
Audiologists have an odd job to begin with, and then, every year or so, they have to absorb and understand yet another new fitting method. Our arsenal includes a plethora of hearing aid fitting protocols which are essentially intended for sensorineural hearing loss, and an end organ (the cochlea) most of us have never seen! Optometry is so different because most vision loss is 'conductive' in nature. For typical vision problems, lenses are fit either correctly or incorrectly. In our profession, however, there is no one fitting method that is universally accepted as 'correct'.
Fitting Rule History:
Fitting methods based on the half-gain rule (Lybarger, 1944, 1963), were the first to arrive at our doorstep. In this group, the more popular members are Berger (Berger, Hagberg, & Rane, 1980), POGO (McCandless, 1983), and NAL-R (Byrne & Dillon, 1986). The half-gain methods, intended for fitting linear hearing aids, all offer a single gain target for any particular hearing loss because linear hearing aids provide the same gain for all input levels. Fitting methods intended specifically for compression hearing aids offer more than one target, because compression hearing aids provide different gain for different input levels.
In the past decade an arsenal of compression-based fitting methods has emerged, with the most popular of these being DSL (Seewald, 1992), Fig6, (Killion & Fikret-Pasa, 1993), and IHAFF (Cox, 1995). Now, there is a new kid on the block: the NAL-NL1 (Dillon, Katsch, Byrne, Ching, Keidser, and Brewer, 1998). The name 'NAL-NLl' stands for National Acoustics Labs, Non-Linear, version 1.Prescribed gain by the various fitting methods markedly varies for any one particular hearing loss because they all emerge from differing fitting philosophies. The half-gain, linear-based fitting methods differ in prescribed gain even for the typical, mild-to-moderate sensorineural hearing loss (Figure 1).
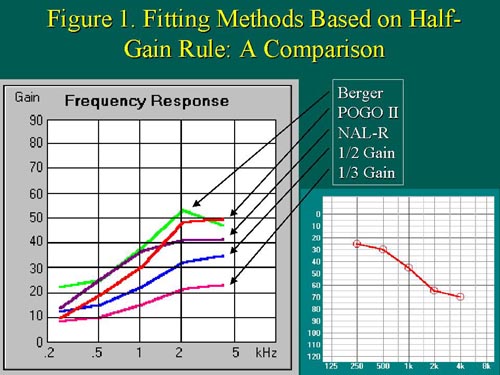
Figure 1. Five different methods, all based on the half-gain rule, give different targets for the same hearing loss. Importantly, the differences among the targets themselves, vary with different hearing losses! size=1>
The same is true for compression-based fitting methods. The purpose of this article is to describe the NAL-NL1 fitting method and also, to show how and why the gain prescribed by this method differs from the gain prescribed by other compression-based fitting methods. In particular, we will examine the differences between the NAL-NL1 method and the DSL method, from the viewpoints of both the NAL-NL1 proponents and the DSL proponents.
NAL Philosophy:
To become familiar with the NAL-NL1 fitting method, it is important to understand the cornerstone philosophy behind the whole NAL 'family' of fitting methods (NAL, NAL-R, NAL-NL1). All of these methods try to equalize, rather than normalize, loudness relationships across speech frequencies. According to Dillon, et al. 1998, if all of the speech frequencies of speech are amplified so that they are heard equally loud, speech intelligibility is maximized.
However, with normal hearing, vowels are louder than are unvoiced consonants (Figure 2).

Figure 2. The slope of the intensity present among adjacent speech frequencies tends to rise from left to right on the typical audiogram. Vowels are more intense and lower in frequency compared to most consonants, especially the unvoiced consonants such as /s/, /f/, /th/ etc. In general, speech sounds on the left (vowels) are heard louder than those towards the right (unvoiced consonants). size=1>
According to Dillon, et al. (1998), when other fitting methods try to preserve this normal relationship of loudness among the speech frequencies, they tend to prescribe too much gain for the low frequencies. Consider: if the intensity differences among the adjacent speech frequencies is preserved so that vowels are heard louder than consonants, then vowels (lows) will be consistently amplified so that they are heard louder by the person wearing the hearing aid. The NAL methods, on the other hand, do not try to preserve or normalize this loudness relationship among speech frequencies; instead, say Dillon, et al. (1998) they strive to normalize loudness only for the total speech spectrum as a whole.
