
Editor's Note: This is a transcript of an AudiologyOnline live expert seminar. Please download supplemental course materials.
I want to cover a topic we all likely encounter on a daily basis, and that is how well our patients understand speech. As audiologists, I think there are some aspects to the nature of speech understanding that we may lose sight of as we work each day.
I am going to start the discussion by asking the question, "What is speech?" I will answer this by giving three ways that are different than how most audiologists would typically answer the question.
Answer 1: Speech is the Acoustic Reflection of Movement
The first way to answer the question is: Speech is the acoustic reflection of movement. Speech is a biologically created sound. It is something created by the articulators of the talker. It is important to recognize the complexity of the acoustic signature of speech. It reflects very precise and complex movements out of the teeth, jaw and tongue. I want you to say the word "slipknot." It takes about 500 milliseconds or so to say that compound word, but within that half-second time period, there may be a half dozen to a dozen precise movements that are made with the articulators in order to produce that relatively simple two-syllable word.
You start by moving the tongue up to the alveolar ridge to start producing the /s/, but at the same time that you are positioning the tongue up in the alveolar ridge and starting to force air through the groove in the center of the tongue. You are also doing something with the sides of the tongue in order to get in the position for the lateral /l/ sound. You then drop the tip of the tongue into the tongue position for the /i/ at the same time as you start to close your mouth to get to the closure phase of the consonant /p/.
While you are in the closure phase of the consonant /p/, you are also moving your tongue back up to the alveolar ridge to be in the position for the next consonant, which is the nasal /n/ sound. As you are releasing the tongue tip from the alveolar ridge you are producing the /n/ sound and you are dropping your tongue into the position to make the vowel sound in the word "knot." You are still being affected by the fact that your soft palate dropped in order to produce the consonant, so there is still a nasal consonant influence on the vowel as you are producing the vowel. Finally, you move back up into closure phase for the final consonant /t/, and you may or may not release the /t/ depending on how you produce the word. Within that very short time period, you are doing many complex movements of the articulators, and all those movements show up in the acoustic signature of what you are producing.
Figure 1 shows the waveform of my production of the phrase "why chew my shoe." I want to concentrate on the difference between the /ch/ affricate sound in the middle and the /sh/ fricative sound towards the end. I put both sounds in that phrase so that the vowels on either side of the consonant were the same. One of the things you should know about the frication part of the /ch/ affricate is that it is created around the same frequency position as the /sh/ sound in the mouth. But the difference between those two sounds is more of a dynamic cue based on movement. Remember, with the affricate /ch/ you have to close your mouth entirely to create a stop period within the affricate and then release it very quickly to create the frication, which is a bit different than the way you produce the fricative consonant /sh/ where there is pure frication all the way through. The amount of time it takes to go from the closure phase to the open phase is much longer in the fricative than the affricate, which is more of a rapid release. Although each of those consonants fill the same frequency region in the spectrum, the consonant changes are very different between them, and it is directly related to the way you are moving your articulators.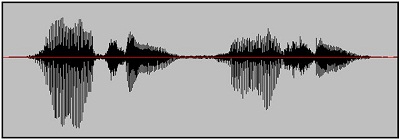
Figure 1. Wave representation of the phrase "Why chew my shoe."
Figure 2 shows the spectral qualities of the word "change." It is a short, single-syllable word. It can be said in far less than a half a second, but there are still tremendous changes occurring due to the movement taking place in the mouth. There is the closure phase at the /ch/. The mouth is opening as you are going throughout the frication portion of that /ch/ affricate, and you can see that the amplitude changes over time. There are intensity changes for the vowel within the word over time. Oftentimes we talk about the notion of steady-state vowels, but in reality, vowels are rarely steady state in conversational speech. They change in amplitude and frequency over time because you hardly ever keep your tongue in exactly the same position or your mouth opening in exactly the same shape. You may move towards a theoretical tongue position and jaw position for a particular vowel, but the reality is you never stay in that position.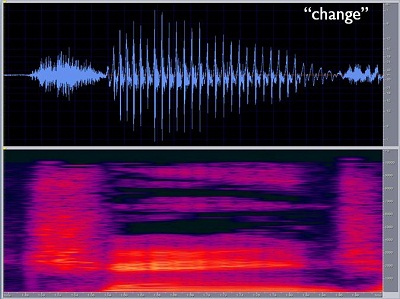
Figure 2. Spectrogram of the word "change."
