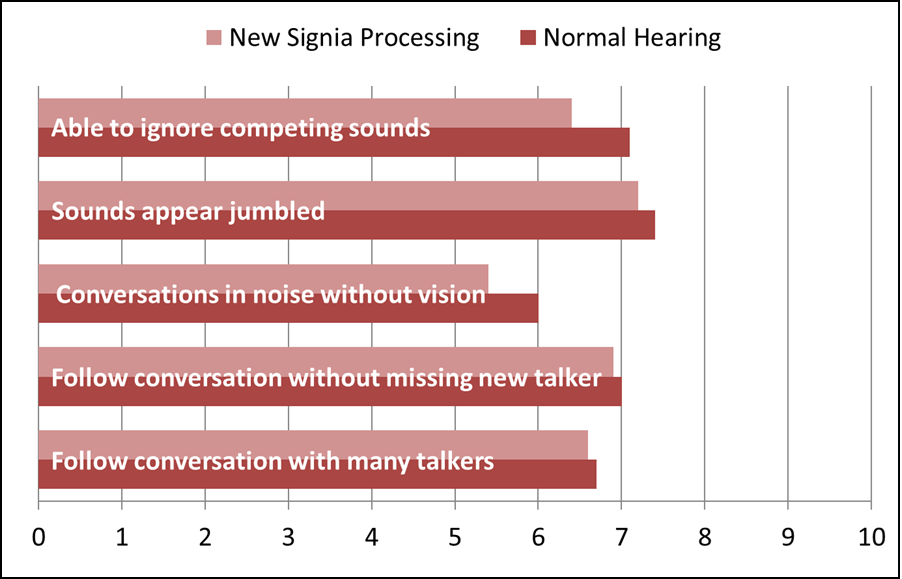
Figure 18. Mean ratings using the new Signia processing are shown for selected questions of the SSQ involving speech understanding in background noise. SSQ norms for older individuals with normal hearing also are displayed.
In Closing
In this Research Quick Takes Volume 1 on background noise, we have taken you from the explanation of the problem, through important fitting considerations, a review of well-established technology, and a glimpse into what is new. The future is bright for solving the “understanding-speech-in-background-noise” problem.
References
Abrams, H., Chisolm, T., McManus, M., & McArdle, R. (2012). Initial-fit approach versus verified prescription: comparing self-perceived hearing aid benefit. Journal of the American Academy of Audiology, 23(10), 768-778.
Banh, J., Singh, G., & Pichora-Fuller, M. K. (2012). Age affects responses on the Speech, Spatial, and Qualities of Hearing Scale (SSQ) by adults with minimal audiometric loss. Journal of the American Academy of Audiology, 23(2), 81-91.
Bentler, R., Wu, Y. H., Kettel, J., & Hurtig, R. (2006). Digital noise reduction: outcomes from laboratory and field studies. International Journal of Audiology, 47, 447-460.
Carr, K. (2020). 20Q: Consumer insights on hearing aids, PSAPs, OTC devices, and more from MarkeTrak 10. AudiologyOnline, Article 26648. Retrieved from www.audiologyonline.com
Chalupper, J., & Powers, T. (2007). New algorithm is designed to take the annoyance out of transient noise. The Hearing Journal, 60(7), 42-48.
Chalupper, J., Wu, Y., & Weber, J. (2011). New algorithm automatically adjusts directional system for special situations. Hearing Journal, 64(1), 26-33.
Cherry, E. C. (1953). Some experiments on the recognition of speech with one and two ears. Journal of the Acoustical Society, 25(5), 975-979.
Froehlich, M., Freels, K., & Powers, T. (2015). Speech recognition benefit obtained from binaural beamforming hearing aids: comparison to omnidirectional and individuals with normal hearing. AudiologyOnline, Article 14338. Retrieved from https://www.audiologyonline.com
Froehlich, M., & Powers, T. (2015). Improving speech recognition in noise using binaural beamforming in ITC and CIC hearing aids. Hearing Review, 22, 12-22.
Froehlich, M., & Littmann, V. (2019). Closing the open fitting: an effective method to optimize speech understanding. Hearing Review, 26(4), 16-20.
