
To compensate for the abnormal loudness growth experienced by listeners with sensorineural hearing impairment, compression is used as a basic processing feature in digital hearing instruments. Through amplification, sounds are mapped into the residual dynamic range of the hearing impaired listener, resulting in more gain applied to soft sounds and less gain applied to loud sounds.
The static behavior of compression is well defined and fitting rationales such as NAL-NL1 are based on this knowledge. However, current fitting rationales do not take into account the temporal aspects of compression -- because there are no agreed-upon rules for verifying this behavior!
Many variables impact the choice of temporal characteristics. It has been shown that processing strategies using many independent compression channels combined with short time constants can be problematic (Hansen, 2000). On the other hand, beneficial effects have been reported when only a small number of compression channels are used (Gatehouse, 2000; Dillier, 1993). However, signal distortions may occur if these systems act too quickly.
This article compares and contrasts different strategies of input level estimation and reveals potential sources for degradation. A solution will be described that has been implemented in a digital chip.
Basic Considerations:
Before discussing different level estimators, it may be helpful to review how compressors work.
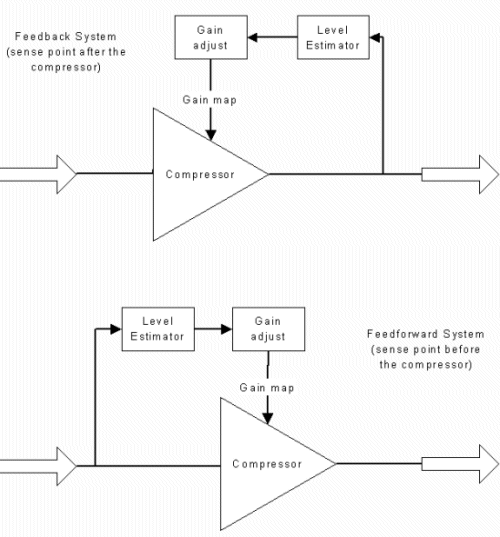
Figure 1 Compressor block diagram
Figure 1 shows two compressor control concepts: feedback and feedforward. The feedback compressor was the earliest implementation, and is still the most common form of analog compression, since it is the simplest circuit. In a feedback configuration, the signal after the compressor is used to control the amplification. In a feedforward configuration, the signal before the compressor provides the control. The feedforward system is more complex, but affords more possibilities for adjusting amplification. Feedforward is the most common configuration in digital hearing instruments. In either case, the control signal must pass through a level estimator. Two activities take place in the level estimator: rectification and storage. Rectification converts the negative and positive peaks of the sound wave into "all positive" values. In digital systems, this is easily accomplished by taking the absolute value of the signal. Alternatively, the positive and negative values can be squared, producing only positive values, as a step toward producing an rms (root mean square) value of the signal, which approximates human perception (alternative methods of rectification in digital systems will not be discussed here). The second activity of a level estimator is to store the signal. Importantly, compressors cannot instantaneously adjust the gain. To do so would distort the audio signal. A peak clipper could be described as instantaneous compression limiting, and we all know how bad that sounds!
Consequently, gain must change quickly enough to positively impact the preferred loudness of the output signal, yet slowly enough to avoid audible distortion. To produce this result, the control signal is stored and averaged in some way. It is this averaging that gives rise to the dynamic characteristics of a compression system, and is a source of large variation between competing compression hearing instruments.
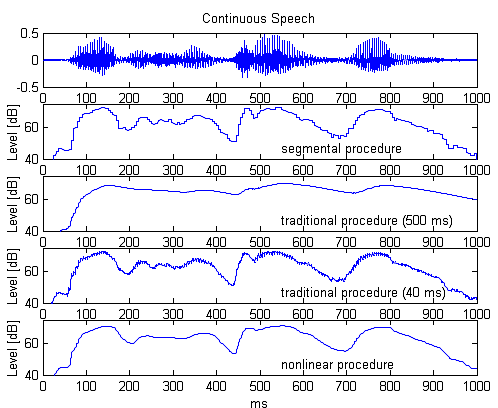
Figure 2: 1 second excerpt of continuous speech, with various level estimates.1
Figure 2 shows the output from several different level estimators (the various estimates will be reviewed later in this article). When comparing the different level estimates, keep in mind the following:
For compressors, gain will be lower as the input level increases. Therefore, if the estimate is below the instantaneous input level, the output of the system will be higher than desired. If the estimate is higher than the actual level, the gain will be too low.