NAL History and Development:
The history and development of the NAL family of hearing aid fitting methods supported and initiated the NAL-NL1 fitting protocol. The original NAL fitting method developed by Byrne & Tonnison (1976) began with the goal of maximizing speech intelligibility, by making all amplified speech frequencies contribute equally to its overall loudness. Subsequent research, however, showed this goal was not achieved because at most comfortable listening levels, amplified speech frequencies were not truly equally loud. The original NAL prescribed too little low-frequency gain relative to mid and high-frequency gain, and too much high-frequency gain for precipitous high-frequency hearing losses.
Byrne & Dillon (1986) revised the NAL fitting method into what we commonly know as NAL-R. One figure in their article shows NAL and NAL-R targets superimposed on a fictitious flat audiogram of 0 dB HL, and reveals that the revised NAL provides about 10 dB more gain at 500Hz, and about 3-4 dB more gain at 3000 and 4000Hz than the original NAL. In general, NAL-R provides slightly less than half-gain across the audiometric frequencies. The target gain configuration of NAL-R is usually 'flatter' than those prescribed by most linear fitting methods. Many audiologists believe NAL-R is 'kind' to steep, high-frequency hearing losses because it prescribes less high-frequency gain than Berger or POGO. Perhaps the ability to reach NAL-R targets with available hearing aids psychologically adds to its allure. At any rate, NAL-R remains the most popular method for fitting mild-to-moderate hearing losses in North America.
A further development of NAL-R resulted in the NAL-RP (Byrne, Parkinson, & Newell, 1990). NAL-RP is identical to NAL-R, except that it includes some additional specific considerations for severe-to-profound hearing losses. First, the authors noted that persons whose audiometric pure-tone average (.5, 1, and 2kHz) is greater than 60 dB, generally prefer about 10 dB more than half-gain. Second, they discovered something very important and unexpected in people with sloping severe-to-profound hearing loss. If the hearing thresholds at 2kHz were 90 dB or more; those clients actually preferred more low-frequency gain and less high-frequency gain than their counterparts who have a more flat hearing loss configuration!
For this population, the goal is no longer even to equalize the loudness of speech frequencies, because the audibility of high-frequency elements of speech did not seem to contribute much to their speech intelligibility performance at all. The main implication here is: amplify less at frequencies where there is severe-to-profound hearing losses, and amplify more at frequencies of better hearing. The contributions to overall loudness of speech from hair cell regions where there is severe-to-profound hearing loss would appear to be less than one might think.
The NAL-NL1 Fitting Method:
The basic NAL philosophy of equalizing, rather than normalizing the loudness of adjacent speech frequencies continues to be the cornerstone philosophy behind the new NAL-NL1 fitting method for compression hearing aids. Additionally, NAL-NL1 includes specific considerations of NAL-RP, regarding amplification for those with severe-to-profound hearing loss. Literature describing the development of NAL-NL1, differentiates between the terms 'audibility' and 'effective audibility' (Dillon, et al. 1998).
Audibility can be measured in terms of sensation level, if actual hearing thresholds are known. 'Effective audibility', on the other hand, refers to how much information can be extracted from speech sounds once they are audible. According to Dillon, et al. (1998), as hearing loss increases, people tend to have more 'effective audibility' with less audibility. In other words, for patients with severe or greater hearing loss, a small sensation level might give some amount of information, while a high sensation level will not necessarily add much more information for understanding speech. For those with profound hearing loss, audibility might be accompanied with virtually no added 'effective audibility'.