There are very few situations when the articulators are still. When you sing a musical note you tend to be very stable, but we do not sing when we talk. Talking requires a constant movement pattern, especially if you are someone who tends to talk a little more quickly than others.
Next, you have a rising second formant during the /a/ sound in "change" (Figure 3). You have the nasal murmur towards the end of "change," which is a hole in the spectrum or a lack of sound because of the dropping of the soft palate. Throughout the course of that single word, you produce a lot of movement. All that movement has to be reflected in the acoustic waveform, and it is. However, when it gets transmitted through hearing aids or cochlear implants, it is important to try to preserve as much of that information as possible. Having an appreciation for how complex that information can be is part of the appreciation of what is going on.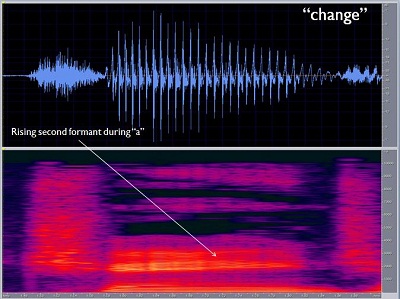
Figure 3. Indication of the rising second formant in the vowel production of the word "change."
Answer 2: Speech is a Path to the Intent of the Talker
A second way to answer the question, "What is speech?" is from a cognitive or psycholinguistic viewpoint. Speech is a path to the intent of the talker. What I mean by that is that when you listen to speech, you do not care what the acoustic signature is. You only care about the acoustic signature if you are having trouble understanding what the talker is saying, but your desire is that you are totally unaware of the acoustic signal. This means that when you listen to somebody talking, you are immediately trying to get to the meaning. You are trying to understand the message that the person is trying to transmit to you, not paying attention acoustically to what the person is doing.
I will talk later about the importance of cognitive processing on listening to speech. Remember that the end goal is speech understanding: to understand the message that I am trying to get across to you. I happen to be using acoustic medium in this seminar. I could have done it in writing. I could have done it in sign language. I could have done it by having you read my lips. There are many different ways I could have presented the same message. It just so happens that the acoustic transfer path is one of the most efficient ones, and it is the one we use in many cases, especially in distance learning formats.
Answer 3: Speech is a Stream in a Bigger River
The third way to answer the speech question then is, "A stream in a bigger river." Often when we are listening to speech, we are in more complex listening environments where there are other speech signals going on. That brings up the age-old observation that an engineer would describe noise very differently than the way your typical patient is going to describe noise. The typical patient with sensorineural hearing loss is going to describe noise as the sounds of other people talking that are interfering with communication.
One of the most common, yet difficult, tasks that listeners with sensorineural hearing loss have is the ability to extract one speech signal from a combination of competing talkers. That becomes a very big part of the listener's task. The speech signal can be very similar to those talkers in the background, and it becomes very difficult to distinguish the talker of interest against all other similar background voices. It blends in, so to speak. From a cognitive standpoint, the listener must pull out parts of the acoustic signature, pay attention to the message and ignore other parts of the acoustic signature that are very similar, yet unimportant. That is not something that can be accomplished purely on an acoustic basis. There has to be some higher-level linguistic and cognitive effects that are happening when you are listening to speech. It reaffirms the point of how cognitive speech understanding can be.
Look at Figure 4 quickly.
Figure 4.
