
Nonlinear frequency compression is a proven technique for improving the ability of people with hearing impairment to detect and recognize high-frequency sounds. As difficulty perceiving such sounds is one of the most common characteristics of hearing loss, the practical success of frequency compression is a significant advance in the field of hearing instruments. SoundRecover, a Phonak proprietary algorithm implementing nonlinear frequency compression, is now available in a wide range of Phonak hearing instruments. Extensive trials have demonstrated the benefits of using SoundRecover for many adults and children with severe to profound hearing impairment. Similar benefits may also be obtained by users of SoundRecover who have less severe losses.
Introduction
A wide range of frequency-lowering schemes have been developed and tested experimentally. At present, several kinds of hearing aids from a number of manufacturers provide various types of frequency lowering (McDermott, Dorkos, Dean, & Ching, 1999;Simpson, Hersbach, & McDermott, 2005;Kuk, et al., 2006;Glista, et al., 2009;Kuk, Keenan, Korhonen, & Lau, 2009). However, these schemes are not all the same. The SoundRecover scheme introduced in Phonak Naida Ultra Power hearing instruments is not only technically distinct, but also one of the few schemes for which perceptual benefits have been evident in well-controlled, independent trials.
The rationale for developing these schemes is based on the observation that most people with hearing impairment have poorer perception of sounds at high frequencies. In many cases, high-frequency hearing sensitivity is so deficient that conventional amplification cannot make those sounds comfortably audible. Even when audibility can be achieved, it is still often difficult for people with moderately-severe or worse hearing loss to discriminate high-frequency sounds (Hogan & Turner, 1998). This is an important problem, because many complex sounds, including several phonemes that are often used in speech, contain significant high-frequency components. Furthermore, children learning spoken language experience particular difficulty when attempting to produce phonemes that they cannot hear adequately.
For some researchers in hearing and speech science, frequency lowering has been one potential solution to this problem. Although numerous schemes have been devised and evaluated experimentally, the outcomes have been mixed. With some schemes, the recognition of certain speech phonemes has improved, but at the expense of poorer identification of other phonemes. A few existing schemes have been shown to improve high-frequency sound perception, but the quality of the processed signal is marred by artifacts including clicks, other noises, and unintended changes in pitch. As a result, frequency-lowering schemes in general have not been widely accepted until recently as the advent of sophisticated digital signal processing capabilities in hearing aids has enabled innovative schemes to be implemented that avoid many of the technical problems that were encountered previously.
One scheme, introduced several years ago by Widex, is known as the Audibility Extender (Kuk, Keenan, Korhonen, & Lau, 2009). It implements linear frequency transposition that functions in the following way. Initially, two frequency regions are defined, designated respectively the source octave and the target octave. Sound signals within the source octave are analyzed continuously in real time, a dominant peak is selected, and the frequency of that peak is determined. All signal components in the source octave are then shifted down in frequency by a constant amount. The size of the shift is such that the selected peak is lowered in frequency by typically one octave (although different transposition parameters can be chosen during fitting of the aid to each user). Because the size of the shift applied to all signals present in the source octave is defined as a fixed number of Hertz, other components near the peak may be lowered by an amount that is not exactly one octave. For example, if the source octave contained a dominant peak at 4 kHz, that peak would be lowered by one octave to 2 kHz. As the size of this shift is 2000 Hz, all signal components in the source octave will be lowered simultaneously by the same amount. This means, for instance, that an input signal component with a frequency of 3.5 kHz will be lowered to 1.5 kHz, which is slightly more than a one-octave shift. It can be inferred that the application of this linear frequency-shifting process to each frequency in the source octave may result in a target bandwidth that is wider than one octave. To compensate for this effect, the output signals from the lowering process are filtered to limit the bandwidth to one octave. The transposed signals in the target octave are mixed with any signals already present in that frequency region. Amplification and other signal-processing functions are applied subsequently as usual. Once enabled during fitting, the transposition processing is active all the time.
In contrast, the nonlinear frequency-compression scheme introduced by Phonak, known as SoundRecover, does not involve any mixing of frequency-shifted signals with other signals already present at lower frequencies (Simpson, Hersbach, & McDermott, 2005;Glista, et al., 2009). Furthermore, the processing does not depend on detecting specific features of incoming sounds, such as the dominant peak frequency in the source octave of the linear transposition scheme. Instead, all frequencies above a so-called cut-off frequency are lowered by a progressively increasing amount. The growth in the amount of shifting across frequency is determined by a second parameter, the frequency-compression ratio. For example, if the cut-off parameter is set to 2 kHz, and the ratio is 2:1, each octave range of input frequencies above 2 kHz will be compressed into a half-octave range. Thus an input frequency range of 2-4 kHz, which is one octave wide, will become 2-2.8 kHz, or half an octave wide. All frequencies below the cut-off are unchanged by the processing. Although there is no overlap of shifted frequencies with any lower frequencies that may be present at the same time, frequency compression reduces the overall bandwidth of sounds at the output of the hearing instrument in comparison with the bandwidth at the input. When SoundRecover is enabled during fitting of the hearing instrument, values for the cut-off frequency and compression ratio parameters are preselected automatically based on the user's audiogram. As with linear frequency transposition, the SoundRecover non-linear frequency compression scheme operates all the time after initial activation.
Although the benefits of some modern frequency-lowering schemes have been demonstrated experimentally, a belief persists that such schemes are appropriate and effective only for peo¬ple with profound hearing loss in the high frequencies. However, recent research and technological developments have indicated that frequency lowering can be beneficial even for people with relatively good hearing sensitivity across most of the normally audible frequency range (Boretzki & Kegel, 2009). To what extent a perceptual benefit can be obtained depends both on the technical function of the frequency-lowering scheme, and on the way the variable parameters of the scheme are fitted to the individual hearing instrument user. These factors are discussed briefly here.