The new NAL-NL1 fitting method provides insertion gain targets for 65 dB SPL inputs that are very similar to those given by NAL-R & NAL-RP. According to Dillon, et al. (1998), the main objective of developing NAL-NL1 was to determine the gain for several input levels that would result in maximal effective audibility. The one constraint, as with the other NAL methods, was that overall aided loudness perceptions for the whole, total aided speech signal had to be less than or equal to that for speech.
To calculate NAL-NL1 gain targets, gain calculations were performed for 52 people with various audiometric configurations, for input levels from 30 to 90 dB SPL, in 10 dB increments. Any calculation involving all these variables certainly involves a lot of 'number crunching,' and this was true for the development of NAL-NL1. For gently sloping, hearing loss audiograms, ranging from mild to severe in degree, the resultant insertion gain was found to be close to that provided by NAL-RP. Consistent with the other NALs, for most types of hearing loss, the mid frequencies of speech were found to be similar in loudness to the lower and higher adjacent speech frequencies. The end aim was thus achieved: equal loudness of all speech frequency bands, along with maximal speech intelligibility.
NAL-NL1 compared to DSL (and some other methods):
Most of the following discussion pertains to the differences between NAL-NL1 and the DSL fitting method. It should be noted that for any comparison with DSL, gain targets have to be converted to output targets, or vice versa. The DSL method normally plots its targets in terms of output, not gain. To DSL proponents, output is the sound that is actually delivered to the eardrum of the listener, while gain is merely a means to an end.
We will begin with a comparison of NAL-NL1 to other compression-based fitting methods from the viewpoint of NAL-NL1 proponents. Following that, a comparison between DSL and NAL-NL1 from the DSL proponents viewpoint will follow.
Byrne, Dillon, Ching, Katsch, & Keidser (1999) compared gain targets of NAL-NL1 to those for Fig6, IHAFF, and DSL. The results shown in Figures 3-7 illustrate their comparisons among gain targets for NAL-NL1, DSL, Fig6, and IHAFF, for five various audiometric configurations, using an input level of 65 dB SPL. In some of these figures, no NAL-NL1 prescription is provided at the very highest or lowest frequencies and the target does not span the entire frequency range; according to NAL-NL1 philosophy, for these particular hearing losses, these frequencies will not contribute towards 'effective audibility' with any amount of gain.
Consider a flat hearing loss of 60 dB (Figure 3).
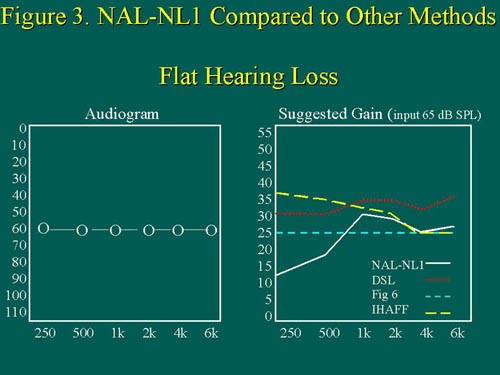
Figure 3. For a flat audiogram, IHAFF prescribes the most low-frequency gain, followed by DSL, then Fig6, and finally NAL-NL1. DSL also prescribes the most high-frequency gain. Figure from Byrne, Dillon, Ching, Katsch, & Keidser (1999). Adapted with permission.size=1>
It is evident that NAL-NL1 prescribes less gain than DSL across all frequencies, and the greatest difference in target gain is at the low frequencies. For a reverse slope hearing loss of 70 dB (Figure 4), NAL-NL1 specifies less low-frequency gain than NAL-NL1.