When you looked at that, what sentence or sentences did you see? Did you identify three sentences? If you scanned it quickly, it would approximate the time it would take for me to produce one of those three sentences verbally. The three sentences are on top of each other. What if I expected you to pull out one of the sentences and ignore the other two sentences, and it did not matter which of the three sentences you paid attention to? Truthfully, you probably did not see any of the sentences, so look back at Figure 4 again. The three sentences were: She said give me a kiss; See Fred bring us the fish; The watch is on my wrist.
The reason I showed you this is to point out the difficulty of differentiating sentences when there are no cues to help distinguish one subject or talker from another. It is very difficult to know which parts link together with one sentence and which parts link together with the other sentences that you are trying to ignore. The reason why this is particularly difficult is that there are no distinguishing characteristics that tell you which words go with what sentences. A situation like this is very similar to that of listening to one talker in the background of other talkers, but normally we have some cues that allow us to differentiate one talker from another.
Listen below to the sound sample of different talkers. I want you to listen and determine if you can actually hear three different talkers.
First of all, did you hear three different talkers? It may have been difficult to follow any particular talker from beginning to end, because they do overlap. They are mixed at a 0 dB signal-to-noise ratio, meaning that all three talkers were presented at the same overall intensity level. But there were characteristics that allowed you to hear the difference between one talker and another. That does not mean that you are able to make out everything that they are saying, but certainly you were able to tell that there were different voices there at given moments of time. This was very much a cognitive task. In other words, the acoustic signature is very complex, and there is nothing particular in the acoustic signature that differentiates one voice from the other without applying some other higher-level information. All three talkers have about the same long-term average spectrum of speech, so there are other differences than spectrum and intensity that allow you to tune in and hear one talker from another.
Historically, when we look at the way we talk about speech understanding and audiology, we use what I refer to as the acoustics approach. We try to explain speech understanding on the part of a person with hearing loss based on the acoustic signature that they can hear and have access to without hearing aids or implants compared to the acoustic signature of what they get after they have been treated with technology. Changing access to the acoustics of speech through treatment with hearing aids or any other device is clearly important. If a person cannot hear a sound and then all of a sudden they can because they received technology, you have done something very important for the patient. But the problem with the acoustics approach is that it does not completely explain everything that goes on in terms of speech understanding. Make no mistake about it: it does explain an important building block. The more audible the signal is, the better able the patient is going to be able to have access to the information in the signal.
One of the limitations we show as a profession is that we focus so much on the acoustic approach that we act as if we believe that as long as we make the acoustics available to the patient, we have done everything required of us in our professional role. In reality, there is so much cognitive processing taking place as part of speech understanding that the acoustics approach does not totally explain everything going on.
Let's take a look at what the acoustics approach does do for us. As you know, one of the goals of fitting hearing aids is to take a relatively broad range of speech information with varying intensities and frequency- composition and somehow fit that into a reduced dynamic range for a person with sensorineural hearing loss. Much of what we do in hearing aid treatment is related to how we use technology to move this range of speech into the remaining dynamic range of the patient. Can we make soft sounds audible? Can we make moderate sounds audible and comfortable to the patient? Can we make loud sounds loud without being uncomfortable to the patient?
What is the best way to process a sound to get it into the remaining dynamic range of the patient? Showing the acoustics of speech on the audiogram is a very common technique that is used to explain why a patient has difficulty understanding without hearing aids. Patients typically do not have access, especially in the mid to high frequencies, for important consonantal information. That explains the hear-but-do-not-understand reports from patients. It is very much part of our heritage and culture to talk this way, and it helps us to make a case for the need for amplification to many patients. However, it does not explain the underlying aspects of everything going on.
We do know that audibility is necessary for speech understanding, but exactly how much audibility is necessary? We may believe that more is better, and I think that that is a legitimate statement, but there are limitations to how much we can actually provide patients. You have a broad range of speech input levels from soft to moderate to loud, and you have to be able to manage that range of inputs without causing excessive compression or distortion. Additionally, you do not want to create feedback or sound quality issues. So the question then comes up, "How much audibility do we need to provide?"
