
From the Desk of Gus Mueller
![]() Talking about new hearing aid technology is always fun, and often controversial—which of course adds to the fun. Some of you might be old enough to remember the lively discussions of WDRC versus linear, the true high frequency benefits of a Libby Horn, or whether BILL processing really improves speech intelligibility in background noise. As time goes on, technology changes, and the discussions follow naturally.
Talking about new hearing aid technology is always fun, and often controversial—which of course adds to the fun. Some of you might be old enough to remember the lively discussions of WDRC versus linear, the true high frequency benefits of a Libby Horn, or whether BILL processing really improves speech intelligibility in background noise. As time goes on, technology changes, and the discussions follow naturally.
A hearing aid processing algorithm which has generated considerable chatter in recent years is frequency lowering. There are at least three strategies currently available, and more on the way. We’re doing a trilogy of articles on frequency lowering here at 20Q. You saw the first one last month—an excellent review of how these systems work, and some insights into candidacy and real-world function, written by Josh Alexander, Ph.D. of Purdue University. We’re back this month with more of a focus on the clinical verification of these instruments. It’s pretty special, as we have with us one of the pioneering researchers in the area of frequency lowering to share her work and clinical recommendations.

Gus Mueller
Susan Scollie, Ph.D., is an associate professor at Western University, and a member of the National Centre for Audiology in Canada. As many of you know, Dr. Scollie, working in the UWO Child Amplification Lab, played a huge role in the development of the DSL v5.0. In addition to her research, she is active in the UWO audiology graduate training program, one of only three English training programs in Canada for Audiology, and Canada’s largest.
Her many publications and presentations in the area of pediatric amplification clearly identify her as an international expert in this area. You may have noticed her lab’s recent papers, which include a new speech test signal in Brazilian Portuguese (look for soon-to-be Dr. Luciana Garolla), a series of articles on the UWO PedAMP outcome measurement protocol (look for Drs. Marlene Bagatto & Sheila Moodie), several new studies of children’s acclimatization patterns after being fitted with frequency compression (look for Dr. Danielle Glista), and some early results with the DSL v5 “noise” prescription (look for Dr. Jeff Crukley).
Dr. Scollie hails from the chilly Northwestern Ontario part of Canada, and the word on the street is that she not only is an avid skier, but knows how to cut down a tree. As a native North Dakotan, I personally developed a fondness for Susan many years ago when I learned that her favorite movie is Fargo!
And speaking of fondness, I’m certain you will enjoy this excellent 20Q article from Dr. Scollie. She takes us into the clinic and goes through many of the selection and verification decisions that we all are faced with when fitting this intriguing technology.
Gus Mueller, Ph.D.
Contributing Editor
May 2013
To browse the complete collection of 20Q with Gus Mueller articles, please visit www.audiologyonline.com/20Q
Editor’s Note: If you just happened to miss it, check out Josh Alexander’s April 20Q on this same topic. And there’s more—Stay tuned for a “Bonus 20Q” in which Josh, Susan and Gus will have a discussion on all the important clinical issues on frequency lowering that somehow never made it into either of the two articles.
20Q: The Ins and Outs of Frequency Lowering Amplification

Susan Scollie
1. My main interest is the clinical applications of frequency lowering, but before we get started, could you give me a quick review of how this technology works?
I'll give it a shot. Like most hearing aid technologies, it's not something that really can be explained quickly. When you get a chance, you might want to check out some of the articles from our centre. For example, Danielle Glista has published clinical outcomes on frequency compression (Glista et al., 2009), on acclimatization to frequency lowering (Glista, Scollie, & Sulkers, 2012; Glista, Easwar, Purcell, & Scollie, 2012) and a suggested fitting protocol (Glista & Scollie, 2009; Scollie & Glista, 2011), and Vijay Parsa has recently shared some new data on sound quality (Parsa, Scollie, Glista, & Seelisch, 2013). I also enjoyed reading the review by Josh Alexander (2013) here at 20Q last month.