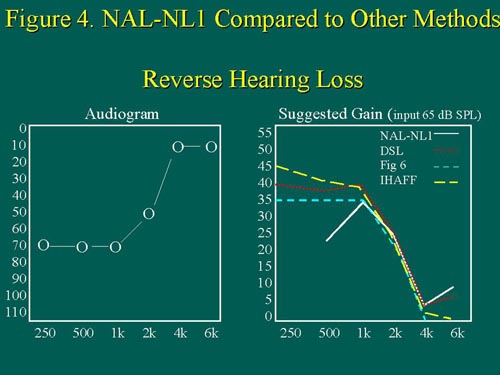
Figure 4. For a reverse audiogram, IHAFF prescribes the most low-frequency gain, followed by DSL, then Fig 6, and finally NAL-NL1. Note the 'missing' NAL-NL1 target below 500Hz; according to NAL-NL1, for this particular hearing loss, these frequencies will not contribute to 'effective audibility.' Figure from Byrne, et al (1999). Adapted with permission. size=1>
However, NAL-NL1 prescribes more high-frequency gain than DSL. This is consistent with the NAL emphasis on providing more of a flat insertion gain target, and thus, equalizing the loudness of the speech frequencies. For a gently sloping, moderate to moderately-severe hearing loss (Figure 5),
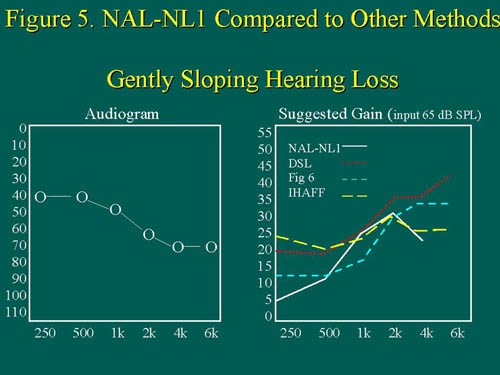
Figure 5. For a gently sloping audiogram, IHAFF prescribes the most low-frequency gain, followed by DSL, then Fig6, and finally NAL-NL1. Note the missing NAL-NL target for the high frequencies; again, according to NAL-NL1, for this particular hearing loss, these frequencies will not contribute to 'effective audibility.' Figure from Byrne, et al (1999). Adapted with permission. size=1>
NAL-NL1 again prescribes less low-frequency and high-frequency gain than DSL; prescribed mid-frequency gain is similar for the two fitting methods. For a precipitous, pronounced high-frequency hearing loss with normal low-frequency hearing up to 1kHz (Figure 6),
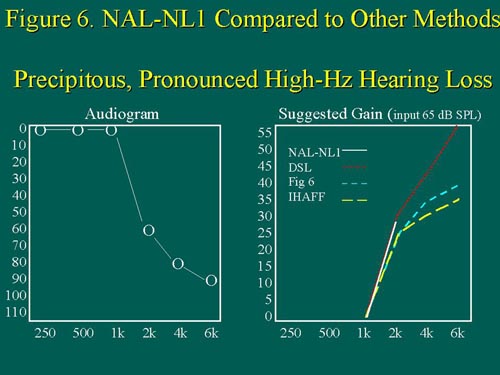
Figure 6. For a precipitous, high-frequency hearing loss, DSL prescribes by far the most high-frequency gain, followed by Fig6, and then IHAFF. Note again, the missing NAL-NL target for the high frequencies. Figure from Byrne, et al (1999). Adapted with permission. size=1>
NAL-NL1 and DSL prescribe very similar gain from 1 to 2kHz; the main difference between the two methods is that DSL continues to prescribe more and more high-frequency gain with increased high-frequency hearing loss, whereas NAL-NL1 does not ask for any gain whatsoever. Lastly, consider the steeply sloped hearing loss that drops to a pronounced high-frequency loss without the precipitous 'corner' (Figure 7).
