
Introduction
More than anything else, hearing aid wearers want to count on their hearing in all of the situations that they encounter. As the person with hearing loss goes throughout the day, there will be many challenging listening situations. People with normal hearing can immerse themselves in those complex acoustic environments without a second thought. However, for the person with hearing loss, each new environment may pose barriers to effective communication. Hearings aids should break down those barriers and reduce the user's concerns about just how difficult listening will be. Moreover, amplification should sound natural, and become second nature. Hearing aids should not call attention to themselves. Rather, the sound that the user experiences should be as close to real life as possible.
Agil is Oticon's new high end product that significantly extends pioneering developments in the areas of both Spatial Audiology and Connectivity. There are many improvements in signal processing, design and practicalities. However, there are two signature developments in the way Agil processes signals in complex environments (Speech Guard and Binaural Noise Management) and in the manner in which Agil processes sound delivered via the Streamer (PowerBass and Music Widening). Speech Guard represents a new way to process multi-channel signals to maintain as much of the natural dynamics of the signal as possible, allowing for the best preservation of the original signal. Binaural Noise Management intelligently directs the operation of the improved binaural compression, noise reduction and directionality systems to capture the very best listening configuration for the user: full binaural cues when possible but also switching to a focused response if the sound environment is significantly more favorable on one side of the head as compared to the other. PowerBass provides the listener with a dramatically improved fullness and sound quality when listening to music through the Streamer without giving up the important advantages of vented and open fittings. Music Widening creates a fuller, more spacious sound picture for sounds that arrive via the Streamer, moving the image of the sound from inside the head to out there in the environment. Taken together, all of these improvements once again demonstrate the leadership that Oticon has shown in creating hearing solutions that challenge conventional notions of the role of amplification.
Listening in Complex Environments
When considering what it takes to communicate in complex listening environments, sensorineural hearing loss can be thought of as the loss of ability to organize sound. The frequency, loudness and temporal distortions that characterize this disorder have the effect of smearing the fine distinctions between one sound and another. With multiple sources of input at any given time, these fine distinctions are essential for the brain to organize the sound input: to assign each sound that arrives in the ear to the appropriate stream. As the distinctions between individual sounds become blurred, the brain has to work that much harder to organize the world of sound.
When the peripheral auditory system fails to provide the brain with a clear, distinct input signal, the brain must find other ways to reconstruct the message. It will increase the focus on visual cues, it will try to predict what the person is saying, and it will listen more intently to the auditory input to use whatever cues may remain. All of this takes effort, such as the effort to watch the speaker intently, the effort to try to figure out what was just said and what will be said next, and the effort to repeatedly re-examine the auditory input to see if the identity of the words spoken will pop out.
What for the rest of us is automatic and effortless is now a burden on the person with hearing loss. Every interaction requires focus and attention. Casual conversation is no longer casual. It requires the listener to devote full attention to perform the basic task of identifying the words that were spoken. Those with normal hearing can quickly and easily move on to what makes conversation so valuable: the ability to remember what was said, reflect on it and decide what needs to be said next. The enjoyment in conversation is not in just recognizing what is said - it lies in where conversation takes us.
Any serious discussion of what it takes to help those with hearing loss must start with an examination of the true unmet needs of these patients. Although we have made great strides over the years, our patients still struggle understanding speech in complex environments, those situations where there are multiple competing sources of sound and the listener needs to make sense of the cacophony. The first step in crafting appropriate solutions is recognizing that situations such as these are the biggest challenges that our patients face. We recognize that if we are to help those with hearing loss, we must create solutions that address the full range of listening situations that are the most difficult. Directionality can be quite effective for patients, but only in a limited range of situations (Walden, Surr, Cord & Dyrlund, 2004). Noise Reduction circuitry can make noisy situations more tolerable, but it does not directly improve speech understanding (Schum, 2003). Audibility of individual phonemes is of course important, but accurate perception of the entire speech signal across a range of both quiet and noisy situations is the real goal. For years, we have emphasized that simply amplifying and compressing the speech signal is not enough. How you process the speech signal is vital.