Froehlich, M., Branda, E., & Freels, K. (2019a). New dimensions in automatic steering for hearing aids: Clinical and real-world findings. Hearing Review, 26(11), 32-36.
Froehlich, M., Freels, K., & Branda, E. (2019b). Dynamic Soundscape Processing: Research Supporting Patient Benefit. Retrieved from AudiologyOnline.
Gatehouse, S., & Noble, W. (2004). The Speech, Spatial and Qualities of Hearing Scale (SSQ). International Journal of Audiology, 43(2), 85-99.
Jensen, N. S., Høydal, E. H., Branda, E., & Weber, J. (2021a). Augmenting speech recognition with a new split-processing paradigm. Hearing Review, 28(6), 24-27.
Jensen, N. S., Powers, L., Haag, S., Lantin, P., & Høydal, E. (2021b). Enhancing real-world listening and quality of life with new split-processing technology. AudiologyOnline, Article 27929. Retrieved from https://www.audiologyonline.com
Harford, E., & Barry, J. (1965). A rehabilitative approach to the problem of unilateral hearing impairment: Contralateral routing of signals (CROS). Journal of Speech and Hearing Disorders, 30, 121-138.
Holube, I. (2015, February). 20Q: getting to know the ISTS. AudiologyOnline, Article 13295. Retrieved from https://www.audiologyonline.com.
Hornsby, B., Ricketts, T., & Johnson, E. (2006). The effects of speech and speech-like maskers on unaided and aided speech recognition in persons with hearing loss. Journal of the American Academy of Audiology, 17(6), 432-447.
Johnson, J., Cox, R. M., & Alexander, G. C. (2010). APHAB norms for WDRC hearing aids. Ear and Hearing, 31(1), 47-55.
Killion, M. C., & Mueller, H. G. (2010). The New Count-the-Dot Audiogram. Hearing Journal, 63(1), 10-15.
Kujawa, S. (2017, August). 20Q: Cochlear synaptopathy - interrupting communication from ear to brain. AudiologyOnline, Article 20946. Retrieved from www.audiologyonline.com.
Leavitt, R., & Flexer, C. (2012). The importance of audibility in successful amplification of hearing loss. Hearing Review, 19(13), 20-23.
Littmann, V., Wu, Y. H., Froehlich, M., & Powers, T. A. (2017). Multi-center evidence of reduced listening effort using new hearing aid technology. Hearing Review, 24(2), 32-34.
Livingston, G., Huntley, J., Sommerlad, A., et al. (2020). Dementia prevention, intervention, and care: 2020 report of the Lancet Commission. The Lancet Commissions, 396(10248), 413-446.
Marcrum, S., Picou, E., Bohr, C., & Steffens, T. (2018). Feedback reduction system influence on additional gain before feedback and maximum stable gain in open-fitted hearing aids. International Journal of Audiology, 57(10), 737-745.
Mueller, H. G. Directional microphone hearing aids: A 10 year report. (1981) Hearing Instruments, 32(11), 16-19.
Mueller HG, Weber J, Bellanova M. (2011) Clinical evaluation of a new hearing aid anti-cardioid directivity pattern. International Journal of Audiology, 50(4), 249-254.
Mueller HG, Ricketts T, Bentler R (2014) Modern Hearing Aids. San Diego: Plural Publishing.
Mueller HG, Ricketts T, Bentler (2017) Speech Mapping and Probe Microphone Measurements. San Diego: Plural Publishing
Palmer CV, Bentler R, Mueller HG. (2006) Amplification with digital noise reduction and the perception of annoying and aversive sounds. Trends in Amplification, 10, 95-104.
Pearsons K, Bennett R, and Fidell S. (1977) Speech levels in various noise environments (Report No. EPA-600/1-77-025). Washington DC: US Environment Protection Agency.
Petrausch S, Manders A, Jacobus K. (2016) A New Wireless CROS and BiCROS Solution. Canadian Audiologist, 3(4).
Picou E, Aspell E, Ricketts T. (2014) Potential benefits and limitations of three types of directional processing in hearing aids. Ear and Hearing, 35(3), 339-352.