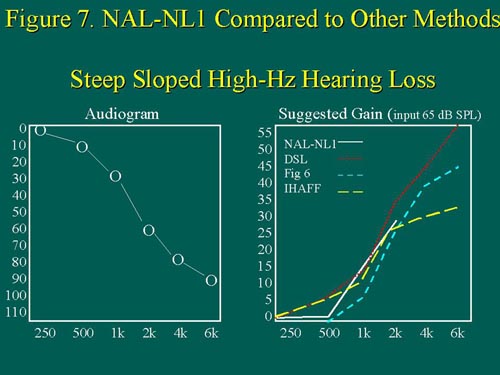
Figure 7. For a steeply sloped, high-frequency hearing loss, DSL again prescribes by far the most high-frequency gain, followed by Fig6, and then IHAFF. Note again, the missing NAL-NL target for the high frequencies. Figure from Byrne, et al (1999). Adapted with permission. size=1>
NAL-NL1 prescribes slightly less low-frequency gain, and similar mid-frequency gain compared to DSL. However, note that NAL-NL1 prescribes no high-frequency gain whatsoever. Now let's look at NAL-NL1 as it compares to other compression-based fitting methods besides DSL, such as Fig6 and IHAFF. For the flat, reverse, and gently sloping audiograms shown in Figures 3, 4, & 5, the IHAFF fitting method provides the most low-frequency gain, followed by DSL, then Fig6, and lastly, NAL-NL1. These results are in keeping with the NAL-NL1 point of view that, since other fitting methods attempt to normalize, rather than equalize, the loudness of adjacent speech frequencies, they prescribe relatively more low-frequency gain. For steeply sloping, high-frequency audiograms (Figures 6 & 7), DSL provides the most high-frequency gain of all the four fitting methods compared, while NAL-NL1 asks for the least amount of high-frequency gain.
To explain why this is so, Byrne, et al. (1999) reminds us that these high-frequency regions, where hearing loss is severe to profound in degree, do not contribute much to speech intelligibility. The same rationale would hold true for the reverse audiogram shown in Figure 4; for someone who has better hearing at some frequencies and much worse hearing at others, the frequency regions of poorest hearing will contribute the least towards speech intelligibility.
DSL Compared to NAL-NL1 from DSL's Point of View:
The fitting methods of NAL-NL1 and DSL were also compared by proponents of DSL (Scollie & Seewald, 1999). As an aside, it should be known that DSL displays hearing loss and aided targets on an 'SPL-o-gram,' which is routinely done by DSL. All decibels on this graph are shown in terms of SPL, thus allowing hearing loss and hearing aids to speak the same language. The SPL-o-gram shows SPL increasing as you 'go up,' and Hz increasing as you 'go to the right,' just like any graph normally does. In the SPL-o-gram, the hearing loss is literally the 'floor,' uncomfortable loudness levels are the 'ceiling,' and aided targets are in between. The SPL-o-gram, visible on DSL I/O software, as well as on various fitting software packages from hearing aid manufacturers, makes a lot of sense and clarifies explanations for counseling .
There is some disagreement among DSL and NAL-NL1 proponents about what 'normalizing' and 'equalizing' will accomplish in establishing targets for hearing aid gain & output.
According to Scollie (2000), DSL fitting software can be set up to either equalize or normalize loudness of adjacent speech frequencies. Most clinicians who use the software choose the option of equalizing loudness. Ironically, according to Scollie, if one chooses to 'normalize,' then the DSL targets look more similar to NAL-NL1 targets as low frequencies are not amplified as much as when the 'equalized' option is selected. The following target comparisons done by the DSL proponents were done with the equalized loudness settings.