But, since you asked, here is a nutshell description of the technology, which goes along with Figure 1. There basically are three types of frequency lowering signal processors currently available. I’ll go in order of their introduction to market. First, we have frequency transposition (the AudibilityExtender from Widex), which linearly transposes a peak of high frequency energy down in frequency by either one or two octaves, and mixes it with the non-transposed lower band. Next, we have frequency compression (SoundRecover from Phonak and Unitron, and generic frequency compression from Siemens), which is a lot like WDRC but in the frequency domain. Above a cutoff frequency, the input range is compressed into a narrower output range according to a compression ratio. This “squeezes” the upper band into a narrower region. The compression is done on a nonlinear scale, so the uppermost frequencies receive the most lowering effect within the compressed band. Finally, we have frequency translation, sometimes referred to as spectral envelope warping (Spectral iQ from Starkey). Frequency translation is an adaptive algorithm in the sense that it only provides frequency lowering when a high-frequency-emphasis input is detected. This decision happens rapidly (at the speed of phonemes), with the intent that a sound like “sa” would cause the processor to activate for “s” and deactivate for “a”. Interestingly, this processor makes a copy of the “s”, and presents it at the lower frequency while leaving the original “s” energy in its original location. The strength of these processors is clinician-adjustable, from more frequency lowering to less frequency lowering. For some systems, the gain of the lowered band may also be adjusted. They all provide a lowering of frequency, but do so in unique ways. This is why the industry has started to embrace the umbrella term “frequency lowering” when discussing this family of processors as a group.
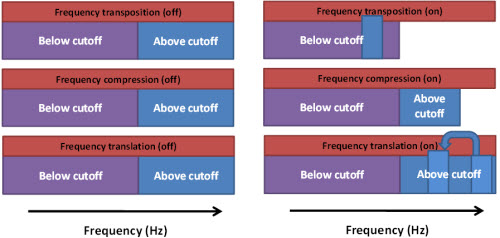
Figure 1. Three frequency lowering signal processors and their effect on the upper frequency band when activated. See answer to Question 1 for descriptions of each processor.
2. Great. That really helps. So regarding my day-to-day practice, I guess I'd like to start out by talking about how I know who is a candidate? Can I just look at the audiogram?
The audiogram alone doesn’t allow a full determination of candidacy, although we did find that those with greater high frequency hearing losses are more likely to be candidates (Glista et al., 2009). In addition to pure tone audiometric information, we like to verify whether we can amplify across a broad bandwidth of speech just by using gain and WDRC processing. We base our candidacy decision on this: if verification tells us that we are missing audibility in a certain high frequency region despite our best efforts, then the person is a candidate. An example of a candidate fitting is shown in Figure 2.
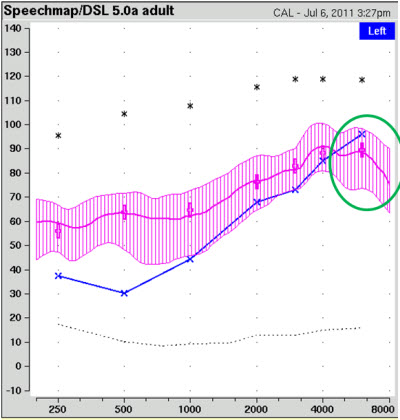
Figure 2. Example of verifying the audible bandwidth of speech in ear canal SPL. The shaded pink area is the aided speech spectrum (middle line) surrounded by the amplitude range of speech. The blue “X’s” represent the patient’s thresholds (converted to ear canal SPL). The area in the green circle has limited audibility, indicating that the user might be a candidate for frequency lowering signal processing.
3. I understand your example, but I then have to ask—would you ever fit frequency lowering to someone with a flat hearing loss?
I would consider it, but only after I’d verified their hearing aid fitting and fine tuned to maximize high frequency audibility for speech. I’ll give you an example. For some losses, current hearing aid bandwidth and output limitations may impact our ability to provide good audibility of speech energy above 4000 Hz, even with a well-fitted device . . . picture the fitting shown in Figure 2, but with more hearing loss in the low frequencies: you’d still have limited audibility above 4000 Hz. That’s going to hold back the patient from having access to certain phonemes, and I would consider the use of a frequency lowering scheme.
4. But do we really need to hear speech cues above 4000 Hz? We do just fine on our phones, and they only deliver frequencies to just above 3000 Hz, right?