Ng EH, Rudner M, Lunner T, Pedersen MS, Ronnberg J. (2013) Effects of noise and working memory capacity on memory processing of speech for hearing-aid users. International Journal of Audiology, Jul;52(7), 433–41.
Powers, T. A., Hamacher, V. (2002). Three-microphone instrument is designed to extend benefits of directionality. Hearing Journal.
Powers, T. A., Beilin, J. (2013). True advances in hearing aid technology: what are they and where’s the proof? Hearing Review.
Powers, T. A., Froehlich, M. (2014). Clinical results with a new wireless binaural directional hearing system. Hear Rev.
Powers, T. A., Weber, J., Branda, E. (2019). Maintaining Narrow Directionality While Improving Soundscape Processing. Canadian Audiologist.
Ricketts, T. A., Hornsby, B. W. (2005). Sound quality measures for speech in noise through a commercial hearing aid implementing digital noise reduction J Am Acad Audiol.
Ricketts, T., Hornsby, B. Y., Johnson, E. E. (2005). Adaptive Directional Benefit in the Near Field: Competing Sound Angle and Level Effects. Seminars in Hearing.
Ricketts, T., Bentler, R., Mueller, H. G. (2019). Essentials of Modern Hearing Aids. San Diego: Plural Publishing.
Roup, C. M., Post, E., & Lewis, J. (2018). Mild-Gain Hearing Aids as a Treatment for Adults with Self-Reported Hearing Difficulties. Journal of the American Academy of Audiology, 29(6), 477-494. doi:10.3766/jaaa.16111
Rusnock, C., & Bush, P. (2014). An Evaluation of Restaurant Noise Levels and Contributing Factors. Journal of Occupational and Environmental Hygiene, 9(6), D108-D113.
Sevenson, J., Clifton, L., Kuzma, E., et al. (2021). Speech-in-noise hearing impairment is associated with an increased risk of incident dementia in 82,039 UK Biobank participants. Alzheimer’s and Dementia. Advance online publication. doi:10.1002/alz.12416
Slugocki, C., Kuk, F., Korhonen, P., & Ruperto, N. (2021). Using the Mismatch Negativity (MMN) to Evaluate Split Processing in Hearing Aids. Hearing Review, 28(10), 32-34.
Smeds, K., Wolters, F., & Rung, M. (2015). Estimation of Signal-to-Noise Ratios in Realistic Sound Scenarios. Journal of the American Academy of Audiology, 26(2), 183-196.
Tremblay, K. L., Pinto, A., Fischer, M. E., et al. (2015). Self-reported hearing difficulties among adults with normal audiograms: The Beaver Dam Offspring Study. Ear and Hearing, 36(6), e290-e299.
Valente, M., Oeding, K., Brockmeyer, A., Smith, S., & Kallogjeri, D. (2018). Differences in Word and Phoneme Recognition in Quiet, Sentence Recognition in Noise, and Subjective Outcomes between Manufacturer First-Fit and Hearing Aids Programmed to NAL-NL2 Using Real-Ear Measures. Journal of the American Academy of Audiology, 29(8), 706-721.
Voss, S., Pichora-Fuller, M. K., Ishida, I., Pereira, A., Seiter, J., Guindi, N., Kuehnel, V., & Qian, J. (2021). Evaluating the benefit of hearing aids with motion-based beamformer adaptation in a real-world setup. International Journal of Audiology, 7, 1-13.
Wilson, R. H. (2011). Clinical Experience with the Words-in-Noise Test on 3430 Veterans: Comparisons with Pure-Tone Thresholds and Word Recognition in Quiet. Journal of the American Academy of Audiology, 22(7), 405-423.
Wu, Y. H., Stangl, E., Chipara, O., Shabih, S., Welhaven, A., & Oleson, J. (2018). Characteristics of Real-World Signal to Noise Ratios and Speech Listening Situations of Older Adults With Mild to Moderate Hearing Loss. Ear and Hearing, 39(2), 293-304.
Citation
Taylor, B. & Mueller, H. G. (2023). Research QuickTakes Volume 1: understanding and treating the background noise problem for hearing aid users. AudiologyOnline, Article 28674. Retrieved from https://www.audiologyonline.com