As we know, a common verification technique is speech mapping. Figure 5 shows a speech map for a patient with a moderate, flat audiogram, and the green area is the amplified speech spectrum for that particular patient. When we look at this amplification curve, we ask ourselves, "Is that enough?" This amplified signal is not fully audible by the user. Clearly, some information in the very high frequencies is below threshold. A significant amount of acoustic energy below 1000 Hz is not audible for that patient. But how do you interpret that result? Is that good enough or not? We have turned to having a visual verification approach where we try to make as much of the input as audible as we can, but there are some areas where we cannot make it all audible.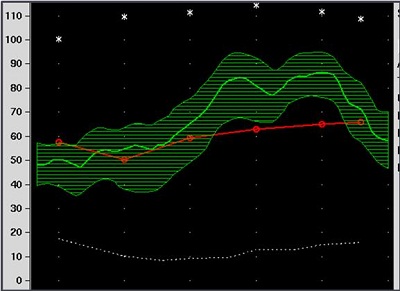
Figure 5. Speech map of a flat, moderate hearing loss.
We almost get to the point of saying, "Well, that is probably good enough," but the reality is that there are tools and analyses that can be used to tell you whether that is enough or not. Most of them are based off the Articulation Index (AI) or the Speech Intelligibility Index (SII). These indexes are based on the notion that the importance of speech changes across frequency: some frequency regions are more important than others. Figure 6 is a plot of the important function of speech across frequency from the Articulation Index. This shows that speech in the 2000 to 3000 Hz range is more important to hear than speech in lower frequencies. If you take a look at the frequency regions where different types of information get transmitted, you notice that there are more classes of phonemic information in the 2000 to 3000 Hz region than in other frequency regions.
Figure 6. Speech importance as a function of frequency.
We focus greatly on the mid to high frequencies because that is where much of the meaningful speech information is located. Importantly, however, if you get an AI or SII value (which vary from 0 to 1.0 and which you can interpret in terms of 0 percent to 100 percent of speech information transmitted), how much of that information is necessary to be able to carry on a conversation? There have been analyses completed on this subject. DePaolis and colleagues (1996) looked at the relationship between an AI value, ranging from 0 to 1, and percent-correct for connected discourse. They noted that by the time you have approximately 70 percent of information transmitted, which correlates to a score of 0.7 on the AI, the percent-correct score that patient receives for connected discourse is going to be near 100 percent. The SII result for that speech map in a test box would likely be on the order of 0.7 to 0.8, because there is good audibility in that region where most of the information is being transferred. From that, you can confidently say that the person should be able to hear and understand conversational speech relatively well.
The conclusion from this study is that you want to get your AI value around 0.6 or higher, because then you can be more confident that the person should be doing well with conversational speech. Keep in mind that this is for adults who have already learned language; the issues surrounding pediatrics are different. We are not going to discuss pediatrics in detail today, but it does bring up a phrase that is used often within the pediatric field, and that is that speech is redundant. This means that you do not need to hear the entire speech signal in order to understand it. The AI is a way to look at how much acoustics are necessary to understand.
It is absolutely important to get the acoustics right in a hearing aid fitting, but it is not sufficient. There are other things to consider, and one of them is the ability of the brain to put the message together. The goal of speech understanding from a cognitive standpoint is automatic object formation. That means that without having to put in any extra listening or cognitive effort, you immediately understand the words that are said. The bottom line of automatic object formation is that the acoustics of the signal do not really matter, as long as you understand the message.
For example, if you are using some combination of acoustic and visual cues, that is all that matters as long as you understood the message. The cognitive system is primed to use whatever information is available to understand the message, be it acoustic, visual or from some other source. The acoustics in and of themselves are not the issue. The issue is whether or not you understood what the person wanted to say.