Well, I didn’t realize you’d been living under a rock, or at least a small stone. Maybe you don’t fit kids with hearing aids . . . but a big issue in pediatric hearing aid fitting is access: we want to make sure that children can hear all of the phonemes in speech and this leads us to try to maximize audible bandwidth. Studies by Stelmachowicz’s and Moeller’s groups at Boystown and Andrea Pittman’s lab in Arizona have convinced me that children need access to speech above 4000 Hz (Moeller et al., 2007; Pittman, 2008; Stelmachowicz, Hoover, Pittman, & Moeller, 2004). Fricatives (e.g., s, sh, f) are more difficult to hear, understand, learn, and say when a child can only hear up to 4000 Hz but not above. To illustrate this issue, I’ve graphed an example of conversational speech against the spectrum of a clearly articulated “sh” and “s” spoken by a female talker, shown in Figure 3. Observe that the “sh” is around 4000 Hz, with some components above, and the “s” clearly lies above 4000 Hz, and would not be well amplified by the fitting that I showed in Figure 2.
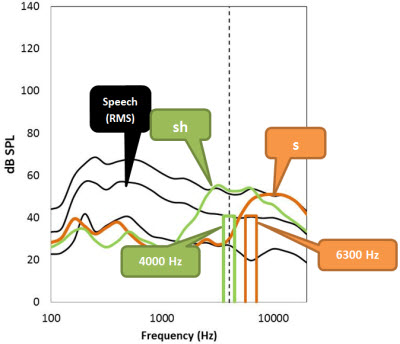
Figure 3. Comparison of the spectrum of a female’s clearly articulated “s”and “sh” versus the spectrum of speech at an overall level of 65 dB SPL. The upper, middle, and lower lines correspond to the peak (99th percentile), average, and valley (30th percentile) of conversational speech. The vertical dashed line marks 4000 Hz for reference. The plotted bars at 4000 and 6300 Hz are examples of 1/3 octave bands of speech.
5. Okay, okay. I get it for children. But you’re right, I mostly fit adult patients. Some of my colleagues fit frequency lowering to almost 50% of their adult patients. You really didn’t answer my question regarding adults who already have developed speech and language.
Well, that’s interesting. Some things don’t change across ages: hearing aid bandwidth has some limitations as we discussed earlier, and certain phonemes of speech exist only at the very high frequencies. I’d expect speech of adult daughters and any grandchildren to have significant high frequency content, for example, and other sounds like music, the doorbell, and the turn signal clicker in the car are helpful to hear.
6. So you’ve been working with frequency compression as a way to compensate for the low bandwidth of hearing aids? I thought that the bandwidth problem has been solved, and if so, maybe we don’t need frequency lowering?
First, let me say that we started working with frequency compression when it was a prototype in the early 2000’s. At that time, I was very concerned about the bandwidth problem, pretty much regardless of hearing level. Hearing aids at the time were quite limited above 4000 Hz, because of signal processing limitations, feedback, and receiver types. Today, we have broadband digital signal processing (DSP), and much better feedback control. Additionally, we also are now able to pair BTEs with receivers in the ear canal, overcoming the roll-off caused by earmold tubing. All of these things help us to have broader bandwidth of audible speech in 2013 than we did in 2003, which is great.
So with these improvements, does this mean we don’t need frequency lowering? Not exactly. Let’s take an extreme “low candidacy” case of an adult with a mild loss—we’ll say the loss is only 40-50 dB in the high frequencies. The hearing loss is post-lingually acquired so she will already know that the phoneme “s” exists and how it’s used in words and for grammatical markers of plurality and possessiveness. Therefore, she doesn’t need a high sensation level of speech like she would if she was a developing child. This is why we prescribe a lower target for adults than for children in DSL v5 (Scollie, 2007). Fitted with an extended bandwidth device, either a custom instrument or a mini-BTE that uses a receiver in the ear canal, she may have a clearly audible “s” without any form of frequency lowering. Some recent studies of adults with hearing loss tell us that access to high frequency cues in the 3500-9000 Hz region are either important or carry no negative effects for many hearing aid fittings and may be preferred by listeners with this type of hearing loss (e.g., Hornsby, Johnson, & Picou, 2011; Ricketts, Dittberner, & Johnson, 2008). Mind you, this assumes that the fitting provides on-ear extended bandwidth.
7. Why do you say “assumes”? If the hearing aid’s DSP goes to 12,000 Hz, doesn’t that mean that the hearing aid has extended bandwidth?