For DSL/NAL-NL1 target comparisons, Scollie & Seewald (1999) changed prescribed NAL-NL1 gain into output, because on the previously mentioned SPL-o-gram, DSL normally prescribes amplification in terms of output. Results shown in Figures 8-10 illustrate their comparisons between prescribed outputs of DSL and NAL-NL1. In each figure, target real ear aided response (REAR) comparisons are shown for .5kHz and 4kHz, for varying degrees of flat, sloping, and steeply sloping hearing loss, and at inputs of 50 80, and 100 dB SPL. Unlike gain graphs which show compression as offering less and less gain with increased input levels, output graphs show increased output with increased input levels. Therefore, the top line or function on each of these figures shows the output for the most intense input level. It is important to note that in these figures, the effect of three independent variables on prescribed output are being shown: fitting method (DSL or NAL-NL1), degree of hearing loss, and input level. The simplest way to read and understand these graphs is to determine where the solid and dotted line functions are closest together and where they are furthest apart. Similarities between DSL and NAL-NL1 are shown whenever the lines are close together; differences are shown whenever the lines are furthest apart.
For flat audiograms with a 0 dB/octave slope (Figure 8), the differences between prescribed output by DSL versus NAL-NL1 are more evident at .5kHz than they are at 4kHz, with DSL asking for more low-frequency output than NAL-NL1. The prescription differences are most pronounced for soft (50 dB SPL) input levels and furthermore, the differences also increase with increased degree of flat hearing loss.
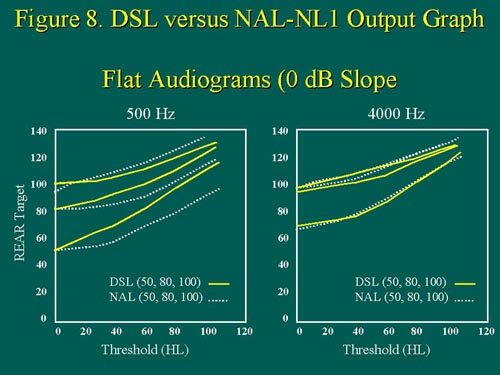
Figure 8. For flat hearing losses, REAR output targets are shown for the specific audiometric frequencies of 500Hz and 4000Hz, for both DSL and NAL-NL1. Note that as the thresholds at 500Hz increase, the solid and dotted lines separate, whereas the same does not hold true for 4000Hz thresholds. For flat hearing losses, the target discrepancies between DSL and NAL-NL1 are more apparent at 500Hz than at 4000Hz. Figure from Scollie & Seewald (1999). Adapted with permission. size=1>
For sloping audiograms with a 10 dB/octave slope (Figure 9), the differences between the two fitting methods are again, more evident at .5kHz than at 4kHz, with DSL again asking for more output than NAL-NL1.
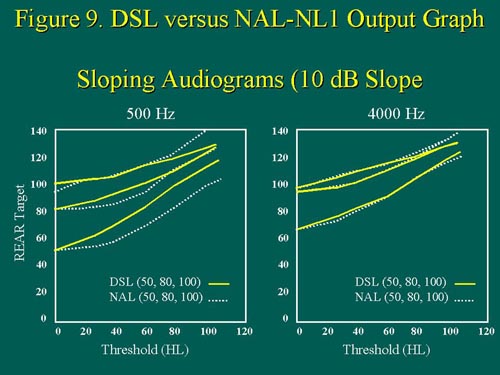
Figure 9. For gently sloping hearing losses, REAR output targets are shown for the specific audiometric frequencies of 500Hz and 4000Hz, for both DSL and NAL-NL1. Note again that as the thresholds at 500Hz increase, the solid and dotted lines separate, whereas the same does not hold true for 4000Hz thresholds. For gently sloping hearing losses, the target discrepancies between DSL and NAL-NL1 are most apparent at 500Hz, for soft inputs only. Figure from Scollie & Seewald (1999). Adapted with permission. size=1>
The prescription differences are again, most pronounced at soft input levels, and also, the differences increase with increased degree of hearing loss. For steeply sloping audiograms with a 20 dB/octave slope (Figure 10), DSL prescribes more low and high-frequency output than NAL-N L1, but note that the discrepancy is once again more pronounced at .5kHz than it is at 4kHz, and that it is most evident for soft input levels.