We normally talk about speech understanding as a process in which acoustic information comes into the auditory system and somehow it allows for understanding of words. The reality is that understanding is not solely based on acoustic information, but also other stored central information: how often certain words are used, the sentence structure that is being used, situational cues, the stress pattern, and other linguistic/central influences. The reality is that these become extremely important, especially in complex environments when the speech signal is not fully audible to a person or when the speech signal is interrupted by other voices. Your ability to link together a complex speech signal can be driven by your ability to put together information well beyond just the acoustic signature. One of the basic points I am trying to make in this lecture is that the acoustic signature is one path to understanding, but there are other paths that are used frequently by listeners, even those with hearing loss.
What I want to do next is play a sample of the three different voices for you one more time, and I want you to try to pick one of the voices out and follow that voice for as long throughout the segment as you possibly can.
How did you do? It is a difficult task, right? But you probably caught certain phrases and snippets where you were able to follow one speaker over time. The most prominent acoustic event at any given time will alternate from one talker to another, but you do have a sense that there are different talkers and that they are saying different things. Figure 7 shows the spectrum of that same recording. Frequency is on the Y axis, with 10,000 Hz at the top of the Y axis. Time runs along the X axis. The brighter the color, the more intense the speech was. The softer and the darker the color, the less intense it was. The bright yellow spots at the bottom represent the relatively intense low-frequency energy that is in the speech. You can see that the darker areas are up in the high-frequency region, where sounds tend to be weaker or where there is no sound at all.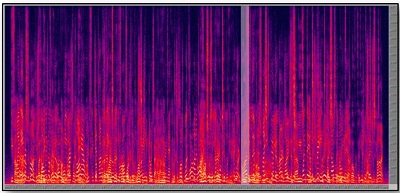
Figure 7. Spectrogram of recorded speech, with higher intensity shown as brighter colors, noted in the low-frequency region along the bottom portion of the Y axis.
Although there are three voices at once presenting a complex signal, cognitively, in most cases, you do not hear just one complex sound; you are already in the process of disentangling those sounds and hearing two or more different voices happening at the same time. What do you use to separate those signals? The answer is, "Whatever you can use."
Your brain will latch onto whatever differences are present between those speech cues. The two biggest ones are fundamental frequency and timbre, which is the quality of the voice. When you listened to those three voices, you probably noticed that one of the male speakers had a mellow quality to his voice. The other male speaker had more nasality, and the female sounded like a female, which is partly due to the fundamental frequency, but there are also other things contributing to that distinctive sound. It is a very automatic process your brain uses to recognize that there are different voices occurring simultaneously. If you try to use only an acoustic description of what is going on, it does not get you very far, because there is so much acoustic information on top of other acoustic information. Using cognitive skills extracts the voices one from another.
Speech understanding from a cognitive perspective is what I call a triple-X feature. What I mean by that is that your brain has the responsibility when it is listening to speech to put together information that is occurring in three domains: across frequency, across time and between two different ears. Most speech sounds have a relatively broad energy pattern, or at least loci of energy in different frequency regions. Maybe they have a formant structure. Maybe they are a nasal that has some sound and lack of sound in different areas that are important for you to put together in order to hear the quality. Remember that frequency resolution in the auditory system is relatively precise, and even in the presence of sensorineural hearing impairment, you still get some amount of frequency resolution.
In order to put speech sounds together, and disentangle one speech sound from another, you have to do comparisons across frequency and time. Phonemes last much longer than the firing period of neural fibers, meaning that you have to track firing patterns across time even to recognize an individual phoneme. Linguistically and cognitively, an utterance does not take on meaning until you can track it over time and put the meaning together over time. Between ears refers to the fact that, in most situations, you are listening with two ears. In realistic situations, the sound pattern from one ear is going to be slightly different than the sound pattern at the other ear, however you are left with a single, unified image. Those are all cognitive functions that put this information together across frequency, across time and between the ears.