Not always. It means that the digital processing in the hearing aid has data up to and including 12,000 Hz. But does that mean that the fitting has audible speech above 4000 Hz? Notice that I said “on-ear” extended bandwidth. First, recent fit-to-target studies still show limited ability to meet target gains at 4000 Hz and above (Aazh, Moore, & Prasher, 2012; Alworth, Plyler, Reber, & Johnstone, 2010). From a practical standpoint, there are two things that hold us back in fitting to prescribed levels of audibility in the high frequencies. One is fitting to the default prescription without verification of aided speech in the ear: in many cases, we know that the manufacturer’s default strategies often program the aid with less gain than a generic prescription would recommend (Aazh et al., 2012). Another factor that can reduce the amount of high frequency gain is the use of a slim tube. Although they are cosmetically appealing, they also act as a 4000 Hz low pass filter. It just doesn’t matter if the hearing aid DSP goes to 10,000 or 12,000 Hz: those high frequencies are not going to make it through a non-belled, narrow-bore slim tube. In both of those examples, we have a real-ear narrowband fitting from a device with broadband DSP.
8. Thanks for explaining that. Should we be using frequency lowering to overcome these types of problems?
Maybe. Let’s take a different fitting case for an adult with a moderate hearing loss. For a variety of valid reasons (cost, cosmetics, cerumen management, comfort), she’s been fitted with a mini-BTE slim-tube device, and the device has been verified and fine-tuned to optimize the fitting to target. Audibility is great to 4000 Hz but not above. Her clinician wishes to provide her with the speech cues that would have been available with an extended bandwidth fitting. The clinician could elect to enable a frequency lowering scheme with a mild setting that prevents frequency lowering from being applied below about 3500 Hz. In our work with adult patients, we have found that mild frequency compression settings have only slight effects on sound quality (Parsa et al., 2013). I would not expect any major benefit or harm with this type of fitting: it is really more of a cue-delivery philosophy. The alternative arguments are that we shouldn’t use frequency lowering as a bandage placed over preventable bandwidth limitations, or that we shouldn’t provide frequency lowering unless utterly necessary because it is an additional distortion to the signal. These arguments allow us to challenge our understanding of the impacts of these processors because they ask us to consider both the advantages and disadvantages of enabling a processor. At mild settings, no serious adverse consequences are expected, and small benefits in specific speech sound detection are possible.
9. I think I see your point: we should take the strength of the processor into account when thinking about frequency lowering. So then logically, patients with severe hearing losses need to use stronger settings?
Yes, if they are fitted with frequency lowering hearing aids, anyone with a severe loss will likely use a stronger setting than someone with a milder loss. The bandwidth studies that we talked about a few minutes ago tell us that adult patients with steeply sloping losses don’t receive the same amount of benefit from extension of audibility into the 3500 – 9000 Hz region (e.g., Hornsby et al., 2011). Frequency lowering may be another way to access these cues if getting them from a bandwidth strategy won’t work. The default settings certainly start out with stronger frequency compression settings for these patients, and fitting protocols for use with frequency lowering (Alexander, 2013; Glista & Scollie, 2009) lead to stronger settings for more severe losses. We’ve seen cases of significant benefits for adults and children with losses that slope to the profound level in the high frequencies, and these patients have used strong settings of frequency compression (Glista et al., 2009; Glista, Scollie, & Sulkers, 2012; Glista, Easwar, Purcell, & Scollie, 2012).
10. In one of your earlier answers, it sounded like you are not fond of manufacturers’ default settings? True?
At that point I was referring to the default settings for gain and output, which in general tends to be quite conservative in the highs. But we also can talk about the default settings for frequency lowering, which is what I think you’re asking about now. Although our lab helped to develop Phonak’s pediatric default setting, I can’t recommend using them without verifying their performance. Remembering that all of these technologies are still very young, and that there are still debates on whether and how to use them, I believe we are not at a point of being certain about any individualized setting until we’ve verified it carefully and followed up to make sure that the fitting outcome was a success. That said, the default settings are necessary – every processor has to turn on somewhere and we can expect them to improve as more evidence is developed in careful studies. In our first effort at a pediatric default, we had a specific rule for determining cutoff frequency. In the second version, we had more data and were able to create different rules for steeply sloping audiograms, and establish a normal-to-mild hearing loss range in which the processor is disabled. I hope that this second version was an improvement. I’d still verify every fitting though.