For the past several years, we have been discussing the role of hearing aid technology in preserving as much spatial organizational information as possible (Schum, 2007b). Spatial cues are some of the most important sources of information that the brain can tap into in order to organize a complex sound environment. The combination of a broad bandwidth, the smooth insertion response of Receiver-In-The-Ear (RITE) technology, open fittings and, most importantly, the preservation of naturally occurring interaural level differences (ILDs) allow for significantly improved spatial sound scene perception. With Agil, we now extend our emphasis on the preservation of natural cues by turning our focus to the speech signal. Speech is a complex acoustic signature and the details matter to the brain. Our new approach to nonlinear sound processing, Speech Guard, is designed to preserve the speech signal and all of the other sounds in the environment in the most natural state possible, giving the brain every opportunity to re-construct an accurate perception of the world of sound.
We also know the importance of a good signal-to-noise ratio (SNR) and so, when we find the opportunity to clean up the signal, we capitalize on it. Oticon have had one of the most sophisticated directional systems on the market for the past six years (Flynn, 2004). Now, Binaural Noise Management capitalizes on our high speed data transmission between the hearing aids and advanced decision making capability. It finds those situations in which speech understanding can be further enhanced by shifting the focus of the amplification solution to the ear with the better SNR.
With Agil, we have attempted to create a suite of signal processing approaches to improve speech understanding in difficult settings, lessening the need for the hearing aid users to have to work so hard to just be part of on-going life.
Speech Guard
Speech naturally changes in level over time, as each phoneme has its own natural intensity. Further, most phonemes show natural changes in level throughout the course of production. These amplitude changes are an important natural cue that distinguish one speech sound from another and distinguish the speech of a given talker from other talkers and from competing sounds in the environment.
The brain is primed to understand speech in its purest form. The human speech signal is the result of complex movements of the articulators of the mouth and head. These complex movements leave a distinct acoustic signature that the brain can immediately interpret as the intended phoneme of the talker. Every speech sound is comprised of a complex acoustic signature because every speech sound is produced by a set of complex movements (Kent & Read, 1992;Pickett, 1980). The brain knows all of the markers of each speech sound and can easily use whatever markers of a particular sound are available at that moment. If the high-frequency burst of an unvoiced stop is momentarily obscured by a masking sound, the listener can easily tell the difference between /p/,/ t/ and /k/ based upon the timing and frequency change coming out of the preceding vowel or leading into the following vowel. The affricate "ch" as in "patch" is marked by a brief period of silence followed by a burst of energy and then a trailing frication noise. The brain will use any or all of these acoustic markers to identify that sound.
Speech is comprised of intricate, precisely-timed acoustic events and any manipulation of that signal runs the risk of compromising the richly embedded waveform. Our patients with hearing loss need assistance from technology to have full access to the sounds of life. Full access means just that: access to all of the details of the spoken word. Preserving signal fidelity is essential in giving the brain access to every bit of information it needs to organize the world of sound, to select the sound stream that is most intriguing to us and to follow that stream over time.
Making sounds loud enough to hear and applying processing to provide the fullest access to the most important parts of the signal must be accomplished with the utmost of care. The natural intricacies of the speech signal can easily be corrupted by overly aggressive, overly manipulative signal processing. The details of how the speech signal is amplified make all the difference.
In compression systems, there have always been three goals which have been difficult to achieve simultaneously: full audibility for the speech signal;protection against loudness discomfort, especially for rapid onset signals;and preservation of the details of the speech wav3eform to the highest degree possible (signal fidelity).
In order to achieve both audibility and loudness protection, a variety of channel structures and combinations of attack and release times have been used. It has been clearly demonstrated that soft through loud speech can be made audible with the patient being protected against discomfort from sudden loud sounds (Dillon, 2001). Yet this goal has come at a cost;significant modifications to the natural detail of the input speech signals. Traditional fast acting compression systems can maximize audibility on a phoneme-to-phoneme basis, but the result is forceful modifications of the natural waveform of speech. Further, in stable, low to moderate noise environments, fast acting compression will have the background noise "balloon up" in the brief periods between words, phrases and sentences. A number of studies (e.g. Neuman, Bakke, Mackersie, Hellman & Levitt, 1998) have demonstrated that listeners prefer the sound quality of slower acting compression systems, especially in background noise.
However, slower acting compression systems have an important drawback. When a sudden loud sound occurs, the gain of the device will drop in response. Because of the long release time, the gain will stay down for a few moments even after the loud sound has gone away. This drop out effect is clearly audible for the user and can be quite distracting when listening to speech in an environment where loud, extraneous external sounds (clattering of dishes, bouts of laughter, doors opening and closing) occur regularly.