Two terms that cognitive psychologists introduced into the description of speech understanding are auditory scene analysis and stream segregation. Those terms refer to the ability to organize all the sounds in a new environment and assign meaning to those sounds, or assign source information to them. This is one voice. This is another voice. This is the air conditioner blowing. This is traffic outside the window, et cetera. You create a map of the acoustic environment you are in, and then you typically pay attention to one particular stream and follow that over time. Certainly that is the only way you can get any information out of complex speech over time.
One of the ways that we at Oticon tend to talk about it is the process of organize, select and follow. When you are in a complex environment, the first thing you do is organize that sound scene in your mind. You select which parts of it you want to pay attention to and which parts you want to suppress, and then you follow what you are attending to, over time. Those are all cognitive processes. In other words, for the same acoustic signature, you can decide to listen to parts of it and ignore other parts, but then you can change your mind and listen to certain parts of it and ignore the parts that you were just paying attention to. It is the ability to select which parts become cognitively salient to you and where you tend to get information. You are in control of which parts you decide are the message and what parts are the background, and that can change over time.
Imagine being in a situation where you are listening to a couple of different conversations and being able to switch between those conversations. One of the things we know about patients with sensorineural hearing loss is that they have increased difficulty switching between different conversations. There are certain situational factors that will affect speech understanding in noise, so when we talk about complex environments, it is important to be honest with ourselves about what complex listening environments are. It is not speech babble off a recorded disc. It is not white noise or speech noise on your audiometer. It is usually competing information, usually other talkers or a shift of which talker you are listening to. There could be some non-speech sound sources in the room such as traffic noise or air conditioning, but oftentimes the most difficult listening situation is one where there is other information to be paid attention also. The task of the listener is to decide what sources of information are useful and what sources should be suppressed.
When looking at the degradation of speech in the presence of competing noise, we know that competition with linguistic content is harder to suppress than competition with nonlinguistic content. Work from 15 years ago looked at the effectiveness of different maskers (Sperry, Wiley, & Chial, 1997). Subjects listened to speech at different signal-to-noise ratios in (1) the presence of speech-shaped noise, (2) speech in the presence of another talker but played backwards (what that does is give you an acoustic signal that has the characteristics of speech, except there is no linguistic information competing for attention) and (3) a competing talker played forward.
The long-term average speech spectrum of both the speech signal and the competition were matched. The results showed that, across signal-to-noise ratios, the easiest competition to listen to was a speech-shaped noise because there was no linguistic content. The second easiest was the speech message played backwards in which some of the linguistic relevance is removed. Although it sounds similar to speech, it is not recognizable because it is played backwards; there is no complete linguistic message presented. The most difficult condition was a competing sentence, where someone else was saying something meaningful. At that point, there are two messages coming into the auditory system. Acoustically, they are both passing through the peripheral auditory system, and it is up to the cognitive system to decide which message to pay attention to and which message to ignore.
An interesting demonstration of something similar is known as the picket fence effect, originally published out of Wright-Patterson Air Force Base (Brungart, Simpson, Ericson, & Scott, 2001). In this case you would listen to speech over time in the presence of nonlinguistic background competition like speech-shaped noise. You would then evaluate a person's performance in this condition and then in a second condition in which you interrupt the background noise at regular intervals. It turns out that people with normal hearing and, to some degree, people with sensorineural hearing loss, do better in the condition where background noise is interrupted. The idea of the picket fence effect is that you are able to listen during the gaps and make use of some of the phonemic information that may have been inaudible when the speech-shaped noise was consistent. When you interrupt the noise, those phonemes become audible, and you use them to improve your overall performance.
The variation in this particular study was that, instead of having speech-shaped noise as the background, they had competing talkers as the background noise. This was more of a realistic listening situation. When they interrupted the competing talkers and looked at performance, the patients performed better when the background was consistent than when the background was interrupted. This means that it is not just the acoustic cues that are available to the listener, but also the completeness of the competing noise.