11. You mention “verification.” Can you maybe describe your verification protocol?
I’d be happy to. One of my favorite topics! First, we turn the frequency lowering to “max,” enable it and say, “She sells seashells by the seashore.” If they fall off the chair, we back it off a little. Just kidding! We start by hooking up the hearing aid for programming, with the patient seated in front of our real ear measurement system. We fine tune a standard fitting, checking for a close fit to the DSL v5 targets for soft, average, loud, and maximum output. Once we have our desired fitting, we take a closer look at the input for the 65 dB SPL real-speech signal. If we see poor audibility in the upper frequency range, we enable the frequency lowering processor and search for the weakest possible setting that provides improved audibility for high frequency sounds. We also check that we avoid frequency overlap between the phonemes “s” and “sh.” This protocol is described in detail elsewhere (Glista & Scollie, 2009; Scollie & Glista, 2011).
12. Sounds reasonable. What test signals do you recommend for this protocol?
Well, there are a few choices. If you haven’t conducted a lot of probe-microphone speech mapping, or if you haven’t specifically conducted verification for frequency lowering, let me first say that you can’t simply use the standard long-term average speech spectrum (LTASS) of your probe-mic equipment. The problem is that the lowered signals will “blend in” with the other signals that are being delivered in the destination area of the lowered speech signals. For this reason, we need special signals. One example is the Audioscan Verifit, which has a filtered speech signal that Danielle Glista and I described in our 2009 article. With that signal we have used the 4000 and 6300 Hz speech bands to probe the fitting for high frequency audibility and to check whether or not the 4000 and 6300 Hz bands overlap. We aim to make them both audible and also to avoid overlapping the two. I like using these signals because they are calibrated and highly repeatable.
13. I conduct speech mapping with my probe system, but this is all new to me. Can you explain more about how you use them? And maybe just how time consuming this testing would be?
Sure. Let’s look through the example that I have for you in Figure 4. Since you’re interested in time commitment, I’ll tell you that I started out at 11:25 AM, having just finished the basic adjustment to the gain with frequency lowering off (top left panel). I then tested the 4000 Hz speech band: it’s audible even without frequency lowering, so I knew that I didn’t need any lowering at 4000 Hz. Then I tested with the 6300 Hz speech band: it’s not audible (top right). So, I enabled frequency lowering. The 6300 Hz band was audible at the default setting, but I also tested a few weaker settings to see if I could find the weakest possible one that would still give me audibility. I found one I was happy with (bottom left panel) and ran final for both frequencies at this setting. I also did a listening check using Ling-6 sounds to make sure “s” and “sh” could be differentiated. I was finished by 11:29 AM. Mind you, this is a pretty straightforward case, and I’m quite familiar with the software and the operation of the probe-mic equipment—but so are most clinicians. Sometimes all we can do is make the 4000 Hz band audible, but not 6300 Hz, and then we need to remember that one is better than none, and also that real fricatives may have more audibility than these signals show.
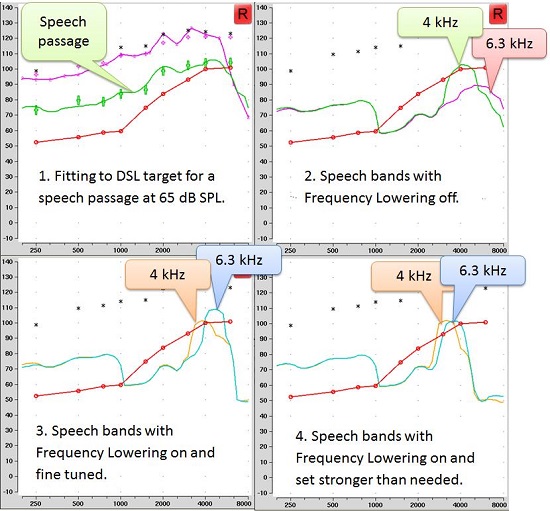
Figure 4. Steps in fitting a hearing aid with frequency lowering using the Audioscan Verifit.
14. Well obviously, time is not an issue. But I need a little more explanation regarding what you mean by the difference between test signals and real speech?