With Agil, we introduce Speech Guard, our new approach to multi-channel signal processing. Speech Guard maintains linear processing as much as possible, while also having an instantaneous response to rapidly-occurring environmental sounds without compromising sound quality or naturalness. In the Speech Guard system, the goal is to make a disconnection between the gain response of the hearing aid to different sound sources that have different intensity patterns. In stable sound environments, the hearing aid maps the full range of the speech signal in a linear manner into the patient's dynamic range. When sudden loud inputs occur, the response of the hearing aid is essentially instantaneous, capturing and suppressing the loud input and then immediately returning back to the linear mapping of the ongoing speech signal. The pumping effect that is so common in multi-channel compression systems is avoided as is the dramatic distortion of the natural, subtle intensity differences within the speech signal. Further, the short-term, sudden loud sound does not compromise the audibility of the ongoing speech signal as can occur in systems with long release times. The effect is to provide even better waveform fidelity, speech audibility and loudness protection than with our previous use of slow acting compression than could be achieved with the dual-mode True Dynamics processing in Epoq (Schum, 2007a).
Speech Guard implements a unique signal processing architecture (Simonsen & Behrens, 2009). Traditional multi-channel input compression systems are designed to have a single monitoring system determining the level of the input signal. This measured input level is then used to determine the gain applied to the signal. The higher the input level, the less gain is applied. The problem with this approach is that the system either has to be a fast response system (which will lead to waveform distortions) or a slow response system (which will lead to the drop-out problem). The design of the Speech Guard system makes this dilemma irrelevant.
Speech Guard implements a pair of analyzers (Figure 1), and the interaction between these two estimators is the key to the system's success.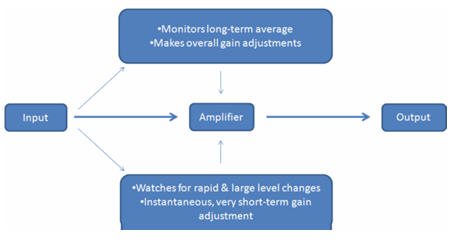
Figure 1: Basic block diagram of the signal processing in Speech Guard.
One analyzer uses a long averaging window, which is designed to provide on on-going estimate of the level of the environment. If there is a dominant speech signal present, this estimator will track the ongoing, overall level of the talker. A second analyzer uses a very short averaging window. This provides information as to the instantaneous input level as opposed to the overall, on-going level.
The levels of the two estimators are compared on an ongoing basis. If the two levels are similar, then the input level estimated by the long-term analyzer determines the behavior of the hearing aid amplifier. If the level of the short-term analyzer is significantly different than the ongoing, long-term average, then the level estimate from the short-term analyzer determines the behavior of the hearing aid amplifier.
The amplifier normally operates with very long time constants, effectively processing the speech signal by making long-term, overall volume control adjustments, but treating the signal as a linear amplifier on a short-term, phoneme-to-phoneme basis. The gain of the amplifier will be determined by the overall level estimate of the long-term average.
If the short-term analyzer detects a signal that is significantly different in level than the long-term estimate, then the hearing aid amplifier transitions to a system with extremely fast time constants. The effect is to immediately respond to a sudden, intrusive sound that jumps in above the level of the ongoing speech signal. The gain is reduced almost instantaneously. However, once the sudden sonic event passes, the gain quickly returns to the level called for by the long-term average.
The effect of this signal processing is to maintain to protect the natural dynamics of the speech signal without sacrificing loudness protection or audibility. Linear processing is needed to maintain the highest signal fidelity. Speech Guard also provides significantly improved sound quality as much less manipulation of the signal is needed. The closer the amplified signal resembles the natural speech signal, the better the chances for accurate perception.
In an upcoming report, Hansen (2010) provides the results of a two site, blinded study comparing speech understanding performance and listening effort ratings from a group of 39 experienced hearing aids users. These users compared Agil with another high-end device with features such as automatic, adaptive multi-band directionality, noise reduction, multi-channel non-linear processing and a broad bandwidth. The core difference between Agil and the comparison device was the inclusion of the Speech Guard sound processing approach.