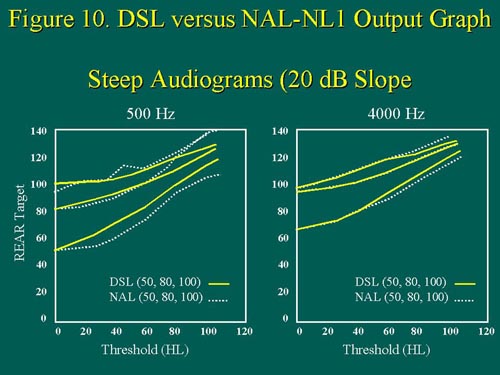
Figure 10. For steeply sloping hearing losses, REAR output targets are shown for the specific audiometric frequencies of 500Hz and 4000Hz, for both DSL and NAL-NL1. Note, as thresholds at 500Hz increase, the solid and dotted lines separate, whereas the same does not hold true for 4000Hz thresholds. For steeply sloping hearing losses the target discrepancies are again most apparent at 500Hz, and at soft inputs only. Figure from Scollie & Seewald (1999). Adapted with permission.size=1>
Lastly, the DSL proponents note that at high input levels, NAL-NL1 appears to prescribe more output than DSL!
Summary
In general, findings from both the DSL and NAL-NL1 camps show that for flat and gently sloping audiometric configurations, DSL does indeed prescribe more low-frequency gain/output than NAL-NL1. Furthermore, both fitting philosophies show that for steeply sloping, pronounced degrees of high-frequency hearing loss, DSL also prescribes more gain/output than NAL-NL1. However, it is unclear from the available data as to how the DSL and NAL-NL1 targets would compare if the setting for 'normalized' instead of 'equalized' loudness across frequencies had been selected on the DSL fitting software (see above discussion on DSL software).
The two camps disagree, however, when it comes to the degree of difference in prescribed high-frequency gain/output between the two fitting methods. For flat and sloping hearing losses, NAL-NL1 proponents show that DSL prescribes much more high-frequency gain. On the other hand, DSL proponents show that for these same hearing losses, the amount of prescribed output from each of the two fitting methods is quite similar. The DSL camp also says that although DSL does prescribe more output for steeply sloped, high-frequency hearing loss, the difference is not as great as the NAL proponents would imply.
Which Method is Best?:
Once again, this question has actually been separately examined by proponents of both NAL-NL1 and DSL. From the NAL camp, Ching, Newell, & Wigney (1997) examined whether the NAL-RP or DSL fitting method would most closely predict the subjective preferred hearing aid gain levels in children with severe-to-profound hearing loss. Recall, NAL-RP is quite similar to NAL-NL1 for moderate input levels and NAL-NL1 had not yet been developed in 1997. These authors found that the children's preferred gain was closer to the gain targets set by NAL-RP than those set by DSL. They admit, however, that since the children's hearing aids were originally fit according to NAL-RP prescriptions, the children may have been accustomed to the gain prescribed by NAL-RP.
The DSL camp, Scollie, Seewald, Moodie, & Dekok (2000), however, performed a study of children who had originally been fit with DSL. The average hearing loss of their subjects was moderate to severe. These authors found that both NAL-NL1 and DSL underestimated the children's preferred gain! Their also found that DSL was closer to the children's preferred gain. Acclimatization appears to have had some role in the findings of each of these studies.
Conclusion:
It is hoped that this discussion has increased understanding of the philosophy, history and development behind the new NAL-NL1 fitting protocol, as well as how NAL-NL1 targets compare to those of other methods, especially DSL.
Based on the past record of NAL-R, the new NAL-NL1 promises to be an extremely popular and widely accepted fitting method for compression hearing aids. As mentioned earlier, there is a psychological appeal (right, wrong, or indifferent) to being able to actually 'hit' gain targets, and this is more easily accomplished with NAL-NL1 than with DSL.