Level Estimator Goals:
1-Accurate
It must be able to precisely follow the level of the signal, and deviate only when necessary to avoid perceptible distortion.
2-Fast
Improvement in speech intelligibility due to fast-acting compression requires more gain to be applied to soft sounds, such as consonants, and less gain to loud sounds, such as vowels. This is often referred to as improving consonant-to-vowel (CVR) ratio. Consequently, a level estimate is required which appropriately tracks these rapidly changing differences in level.
------------------------------------
1"Segmental procedure" is typical of an FFT-based system, with 10 ms time windows with 50% overlap. "Traditional procedure (500 ms)" is typical of a continuous estimate with a relatively long, 500 ms release time. "Traditional procedure (40 ms)" is typical of a continuous estimate with a relatively short, 40 ms release time. "Nonlinear procedure" is a novel new continuous estimate. Each of these level estimates is described later in this article.
Pitfalls of Level Estimators:
There are negative effects that must be avoided to produce high quality sound. Some common pitfalls are:
1-Distortion of the audio band
As we mentioned earlier, a system that operates too quickly will produce distortion in the low frequency region of the audio passband. Hence compression cannot be instantaneous. Luckily, given the temporal loudness summation characteristics of the human ear, very short constants can still be perceived as instantaneous.
2-Addition of artifacts to the sound
With any system that modifies the signal in a non-linear manner, it is possible, and indeed likely, that some artifacts will be introduced. These can be thought of as sounds with low correlation to the original signal, and can be perceptually obvious. One particular artifact that will be discussed is estimation noise.
3-Excessive throughput delay
Some research has shown that delays of as little as 3-5 ms are perceptible to a majority of people, and that delays of 10 ms are likely to be obvious and annoying 90% of the time, especially with respect to the perception of their own voice (Agnew and Thornton, 2000). With digital systems, throughput delay is an important consideration.
4-Non-synchronicity
Non-synchronicity is a subtle feature. In compressive amplification, the level of the input signal is estimated, and gain is applied to the signal based on this estimate. If the estimate and signal paths are not synchronized, it is possible for the estimate to be applied after the signal has passed. This can lead to overshoot and audible "pumping" effects.
5- Spectral smearing
When sound is spectrally divided into channels, amplification for some frequency regions moves independently from other frequency regions. A multi-channel compressor with fast time constants can reduce the spectral contrasts in speech (Dillon, 2001). This is known as spectral smearing and can result in reduced intelligibility (Lippman et al. 1981; Bustamante and Braida, 1987; Plomp, 1988; Moore, 1990).
Analog:
Analog systems were simpler. The control signal was continuous. However, analog systems always exhibit overshoot, since the throughput time is instantaneous. Choices were limited to selection of attack and release time, and the behavior was always a compromise.
Digital:
With the advent of digital technology, things became more complex. Now many choices must be made in the design -- some of them quite subtle.
Frequency Domain Processing
The most common method for providing control over the frequency response is to divide the frequency range into channels. In a digital system, this is typically done with a Fast Fourier Transform (FFT). An FFT is a highly efficient method for representing a continuous time signal as a frequency response. It allows the signal to be quickly divided into frequency bands or channels. But, there are some drawbacks.
1-Time vs. frequency resolution
One choice that arises with FFT systems is time versus frequency resolution. It is possible to divide the frequency range into many bands or channels, but then more time is required to produce accurate frequency segmentation. Conversely, if a faster system is desired, this comes at the expense of frequency resolution.
2-Processing delay
The largest problem caused by FFT systems is processing delay. This is the amount of time it takes for the signal to pass through the hearing aid. In analog systems, the processing delay is effectively zero. Digital systems introduce some delay, and FFT systems have considerable delay. This delay increases with the number of channels. There are several aspects that suggest the processing delay should be kept to a minimum: e.g. the hearing instrument signal combined with direct sound through a vent, which occurs in the case of good hearing in the low frequencies. Signal processing delay in algorithms that operate completely in the time domain is usually not critical. However, FFT systems can result in undesirable processing delays on the order of 10 ms.