I’ll try, and I’ll give you an example. With the Verifit test signals, the speech bands are measures at the root-mean-square (RMS) level of speech, and are designed as only 1/3 of an octave in width. In contrast, fricatives may be higher in level and are typically wider in frequency. So, if you have limited audibility for the speech bands, you can expect to have more audibility for real productions of “s” and “sh”. Recall that we sort of talked about this before, which is what led to the illustration I showed you in Figure 3, which is unaided speech. The aided version of these same signals will look as shown in Figure 5. We see a similar picture from both tests, but the “s” is wider in frequency, and a little higher in level. In this case what we are doing is delivering the “s” and “sh” by live voice. Most importantly, we have the hearing aid set the same as it was for the results in Figure 4. Note that the signals are now considerably more audible than when the Verifit test signals were used. We also see this result when we use calibrated lab equipment to extract the “s” and “sh” from aided speech.
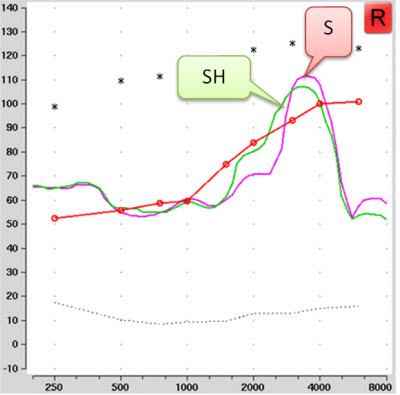
Figure 5. Aided "sh" and "s" as recorded through a hearing aid using live voice as the test signal. The hearing aid fitting is the same as shown in Figure 4.
15. I see. I had forgotten how broad a fricative band is. It seems that the test signal could determine how I adjust the hearing aid. What test signal should I use?
Well, it depends a bit on the probe-microphone system you use, because there are no industry-wide test signals for this type of verification yet. In the figure above, we see the Verifit test signal. With most systems, you can perform a rough test of “s” and “sh” by turning off the test signal and using your own speech . . . this is what I did for Figure 5. The main problems with the live speech option are that it’s an uncalibrated test, and that the frequency of “s” varies a lot with the gender of the talker: about 6000 Hz for men and 9000 Hz for women. For these reasons, we regard the live “s” and “sh” as more of a descriptive measurement.
16. That makes sense. Is there any way to have a calibrated version of these signals?
Some systems such as the Interacoustics Affinity offer an on-screen VU meter, which you can use to present the signals at the same level across tests. The GN Otometrics Aurical PMM and HIT also offer built-in Ling-6 sounds for use as test signals within the “Freestyle” tab. An example of that is shown in Figure 6. In this fitting, we see an example in which both the “s” and “sh” are clearly audible, and the fitting is generally similar to the results shown in Figure 5. That said, I’d love to see all systems giving us the same test signal options so that it is easier to compare across equipment and clinics.
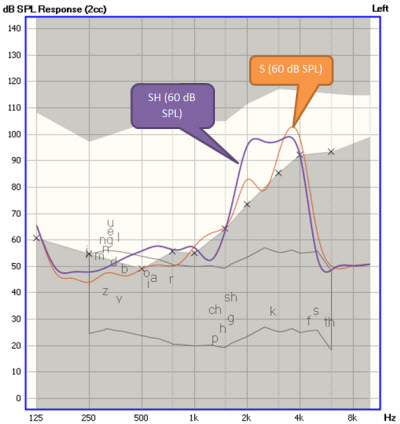
Figure 6. Sample verification screen from the GN Otometrics FreeFit, using Ling6 sounds "sh" and "s" to test the hearing aid fitting described in Figure 5. The “x” symbols mark the listener’s thresholds, converted to SPL in the 2cc coupler. The blue and orange spectra show aided “sh” and “s”, respectively. Frequency compression has been enabled and fine tuned.
17. Interesting – it seems like we are moving toward phonemic verification. What should I look for? I’m not sure I really know what is a “good” aided “s” or “sh”?
Good question—This is a topic we are currently working on. Based on fittings completed for our clinical trials on frequency compression, we’ve learned to avoid overlapping “s” and “sh”. If we provide too much frequency compression, the “s” gets lowered so much that it overlaps with “sh”. You can see this on a verification screen, hear it with a careful listening check, and the patient may notice this effect as slurred speech. Basically, the solution is to re-adjust to a weaker setting. Even a few hundred Hertz of separation may be enough, and we are currently working on some studies to measure the minimum amount of separation required. This is why we recommend choosing the weakest possible setting that gives audibility for the 6000-9000 Hz region of speech, but maximizes the separation of “s” and “sh". Josh Alexander’s calculation tool (2013), and phonemic verification measures can both assist us in finding such a setting. I’d rather rely on these objective tools than rely on the person’s immediate response to the frequency-lowered hearing aid sound.