Adaptive speech understanding in noise was assessed in two different backgrounds and resulted in a significant (p
Using Spatial Information
There is spatial information embedded in every sound we encounter. Although often we are not consciously aware of the spatial quality of sound, our brains constantly use this information to organize the sounds we encounter, allowing us to select and focus on what we are most interested in. The better we understand the physical nature of spatial information and how the listener uses this information, the better we design our hearing aids to work. Sometimes we need to preserve and enhance natural cues, and sometimes we need to capitalize on the spatial characteristics of arriving sound to manipulate the signal and enhance the perception of speech. Either way, we will be better able to meet the overriding goal of hearing aid development: to improve the ability of the patient to hear and understand in difficult listening situations.
There are two general ways in which spatial information can be used in hearing aids. In most situations, we want to provide the brain with as much information as we can to allow natural spatial perception skills to work. This is demonstrated in the way the first generation Spatial Sound compression system works, preserving as many natural cues as possible (Schum, 2007b). The goal is to provide the binaural system with the cues needed to help us organize our world of sound.
When the opportunity presents itself, we also use the spatial characteristics of sounds to manipulate the signal to improve the perception of speech in noise. This thinking is demonstrated in how we use direction of arrival to de-emphasize noisy signals arriving from the back or sides, in current directional systems.
The first generation Spatial Sound system in Epoq and Dual emphasized preserving spatial information at the highest levels possible while maintaining interaural intensity cues. Increasing and smoothing the bandwidth and applying open fittings whenever possible were also emphasized. In Agil, we continue with these important concepts and take the next steps in using naturally-occurring spatial information to assist the user in communicating in the most difficult environments.
Binaural Noise Management
Listeners use binaural cues to assist in perceptually separating the signal of interest from the background competition. However, there are times when the SNR is so different on one side of the head as compared to the other, that we naturally direct our attention to the ear with the better signal conditions (Zurek, 1993). We are able to focus our listening on the signal coming in from one side of the auditory system and suppress the signal from the other. In effect, we override our natural binaural processing in order to take advantage of the significantly better audibility in one ear. This happens under conditions such as driving the car with the window down and trying to carry on a conversation. We also use this approach when carrying on a conversation while walking down a busy street or when talking on the phone in a noisy room.
Binaural Noise Management in Agil works in a similar manner. When the SNR is determined to be significantly better at one of the hearing aids as compared to the other, a series of adjustments are made to try to maximize the audibility in the ear where the speech signal is clearest and to suppress the competition in the ear with poorer signal conditions. This is a direct attempt to support the natural cognitive function of selecting where to listen, in this case, selecting the ear with the more robust signal. Once selected, focussing on the ear with the most favorable signal conditions assists the user in following the target talker over time.
Binaural Noise Management extends upon the use of ear-to-ear wireless data sharing pioneered in Epoq. Now, beyond maintaining the naturally occurring inter-aural intensity differences, we use the shared information between the ears to monitor the noise level and other signal conditions on either side of the head. This data is shared between the ears. When the SNR is significantly different between the ears, the devices shift into the mode where the better ear is emphasized. In this mode, when the SNR is determined to be similar on either side of the head, our Spatial Sound compression system will make the adjustments in gain needed to maintain the natural interaural intensity differences, allowing for a seamless perception of the location of all of the sources of sound in the environment. However, when the SNR is determined to be significantly better on one side of the head the enhanced automatic directional system kicks into action. This maintains full audibility on the ear with the better SNR. On the other ear, gain is reduced and the noise reduction system becomes fully activated. The sum total effect creates up to an 8 dB difference between the ears and concentrates the response of the binaural system towards the better side, pulling attention to the signal that should provide the best chance for speech understanding. All of these actions occur automatically and seamlessly, supporting the natural way in which we all switch between true binaural and better ear listening as the situation demands.
The Binaural Noise Management system was evaluated by a group of experienced hearing aid users in our clinical test pool in Denmark. Over 80% of the test persons stated a preference for Binaural Noise Management system active (versus inactive) when evaluated in asymmetrical listening situations.
Next Steps in Connectivity
Our field has made great strides in developing new approaches to signal processing over the recent years. Most of these approaches have targeted improving speech understanding in difficult listening environments, improving listener comfort and improving sound quality. These developments, however, may not necessarily be a good idea for the music signal. For example, feedback cancellation algorithms have enabled many more open fittings than were previously possible. Open fittings have been important in improving user acceptance by eliminating the occlusion effect for many patients. They have also improved the comfort of fittings and allow natural sound to enter the ear canal, further improving sound quality.