The explanation is that in this situation where the competing talkers interrupt, you cannot create a holistic message that you can then park away somewhere and ignore. This message is providing partial information, but in reality, it is distracting the cognitive system because it is not whole. It is very inconsistent, but when you make that competition whole, your cognitive system is able to label it as a separate source of information and then ignore it. The lesson from the study is that if you want to ignore a separate talker, you need to hear and understand what they are saying first. Somewhere deep down in the cognitive system, it is able to recognize that as an alternate message and store it away to then concentrate on the primary message that you are trying to pay attention to.
Another factor that will affect speech understanding from a cognitive viewpoint is how you decide to distribute your cognitive resources. In other words, you only have so much brainpower to use at a giventime, and it is divided between multiple actions and attention almost all the time. You have the ability to decide how you are going to distribute your cognitive resources. As the primary speech understanding task becomes more difficult, you have fewer resources left over to do other tasks.
If understanding what is being said is the primary task, the secondary task of listening to what is on the television or typing an e-mail tends to suffer. On the other hand, if the primary task is more important than listening to what is going on, such as driving a car, then comprehending speech information becomes a secondary task. If the primary task of driving safely becomes more difficult, then the ability to hear and understand what is being said it going to be even more diminished. Hopefully you recognize that a certain amount of dual tasking is possible, but you need to make smart choices when the sum total of cognitive resources exceeds what you can do effectively in a simultaneous manner. Interestingly, listeners are very facile at deciding how they are going to distribute cognitive resources; we do it without really thinking about it.
Clinical Confounding Factors
With speech understanding, however, there are some clinically confounding factors. The largest one we deal with is sensorineural hearing loss, of course. One of the things we know about sensorineural hearing loss is that there is poor coding of the acoustic signal. Because of the loss of fine tuning in the peripheral auditory system, temporal and loudness-based distortions occur. The sum total of all the psychoacoustic abnormalities that come along with sensorineural hearing loss means that the precise detail of a given spectrum may not be transmitted through the peripheral auditory system. Remember, speech understanding does not happen in the periphery. It happens in the brain, but it is based on how distinctly the signal is coded by the periphery. With a breakdown in coding, it becomes much harder for the central system to do its job. That is why I like to refer to sensorineural hearing loss not so much as a loss of sensitivity, but more the loss of ability to organize sound.
When patients talk about their problems in noise, they do not talk about what they do not hear. They talk about hearing too much. They talk about being overwhelmed by sound, about not being able to keep sounds separate from each other. I think there is value in focusing more on this loss of the ability to organize sound, and not so much what the person does not hear. We already know they do not hear soft sounds as well. Hearing aids do a fairly good job of overcoming that, but what the patient truly struggles with is this lack of organizational ability that is driven by some of the inherent characteristics of sensorineural hearing loss that are not necessarily solvable by technology. Hearing aids cannot improve the fineness of the coding of the periphery, because that happens after the hearing aid does whatever it is going to do.
This notion of talking about the loss of the ability to organize sound is a good way of putting the roles of sensorineural hearing loss and technology into perspective. There is variation from patient to patient in the degree of organizational difficulty. A study out of UCLA (Dirks, Morgan, & Dubno, 1982) looked at the variability from a normal hearing group to a group of patients with sensorineural hearing loss on a variety of different speech-in-noise tasks. The variability was high in the study, but as audiologists we expect this. We know that one person's speech perception score is going to be very different from another patient's, even though they have the same audiogram.
Effects of Age
The variability does not reflect a difference in the sensitivity loss between the patients, because that sensitivity loss is very similar, but rather a difference in each patient's ability to organize sound. Some of it is driven by the specific effects of sensorineural hearing loss in one ear versus another, but some of it might also be driven by age-related differences in neural processing.