But now we need to face these issues with the facts we have learned here. There is a widely held, but erroneous assumption that DSL is always 'hungry' for high-frequency gain. The truth of the matter is that for most types of hearing loss DSL prescribes more low-frequency gain than NAL-NL1. Only for high-frequency hearing loss does DSL prescribe more high-frequency gain than NAL-NL1.
Lastly, consider that the new NAL-NL1 software (Dillon, Byrne, Brewer, Katsch, Ching, & Keidser, 1998) incorporates the SPL-o-gram, much as it is found on DSL software (Seewald, Cornelisse, Ramji, Sinclair, Moodie, & Jamieson, 1997). For DSL, which typically advocates this type of display, imitation is the finest form of flattery.
References
Berger KW, Hagberg EN, & Rane RL. (1980). Determining hearing aid gain. Hearing Instruments, 30(4), 26-44.
Byrne D. & Dillon H. (1986). The national acoustics laboratories' (NAL) newprocedure for selecting gain and frequency response of a hearing aid. Ear &Hearing, 7(4), 257-265.
Byrne D, Parkinson A. & Newall P. (1990). Hearing aid gain and frequency responserequirements for the severely/profoundly hearing impaired. Ear & Hearing, 11, 40-49.
Byrne D, & Tonnison W. (1976). Selecting the gain in hearing aids for persons withsensorineural hearing impairments. Scandinavian Audiology, 5, 51-59.
Ching T, Newall P, & Wigney D. (1997). Comparison of severely and profoundly hearing-impaired children's preferences with the NAL-RP and the DSL 3.0prescriptions. Scandinavian Audiology, 26:219-222.
Cox RM. (1995). The Using loudness data for hearing aid selection: The IHAFF approach. The Hearing Journal, 48(2), 10-44.
Dillon H, Byrne D, Brewer S, Katsch R, Ching T, & Keidser G. (1998). NAL NonlinearVersion 1.01 User Manual. Chatswood, Australia: National Acoustics Laboratories.
Dillon H, Katsch R, Byrne D, Ching T, Keidser G, & Brewer S. (1998). The NAL-NL1prescription procedure for non-linear hearing aids. National Acoustics Laboratories Research and Development, Annual Report 1997/98 (pp. 4-7). Sydney: National Acoustics Laboratories.
Killion MC, & Fikret-Pasa S. (1993). The 3 types of sensorineural hearing loss: Loudness and Intelligibility considerations. The Hearing Journal, 46(11), 1-4.
Lybarger SF. (1944). U.S. Patent Application SN 543, 278.
Lybarger SF. (1963). Simplified fitting system for hearing aids. Canonsburg, PA: Radio Ear Corp.
McCandless GA. & Lyregaard PE. (1983). Prescription of gain and output (POGO) for hearing aids. Hearing Instruments, 34(1), 16-21.
Scollie S, Seewald R, Moodie S, & DeKok K. (2000). Preferred listening levels of children who use hearing aids: Comparison to prescriptive targets. Journal of the American Academy of Audiology, 11(4), 230-238.
Scollie S. (2000) Personal communication.
Seewald RC. (1992). The desired sensation level method for fitting children: Version 3.0. The Hearing Journal, 45(4), 36-41.
Seewald RC, Cornelisse LE, Ramji KV, Sinclair ST, Moodie KS, Jamieson DG. (1997). DSL 4.1 for Windows. London, ON: Hearing Health Care Research Unit, University of Western Ontario.
This article originally appeared on www.audiologyjournal.com. Audiology Online (www.audiologyonline.com) has acquired the Audiology Journal. This paper has been re-edited and updated and appears here as a courtesy to our readers for educational and informational purposes. We are grateful to the author and to Audiology Journal for allowing us (Audiology Online) to re-publish this updated version of this article here. ---Douglas L. Beck Au.D. Editor-In-Chief, Audiology Online.