However, open fittings also drastically reduce the low frequency response of the hearing aid. Although this is not a problem for patients who are typically fit with open fittings when listening to speech, it does significantly reduce the quality of music.
In addition, when listening to music via hearing aids coupled to the Streamer gateway device, the music will tend to sound as if it is originating in the head. This reduces the listening experience compared to hearing the same signal played via loudspeakers in a room. When you listen to loudspeakers in a room (or to live music), you hear not only the direct sound but also the delayed reflections of the room. These reflections, as long as they are not too intense or too delayed, will enhance the listening experience, with the sound clearly originating from outside of the head.
Although effective speech understanding is of course the major goal of essentially all hearing aid fittings, there is every reason to want to also maximize the listening experience for other important signals, especially music. Oticon now introduces two new important sound processing approaches designed to enhance the music listening experience for the wearers of Agil.
PowerBass
As described by Minnaar (2010a), PowerBass is a combination of two new signal processing approaches designed to enhance the perception of bass in the response of Agil when listening to music via the Streamer gateway device.
One part of the signal processing routine will immediately increase the bass response of the hearing aid anytime there is available headroom. Even though an open fitting will bleed off many low frequencies in the response of the hearing aid, it is possible to electronically boost the bass response to restore some of this lost energy. However, if you simply put in a static low-frequency boost, there are times when the output in the low frequencies will activate the output limiting compressor due to a lack of head room. This behavior can reduce the sound quality and thus the music listening experience. With PowerBass, the low frequencies are increased in inverse proportion to the amount of low frequencies in the music passage at that point in time. If there are minimal lows, then a significant boost is provided. If there are more lows naturally in the passage, less boost is applied. The result is to maximize the full dynamic range of the device in the low frequencies.
The second aspect of the signal processing in PowerBass makes use of the phenomenon of the "case of the missing fundamental" (Yost & Nielsen, 1994). If you present a listener with a series of tones that are all harmonics of a common low frequency, then the listener will perceive that low frequency tone even though it is not physically present in the stimulus. For example, if a listener is presented with tones at 400 Hz, 500 Hz, 600 Hz, 700 Hz, 800 Hz, 900 Hz and 1000 Hz, that listener will also perceive a tone at 100 Hz. PowerBass makes use of this phenomenon to enhance the perception of low frequencies below the bandpass of the Agil device in an open fitting. When low to mid frequency tonal components with a harmonic structure are detected in the stimulus, those harmonics are enhanced in order to create the perception of the common low-frequency source. This source may not be physically present in the response of the device, but the listener will perceive a low frequency element.
As reported by Minnaar (2010a), listeners with mild-to-moderate hearing loss showed a strong preference for the PowerBass system to be active (compared to inactive) when listening via open fittings to both music and even speech.
Music Widening
Minnaar (2010b) describes a new approach to signal processing of music that is presented through earphones or hearing aids. This approach creates the perception of the signal coming from outside the head, as if it were being listened to in a real room. Since natural room reflections are lost when listening to music via headphones or via hearing aids, Music Widening synthesizes reflections to create the perception that the music is coming from the room and not from the hearing aids. By carefully manipulating the timing, spectral content and level of the reflections (including between ear differences), Music Widening creates a combination of direct sound and delayed sound in such a manner that the signal is "released" back into the room. As reported by Minnaar (2010b), hearing impaired listeners report a strong preference for the activation of the Music Widening algorithm.
It should be noted that, although both PowerBass and Music Widening affect signals that arrive via the Streamer gateway device, the signal processing occurs in the Agil hearing aids. These are complex, computationally heavy algorithms that require the high-capacity, high-speed signal processing available in the new digital platform that was created for Agil.
Rise 2
With the release of Epoq in 2007 came the introduction of a new digital platform called Rise. The major new development with Rise was the inclusion of a wireless transmitter/receiver imbedded as part of the platform. Having high speed wireless on-board enabled the implementation of the important binaural compression system that formed the core of the first generation Spatial Sound system. It also enabled connection of external signals to the hearing aid via the body-worn Streamer. The new features of Speech Guard, Binaural Noise Management, PowerBass and Music Widening are quite resource demanding. In fact, the basic concept behind Speech Guard was developed by the scientists at our Eriksholm, Denmark research center a decade ago. However, the processing resources that were needed to implement the dual sound monitors simply could not be implemented even on the Rise platform without seriously increasing battery drain or sacrificing other essential features. Therefore, it was essential to create the Rise 2 platform as a basis for Agil.