Clinicians are often interested in the acclimatization effect for frequency lowering. As you maybe know, much of our work has been with older children. We recently saw that some children demonstrated a significant acclimatization pattern following the fitting of frequency compression, although this was not observed in all of the participants (Glista, Scollie, & Sulkers, 2012). Several showed a significant increase in discrimination of “s” and “sh” after six to eight weeks of use. To me, this may mean that a listener’s reaction to a new processor at the time of fitting may change after they wear it for a few weeks. If I fine tune only in response to their initial reaction, I might tune away any possibility that they would get the benefit in time. Obviously, the initial fitting needs to be physically and acoustically comfortable, but can also offer some new audibility that the wearer agrees to take home. I believe that this is a conversation that we can have with our patients, just as we do with increases in audibility from frequency shaping and wide dynamic range compression. We can find a setting that gives “more” but is also comfortable and acceptable.
18. Do you always put frequency lowering in the primary program, or do you sometimes put it in a separate program?
Our protocols are typically to put it in the primary program, which is usually designed for listening to speech in quiet. We’ve had many children in our studies and in our clinic who have been fitted this way and use it with their hearing aids and with their FM systems at school. Benefits for speech in noise are harder to find in the literature – most studies I have seen show little benefit or harm at clinically fitted settings, so I have no recommendation to enable or disable it in that sort of program.
19. Are there any special situations I should be thinking about?
The most interesting discussions seem to occur about fitting frequency lowering for music. We know that some music genres are more affected than others when frequency compression is used (Parsa et al., 2013). In a recent study from South Africa, more listeners rated music quality highly when fitted with frequency compression enabled, on a very detailed questionnaire of music perception factors (Uys, Pottas, Vinck, & van Dijk, 2013). This study’s sample included many adults with significant prior musical training and experience, and is an interesting read for anyone tackling a hearing aid fitting for a musician with hearing loss. Their results agree with the direct experiences I have had with a few highly musical patients, for whom the additional audibility of either the lyrics or certain instruments was appreciated. I’ve also heard reports from some clinicians of performing musicians who have provided them with a dedicated music program with different settings if needed. It can be a highly individualized situation, especially given the wide range of listener needs for satisfaction with aided music.
20. Are there any outcome measures that I could do to see whether my patient is benefitting from frequency lowering? I’m interested in knowing the whole story from my fittings.
Yes, there are. We’ve recently published two of the tests from our lab’s battery on a CD. We have a calibrated version of the Ling-6 sounds for measured aided detection thresholds in dB HL (Scollie et al., 2012). The other test is called the UWO Plurals Test, which asks the listener to pick between the singular and plural forms of nouns (Glista & Scollie, 2012). An example is “ant” versus “ants." This test is highly sensitive to benefit from frequency compression (Glista et al., 2009; Glista, Scollie, & Sulkers, 2012; Wolfe et al., 2010, 2011), but cannot tell us about more general speech recognition tasks such as consonant confusion or sentence recognition. And you asked about the “whole story?” Let me say that when we have conducted double-blinded measures of preference, it was interesting to see that people who showed benefit in the clinical testing were also the ones who were more likely to prefer frequency compression to be activated in their hearing aids for daily use (Glista et al., 2009; Glista & Scollie, 2012). That may not be the “whole story” but it’s a real world outcome that suggests we are going in the right direction.
References
Aazh, H., Moore, B., & Prasher, D. (2012). The accuracy of matching target insertion gains with open-fit hearing aids. American Journal of Audiology, 21(2), 175-180.
Alexander, J. (2013, April). 20Q: The Highs and lows of frequency lowering amplification. AudiologyOnline, Article #11772. Retrieved from: https://www.audiologyonline.com/
Alworth, L., Plyler, P., Reber, M., & Johnstone, P. (2010). The effects of receiver placement on probe microphone, performance, and subjective measures with open canal hearing instruments. Journal of the American Academy of Audiology, 21(4), 249-266.