One of the things that has been observed by numerous researchers in the area of cognitive processing in older individuals is a general sort of neural slowing, meaning that the neural fibers in the brain do not function as efficiently as they did before. There may even be a loss of fibers. Those fibers do not fire in rapid, organized ways like they used to, so many of the cognitive issues that seem to occur in the presence of normal aging may be related to this notion of neural slowing. This does not include disorders such as Alzheimer's or dementia, but, rather, refers to normal, age-related changes.
In a model of speech understanding called multiple cue speech processing, when the acoustic information from the peripheral auditory structures is not clear because of sensorineural hearing loss, then the brain moves to all these centrally-stored sources of information to make up the difference. However, in the presence of age-related neural declines, the ability of the person to access stored information to be able to do predictive speech understanding and use situational cues also gets corrupted in older patients because of this neural slowing. So what you end up with are older patients who have both sensorineural hearing loss and a decline in the ability to use centrally-stored information. That combination creates a double-whammy effect, where they cannot count on either side of the equation to hear or understand well in difficult situations.
The last point that I want to make on this cognitive processing issue is the speed of information flow. When we listen to talkers, we are usually dependent on the speed at which the talker decides to present information. One of the things that we know is that older listeners cannot handle speech efficiently at a faster rate. When you take a look at the difference in speech understanding between younger and older adults, performance starts to decline as the speed of information gets faster (Wingfield & Tun, 2001). It does not mean that the acoustic signal was not there. It is just that the information that they are able to draw out of that is less or of poorer quality because their cognitive systems take more time to process that information. Normal aging affects all older individuals at some point in time. When you are sitting across the table from a person with sensorineural hearing loss and they want to know why they have trouble listening in difficult environments, it is not just the effect of sensorineural hearing loss, but there is also the potential that their cognitive system is less efficient than it used to be.
To wrap up this seminar, there are many things that account for speech understanding. Is the signal audible? Is it above the background noise level? The classic ways we examine this is to ensure the signal is audible, and, moreover, audible above the background noise. Other aspects that are not as obvious may be how sensitive to noise the patient is. Additionally, where does the noise come from in the person's environment? Does the person have the ability to resolve where different sounds are coming from and use that information and suppress sounds coming from another direction?
A bigger issue, perhaps, is the composition of the noise. Is there a linguistic component to the noise? Linguistic components in the noise make speech understanding more difficult than listening in steady-state noise. The clarity and rate at which the talkers produce speech has an effect on speech understanding as well. Does the listener have access to other support cues? And finally, how good is the patient at piecing together a partial signal? There are variations even in non-elderly individuals in terms of how well people can use centrally-stored information. Some people are better at solving interrupted speech puzzles than others.
My final point is that the traditional way of looking at speech understanding and sensorineural hearing loss does not totally capture the entire challenge. Without understanding the nature of the cognitive problem, it is hard to have a complete understanding of how this process happens in a listener. Thank you for your time.
Brungart, D.S., Simpson, B.D., Ericson, M.A., & Scott, K.R. (2001). Informational and energetic masking effects in the perception of multiple simultaneous talkers. Journal of the Acoustical Society of America, 110(5), 2527-2538.
DePaolis, R.A., Janota, C.P., & Frank, T. (1996). Frequency importance functions for words, sentences, and continuous discourse. Journal of Speech and Hearing Research, 39(4), 714-723.
Dirks, D.D., Morgan, D.E., & Dubno, J.R. (1982). A procedure for quantifying the effects of noise on speech recognition. Journal of Speech and Hearing Disorders, 47, 114-123.
Sperry, J.L., Wiley, T.L., & Chial, M.R. (1997). Word recognition performance in various background competitors. Journal of the American Academy of Audiology, 8(2), 71-80.
Wingfield, A., & Tun, P. A. (2001). Spoken language comprehension in older adults: interactions between sensory and cognitive change in normal aging. Seminars in Hearing, 22, 287-301.