Rise 2 implements a doubled clock speed compared to the original Rise platform. Doubling the clock speed means that there are twice as many processing resources available. Twice as many processing events can take place in the same amount of time. This doubling of the clock speed was accomplished without any increase in battery drain or size. Therefore, compared to Epoq and Dual, Agil is accomplishing twice as much signal processing with the same size digital platform and the same current drain. These processing resources were required to implement the important new features of Speech Guard, Binaural Noise Management, PowerBass and Music Widening.
Summary
Oticon has shown clear leadership in two important areas of hearing aid development: signal process to improve performance in difficult listening situations and connectivity to external audio signals. With the release of Oticon Agil, we extend what we have developed for users in four important ways.
Speech Guard. A revolutionary approach to nonlinear signal processing designed to maintain as much of the fine detail of the speech signal as possible yet still allow the patient to operate in the full range of sound environments without concerns about discomfort or distraction. Two parallel analysis functions are implemented, one monitoring the speech signal and ensuring audibility without manipulating the natural phonemic dynamics and a second that is on the lookout for extraneous sounds that can be distracting or uncomfortable.
Binaural Noise Management. An important extension of our Spatial Sound concept first introduced with Epoq, Binaural Noise Management provides the full range of binaural cues needed for accurate reconstruction of the listening environment. In addition, when the opportunity exists where the SNR is significantly better on one side than the other, the set of binaurally interactive hearing aids will focus the response by maximizing audibility on the side with the better SNR and suppress sound levels on the more challenging side.
PowerBass. A rapid, fully adaptive signal processing to maximize the perception of full low-frequency response when listening to streamed music even when the hearing aids are fit fully open. The low frequency response of the device is maximized on an on-going basis and the harmonic structure of lower frequency sounds is enhanced to fill out the sound quality of the streamed signal.
Music Widening. Rapid, fully adaptive signal processing that creates the perception that streamed music is not coming from the hearing aids but from the room that the listener is in. This perceptual effect is achieved by synthesizing reverberation components to create the perception of listening in a room and not within your head.
References
Dillon, H. (2001). Hearing aids. New York: Thieme.
Flynn, M. (2004) Maximizing the voice-to-noise ratio (VNR) via voice priority processing. Hearing Review, 11(4), 54-59.
Hansen, L. (2010). A Multi-center evaluation of Oticon Agil. In preparation.
Kent, R. & Read, C. (1992). The acoustic analysis of speech. San Diego: Singular Publishing Group, Inc.
Minnaar, P. (2010a). New algorithm designed to enhance low frequencies in open-fit hearing aids. The Hearing Journal, 63(3), 40-44.
Minnaar, P. (2010b). Enhancing music with virtual sound sources. In Press.
Neuman, A., Bakke, M., Mackersie, C., Hellman, S. & Levitt, H. (1998). The effect of compression ratio and release time on the categorical rating of sound quality. Journal of the Acoustical Society of America, 103, 2273-2281.
Pickett, J. (1980). The sounds of speech communication. Baltimore: University Park Press.
Schum, D. (2003). Noise reduction circuitry in hearing aids (2): Goals and current strategies. The Hearing Journal, 56(6), 32-41.
Schum, D. (2007a). The audiology in Epoq. Oticon White Paper. Available from Oticon.
Schum, D. (2007b). Redefining the hearing aid as the user's interface with the world. The Hearing Journal, 60(5), 28-33.
Simonsen, C. & Behrens, T. (2009, December). A new compression strategy based on a guided level estimator. Hearing Review, 26-31.
Walden B, Surr R, Cord M & Dyrlund O. (2004). Predicting hearing aid microphone preference in everyday listening. Journal of the American Academy of Audiology, 15(5), 365-96.
Yost, W & Nielsen, D. (1994). Fundamentals of hearing: An introduction. San Diego: Academic Press.