3-Segmental estimates
In order to segment the frequency response (through channels), an FFT system must divide the time into segments as well. The more channels, the larger the time segment and, as mentioned above, these can be on the order of 10 ms. The large time segments can result in significant jumps in the level estimate, which results in estimation noise. This estimation noise can be objectionable, especially at lower frequencies. Figure 3 shows a low frequency vowel and the resulting level estimates. Clearly, the segmental estimate and the fast traditional estimate are modulating with the low frequency signal. This will result in distortion of the low frequency sound.
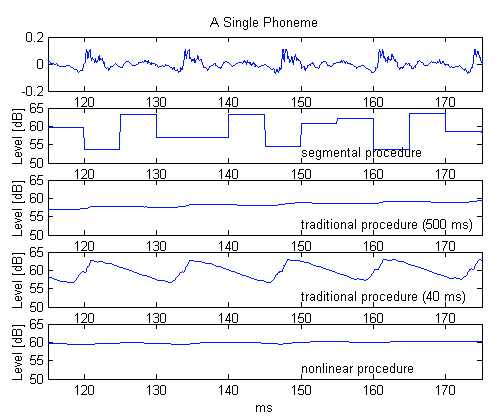
Figure 3: Various estimates, for a single phoneme
It is possible to reduce this estimation noise by overlapping the time segments. However, this will result in reduced temporal resolution as well.
Time Domain Processing
An alternative to FFT systems is to keep the signal in the time domain. This brings a number of advantages.
1-Low delay
Without conversion to the frequency domain, the delay through the system can be quite low, thus avoiding problems when combined with non-processed sound (as through the vent).
2- Continuous estimation
With time-domain processing, the level can be estimated continuously. This avoids the problem of estimation noise (due to steps in the segmental estimate) inherent in FFT systems.
However, there are still limitations that must be overcome when operating in the time domain. As with traditional analog compression systems, there is an inevitable compromise between short and long time constants. With long time constants, the envelope of the signal can move much quicker than the level estimate. There is essentially no compression for rapidly varying signals, such as speech. This can result in significant overshoot, which can exceed uncomfortable levels, as well as exceed the dynamic range of the amplifier, causing distortion (see the traditional procedure [500ms] of figure 2). It can also result in sub-optimal gain applied to softer elements of speech following louder elements (trailing consonants).
At the other end of the scale, short time constants can cause significant distortion in the low frequency region of the audio passband. The graph of the traditional procedure (40ms) of figure 3 shows a low-pitched male voice modulating the level estimation of a fast compressor. This will cause audible distortion.
Non-linear estimation
A refinement of continuous estimation resolves many of the traditional tradeoffs in compression. The estimation is made non-linear in two ways (much like the human ear). First, the change in level is treated in a non-linear fashion. In other words, a large level change has different time constants than a small level change. This allows the system to react quickly to large environmental changes while leaving the fine structure of speech unchanged. The examinations regarding fine and gross structure of speech indicate that only the nonlinear estimator is able to provide both fast and smooth level estimates at the same time.
Figure 4 shows the non-linear estimate (in red) compared to segmental and long traditional estimation (green and blue, respectively). Only the non-linear estimate is able to follow the overall speech envelope without modulating the low frequency vowel.
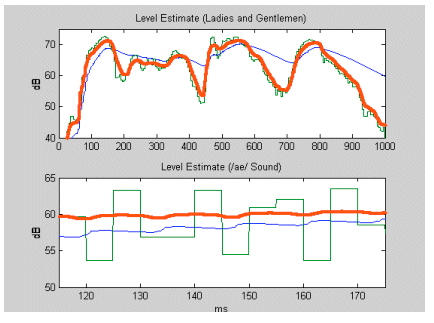
The second intentional non-linearity is that the level estimation is adapted to match the loudness estimation of the ear. The equal loudness contours for hearing are well known (ISO226) and show clear non-linearity. It is obvious that, if it were possible, mimicking the loudness estimation of the ear would result in more natural sound quality.