Glista, D., & Scollie, S. (2009, November 9). Modified verification approaches for frequency lowering devices. AudiologyOnline, Article #14811. Retrieved from: https://www.audiologyonline.com/
Glista, D., & Scollie, S. (2012). Development and evaluation of an English language measure of detection of word-final plurality markers: The University of Western Ontario Plurals Test. American Journal of Audiology, 21, 76-81.
Glista, D., Easwar, V., Purcell, D., & Scollie, S. (2012). A pilot study on cortical auditory evoked potentials (CAEPs) in children: aided CAEPs change with frequency compression hearing aid technology. International Journal of Otolaryngology, Article ID 982894.
Glista, D., Scollie, S., Bagatto, M., Seewald, R., Parsa, V., & Johnson, A. (2009). Evaluation of nonlinear frequency compression: Clinical outcomes. International Journal of Audiology, 48(9), 632-644.
Glista, D., Scollie, S., & Sulkers, J. (2012). Perceptual acclimatization post nonlinear frequency compression hearing aid fitting in older children. Journal of Speech, Language, and Hearing Research, 55(6), 1765-1787.
Hornsby, B.W.Y., Johnson, E.E., & Picou, E. (2011). Effects of degree and configuration of hearing loss on the contribution of high- and low-frequency speech information to bilateral speech understanding. Ear and Hearing, 5, 543-555.
Moeller, M., Stelmachowicz, P., Hoover B., Putman, C., Arbataitis, B., Wood, S., Lewis D., & Pittman, A. (2007). Vocalizations of infants with hearing loss compared with infants with normal hearing: Part I – Phonetic Development. Ear and Hearing, 25, 605-627.
Parsa, V., Scollie, S., Glista, D., & Seelisch, A. (2013). Nonlinear frequency compression: effects on sound quality ratings of speech and music, Trends in Amplification, 17, 54-68.
Pittman, A. L. (2008). Short-term word learning rate in children with normal hearing and children with hearing loss in limited and extended high-frequency bandwidths. Journal of Speech, Language, and Hearing Research, 51, 785-797.
Ricketts, T. Dittberner, A. & Johnson, E. (2008). High-frequency amplification and sound quality in listeners with normal through moderate hearing loss. Journal of Speech Language and Hearing Research, 51(1), 160-172.
Scollie, S. (2007, January 15). DSL version v5.0: description and early results in children. AudiologyOnline. Retrieved from: https://www.audiologyonline.com/articles/dsl-version-v5-0-description-959
Scollie, S. & Glista, D. (2011). Digital signal processing for access to high frequency sounds: implications for children who use hearing aids. ENT & Audiology News, 20(5), 83-87.
Scollie, S., Glista, D., Tenhaaf Le Quelenec, J., Dunn, A., Malandrino, A., Keene, K., & Folkeard, P. (2012). Ling 6 stimuli and normative data for detection of Ling-6 sounds in hearing level. American Journal of Audiology. 21(2), 232-241.
Stelmachowicz, P. G., Pittman, A. L., Hoover, B. M., Lewis, D. L. & Moeller, M. P. (2004). The importance of high-frequency audibility in the speech and language development of children with hearing loss. Archives of Otolaryngology Head and Neck Surgery, 130, 556-562.
Uys, M., Pottas, L., Vinck, B., & van Dijk, C. (2012). The influence of non-linear frequency compression on the perception of music by adults with a moderate to severe hearing loss: subjective impressions. South African Journal of Communication Disorders, 59(1), 53-67.
Wolfe, J., John, A., Schafer, E., Nyffeler, M., Boretzki, M., & Caraway, T. (2010). Evaluation of non-linear frequency compression for school-age children with moderate to moderately severe hearing loss. Journal of the American Academy of Audiology, 21(10), 618-628.
Wolfe, J., John, A., Schafer, E., Nyffeler, M., Boretzki, M., Caraway, T., & Hudson, M. (2011). Long-term effects of non-linear frequency compression for children with moderate hearing loss. International Journal of Audiology, 50(6), 396-404.
Cite this content as:
Scollie, S. (2013, May). 20Q: The Ins and outs of frequency lowering amplification. AudiologyOnline, Article #11863. Retrieved from: https://www.audiologyonline.com/