Zurek, P. (1993). Binaural advantages and directional effects in speech intelligibility. In G. Studebaker & I. Hockberg (Eds.), Acoustical factors affecting hearing aid performance (2nd ed.) (pp. 255 - 276). Needham Heights, MA: Allyn and Bacon.
The Audiology in Agil
April 19, 2010
This article is sponsored by Oticon.
Continued and its subsidiaries provide professional education authored by qualified Subject Matter Experts for continuing education purposes. These materials are intended for educational purposes and do not constitute medical advice or a substitute for individual clinical judgment. Continued is not a clinical healthcare provider; the licensed professional is solely responsible for ensuring that the application of any techniques or information presented is within their legal scope of practice and jurisdictional requirements.


Related Courses
1
https://www.audiologyonline.com/audiology-ceus/course/oticon-government-services-may-2023-38919
Oticon Government Services May 2023 Contract Update
Oticon understands that sudden, disruptive sounds affect a large majority of hearing aid users, making it difficult to stay sharp and focused – especially when engaged in conversation. Oticon Real™ is designed to help with this challenge and keep patients engaged. In this course we introduce new options on the VA hearing aid contact.
auditory, textual, visual
129
USD
Subscription
Unlimited COURSE Access for $129/year
OnlineOnly
AudiologyOnline
www.audiologyonline.com
Oticon Government Services May 2023 Contract Update
Oticon understands that sudden, disruptive sounds affect a large majority of hearing aid users, making it difficult to stay sharp and focused – especially when engaged in conversation. Oticon Real™ is designed to help with this challenge and keep patients engaged. In this course we introduce new options on the VA hearing aid contact.
38919
Online
PT60M
Oticon Government Services May 2023 Contract Update
Presented by Kirstie Taylor, AuD
Course: #38919Level: Intermediate1 Hour
AAA/0.1 Intermediate; ACAud inc HAASA/1.0; ASHA/0.1 Intermediate, Professional; BAA/1.0; CAA/1.0; IACET/0.1; IHS/1.0; Kansas, LTS-S0035/1.0; NZAS/1.0; SAC/1.0
Oticon understands that sudden, disruptive sounds affect a large majority of hearing aid users, making it difficult to stay sharp and focused – especially when engaged in conversation. Oticon Real™ is designed to help with this challenge and keep patients engaged. In this course we introduce new options on the VA hearing aid contact.
2
https://www.audiologyonline.com/audiology-ceus/course/why-evidence-matters-38163
Why Evidence Matters
Oticon has a long history of focusing on innovative research into how the brain processes sound and how technology can support the brain’s natural ability to process sound. In this course we will review evidence supporting Oticon’s technology developments and how hearing care professionals can use this information to discuss benefits and explain why they are recommending Oticon solutions.
auditory, textual, visual
129
USD
Subscription
Unlimited COURSE Access for $129/year
OnlineOnly
AudiologyOnline
www.audiologyonline.com
Why Evidence Matters
Oticon has a long history of focusing on innovative research into how the brain processes sound and how technology can support the brain’s natural ability to process sound. In this course we will review evidence supporting Oticon’s technology developments and how hearing care professionals can use this information to discuss benefits and explain why they are recommending Oticon solutions.
38163
Online
PT60M
Why Evidence Matters
Presented by Lana Ward, AuD
Course: #38163Level: Intermediate1 Hour
AAA/0.1 Intermediate; ACAud inc HAASA/1.0; AHIP/1.0; ASHA/0.1 Intermediate, Professional; BAA/1.0; CAA/1.0; IACET/0.1; IHS/1.0; Kansas, LTS-S0035/1.0; NZAS/1.0; SAC/1.0
Oticon has a long history of focusing on innovative research into how the brain processes sound and how technology can support the brain’s natural ability to process sound. In this course we will review evidence supporting Oticon’s technology developments and how hearing care professionals can use this information to discuss benefits and explain why they are recommending Oticon solutions.