Strategy review:
1-Segmental Estimation
Segmental estimation is inherent in FFT-based multi-channel compressors. Multi-channel compressors cannot move too quickly, otherwise spectral smearing will result. For slower systems, segmental estimation can provide an effective estimate of the level. The FFT approach has an inherent advantage regarding synchronicity. As the signal is processed in segments, level estimation and applied gain usually refer to the same signal segment. However, if the segmental level estimate is subject to additional filtering in order to get rid of the estimation noise, synchronicity is lost.
2-Continuous Estimation
Continuous estimation has the advantage of low throughput delay. It also has the advantage of no estimation noise due to time segmentation. Time domain compression is not inherently synchronized, and time domain compression algorithms usually do not compensate for estimation delay. As a consequence, traditional level estimation with long time constants is prone to signal overshoots and audible "pumping" effects.
No matter how the level estimate is derived, it always lags behind the signal by a certain time delay. As a consequence, the applied gain is out of synchronization with the signal it is applied to -- unless that time delay is compensated for, which is the case for a new digital chip that has been developed.
Dividing the frequency response into channels puts a lower limit on the time constants of the compression. Too many channels, operating too quickly, results in spectral smearing (see O'Brien 2002 for a review). If it were possible to avoid breaking the signal into channels, the time constants could be much faster.
However, with a traditional linear estimator, if the time constants are made shorter, the estimate follows the level differences, but an unacceptable estimation noise is superimposed. This estimation noise is likely to produce audible signal degradation and therefore the traditional estimation technique is not suitable for use in fast-acting compression systems.
Results:
The analyses above were used to transform an initially FFT-based compressive amplification system into an all-time domain algorithm, featuring the best solutions to each of the above-mentioned factors influencing sound quality. Specifically, the new system incorporates;
- Level estimation with short time constants, based on a nonlinear filtering approach, with a brief 2 ms processing delay.
- Synchronicity between the audio signal and the gain applied to it, and perceptually continuous updates of the gain.
In short, the novel level estimation arising from the investigations of issues outlined here has been implemented into a DSP chip. This chip offers hearing-impaired users clear advantages in terms of sound quality and comfort - findings that have been substantiated by users wearing the product. This chip has been incorporated into the Symbio line of products from Bernafon.
Discussion:
We believe the Symbio line offers a reasonable and thought provoking alternative to previously available digital signal processing technologies. Our preliminary clinical results have been positive. We look forward to continued investigation and analysis of larger clinical populations and we hope to report our results in this venue in the near future.
References:
ISO226 (1986) Equal Loudness Contours
Agnew, J. and Thornton, J.M.(2000). Just noticeable and objectionable group delays in digital hearing aids, Journal of the American Academy of Audiology, Vol. 11, No. 6.
Bustamante, D. and Braida, L. (1987). Multiband compression limiting for hearing impaired listeners. Journal of Rehabilitation Research and Development, 24(4): 149-160.
Dillier, N. (1993). Digital signal processing applications for multiband loudness correction digital hearing aids and cochlear implants, Journal of Rehabilitation Research and Development, Vol. 30, No. 1.
Dillon, H. (2001). Hearing Aids, New York: Thieme Publishers.
Gatehouse S. (2000): Aspects of auditory ecology and psychoacoustic function as determinants of benefits from and candidature for non-linear processing in hearing aids, IHCON 2000, Lake Tahoe.
Hansen, M, (2000). Effect of multiband compression time constants on subjectively perceived sound quality and speech recognition, International Hearing Aid Conference, Aug. 23 - 27, 2000, Lake Tahoe, California.
Lippman, R., Braida, L., Durlach, N. (1981). Study of multichannel amplitude compression and linear amplification for persons with sensorineural hearing loss. Journal of Acoustical Society of America, 69(2):524-534.
Moore, BC (1990). How much do we gain by gain control in hearing aids, Acta Otolaryngolgica,469: 250-256.
O'Brien, A. (2002) More channels are better, right? Audiology Online, https:\\www.audiologyonline.com
Plomp, R (1988). The negative effect of amplitude compression in multichannel hearing aids in the light of the modulation -transfer function. Journal of Acoustical Society of America, 83(6):2322-2327.
Click here to visit the Bernafon website.