3
https://www.audiologyonline.com/audiology-ceus/course/oticon-government-services-introducing-more-36630
Oticon Government Services: Introducing Oticon More
Sound scenes are dynamic, complex and unpredictable. It is the role of the brain to handle this complexity to hear and make sense of it all. Oticon is committed to developing life changing technologies that support the way the brain naturally processes sound. Get ready to discover the new perspective in hearing care with a fundamentally new approach to signal processing. *This is a recording of the VA Oticon More Introduction Event from May 3, 2021*
auditory, textual, visual
129
USD
Subscription
Unlimited COURSE Access for $129/year
OnlineOnly
AudiologyOnline
www.audiologyonline.com
Oticon Government Services: Introducing Oticon More
Sound scenes are dynamic, complex and unpredictable. It is the role of the brain to handle this complexity to hear and make sense of it all. Oticon is committed to developing life changing technologies that support the way the brain naturally processes sound. Get ready to discover the new perspective in hearing care with a fundamentally new approach to signal processing. *This is a recording of the VA Oticon More Introduction Event from May 3, 2021*
36630
Online
PT60M
Oticon Government Services: Introducing Oticon More
Presented by Candace Depp, AuD, Thomas Behrens, MS, Danielle Tryanski, AuD, Sarah Draplin, AuD
Course: #36630Level: Intermediate1 Hour
AAA/0.1 Intermediate; ACAud inc HAASA/1.0; AHIP/1.0; BAA/1.0; CAA/1.0; IACET/0.1; IHS/1.0; Kansas, LTS-S0035/1.0; NZAS/1.0; SAC/1.0
Sound scenes are dynamic, complex and unpredictable. It is the role of the brain to handle this complexity to hear and make sense of it all. Oticon is committed to developing life changing technologies that support the way the brain naturally processes sound. Get ready to discover the new perspective in hearing care with a fundamentally new approach to signal processing. *This is a recording of the VA Oticon More Introduction Event from May 3, 2021*
4
https://www.audiologyonline.com/audiology-ceus/course/genie-2-fitting-focus-series-36119
Genie 2 Fitting Focus Series: Oticon More First Fit
In this course we will cover the initial fitting steps for a successful Oticon More initial fitting using Oticon’s Genie 2 fitting software.
auditory, textual, visual
129
USD
Subscription
Unlimited COURSE Access for $129/year
OnlineOnly
AudiologyOnline
www.audiologyonline.com
Genie 2 Fitting Focus Series: Oticon More First Fit
In this course we will cover the initial fitting steps for a successful Oticon More initial fitting using Oticon’s Genie 2 fitting software.
36119
Online
PT30M
Genie 2 Fitting Focus Series: Oticon More First Fit
Presented by Amanda Szarythe, AuD, CCC-A
Course: #36119Level: Intermediate0.5 Hours
AAA/0.05 Intermediate; ACAud inc HAASA/0.5; AHIP/0.5; BAA/0.5; CAA/0.5; IACET/0.1; IHS/0.5; NZAS/1.0; SAC/0.5
In this course we will cover the initial fitting steps for a successful Oticon More initial fitting using Oticon’s Genie 2 fitting software.
5
https://www.audiologyonline.com/audiology-ceus/course/counseling-techniques-supporting-standard-care-38697
Counseling Techniques Supporting Standard of Care
Effective counseling practices make a tremendous difference in hearing healthcare. Being able to communicate the benefits of advanced technology in simple language patients can understand is the key element in this process. This course will provide suggestions for consumer-friendly language based on clear benefits when making a strong recommendation for premium technology as the standard of care.
auditory, textual, visual
129
USD
Subscription
Unlimited COURSE Access for $129/year
OnlineOnly
AudiologyOnline
www.audiologyonline.com
Counseling Techniques Supporting Standard of Care
Effective counseling practices make a tremendous difference in hearing healthcare. Being able to communicate the benefits of advanced technology in simple language patients can understand is the key element in this process. This course will provide suggestions for consumer-friendly language based on clear benefits when making a strong recommendation for premium technology as the standard of care.
38697
Online
PT60M
Counseling Techniques Supporting Standard of Care
Presented by Amanda Greenwell, AuD
Course: #38697Level: Intermediate1 Hour
AAA/0.1 Intermediate; ACAud inc HAASA/1.0; AHIP/1.0; ASHA/0.1 Intermediate, Professional; BAA/1.0; CAA/1.0; IACET/0.1; IHS/1.0; Kansas, LTS-S0035/1.0; NZAS/1.0; SAC/1.0
Effective counseling practices make a tremendous difference in hearing healthcare. Being able to communicate the benefits of advanced technology in simple language patients can understand is the key element in this process. This course will provide suggestions for consumer-friendly language based on clear benefits when making a strong recommendation for premium technology as the standard of care.