The importance of perceiving high frequencies
Speech and environmental sounds often contain, or are dominated by, high-frequency components. Being able to detect and identify such sounds is at least as important for people with hearing impairment as it is for people with normal hearing.
Figure 1 shows a spectrogram of forest sounds, including birds singing. In the spectrogram, time increases from left to right, and frequency from bottom to top. Lighter colors represent sound signals of higher intensity. In the birdsongs, the most intense acoustic components are at frequencies above approximately 2 kHz. Most of the sounds are concentrated in the range from 2 kHz to 5 kHz, although there are some components at even higher frequencies. Such sounds can be difficult for people with high-frequency hearing impairment to detect and discriminate.

Figure 1. A spectrogram of forest sounds including birds singing. Lighter colors represent sound signals of higher intensity.
Figure 2 is a spectrogram illustrating two speech sounds that are dominated by intense high-frequency components. The sequence of phonemes, which was produced by a female speaker, is /a-s-a-sh-a/. Note that the vertical frequency axis in this figure extends to 16 kHz. Although vowels have the most energy below approximately 4 kHz, the fricative consonants /s/ and /sh/ contain components that cover a wide range of generally higher frequencies. The /s/ sound has a broad peak from about 7 kHz to over 12 kHz, whereas the /sh/ sound covers a somewhat lower frequency range (approximately 3 kHz to 8 kHz).
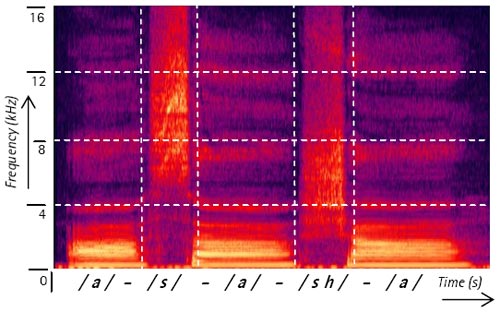
Figure 2. A spectrogram of the nonsense utterance /a-s-a-sh-a/. The two consonants /s/ and /sh/ are dominated by intense high-frequency components.
Stelmachowicz, Pittman, Hoover, and Lewis (2002) showed the phonemes /s/ and /z/ have the most spectral energy above 3 kHz for both male and female speakers. In fact, they found that the broad energy peak for the female speaker had a lower edge at approxi¬mately 5 kHz, and an upper edge above the highest frequency available in their analysis (8 kHz). These measurements illustrate that frequency regions significantly above 5 kHz often contain high levels of acoustic signals, especially when the speaker is female. Other studies have reported similar observations for child speakers. This information about the spectral characteristics of speech clearly reinforces the need for hearing instruments to deliver high frequencies to people with hearing impairment in order to maximize their understanding of speech.
How do conventional hearing aids process high frequencies?
The importance of high-frequency audibility for adequate speech understanding has been understood since the early days of amplification. In general, both the design and the fitting of hearing aids result in the provision of more gain at high frequencies. However, there are several potential practical limitations to the benefit available from high-frequency amplification, including: feedback in the hearing aid;hearing sensitivity being too poor for amplification to be usable;discomfort sometimes experienced from amplified high-frequency sounds;and the presence of dead regions in the cochlea.
The last point refers to a condition in which large numbers of certain hair-cells in the cochlea are absent or non-functional (Moore, 2001). Dead regions are more common in the basal parts of the cochlea, where high-frequencies are detected and converted into neural activity, than in apical cochlear locations. This condition is often associated with severe or profound loss of hearing sensitivity, but may occur at frequencies where hearing thresholds would suggest that hearing aid amplification would be appropriate. Individuals with extensive high-frequency dead regions may have abnormal perception of sounds containing high frequencies, even when they are made audible. This results in a poorer ability to identify such sounds than the audiogram would suggest.
Application of frequency compression to less-severe hearing loss
If the deterioration of hearing sensitivity in the high frequencies is not extreme, conventional amplification should be able to make sounds audible. However, although audibility is a necessary condition for sound recognition, it is not a sufficient condition. Many people with sensorineural hearing impairment cannot easily discriminate high-frequency sounds, even when they are fully audible. Therefore, the fundamental principle of frequency compression, that lowering significant frequency components will make them easier to perceive accurately, is applicable to a broad range of audiogram configurations, not just those showing minimal sensitivity at high frequencies. Furthermore, the preservation of sound quality achieved by Phonak's SoundRecover algorithm suggests that many users of hearing instruments who have relatively good high-frequency hearing would readily accept and benefit from frequency compression (Glista, et al., 2009). In fact, studies are confirming that such hearing-instrument users often find SoundRecover to be helpful, and that they generally prefer frequency compression to be enabled rather than disabled in blind trials (Nyffeler, 2008). The main challenge for successful use of SoundRecover is to ensure that the fitting is optimized for each individual.
Fitting and adjustment of SoundRecover
The initial fitting of frequency compression is based on the audiogram of the hearing instrument user. Two adjustable parameters, the cut-off frequency (the point above which the frequency compression and lowering is applied) and the frequency compression ratio (the amount of compression applied to frequencies above the cutoff), are preset within restricted ranges of 1.5 to 6 kHz, and 1.5:1 to 4:1, respectively. The values of these two parameters are automatically selected according to a rule that operates on the audiogram data. In brief, the cut-off frequency is set to a low value within the range if the audiogram shows relatively severe hearing impairment, or a relatively steep decline of hearing sensitivity towards higher frequencies. Conversely, the cut-off frequency has a relatively high initial setting when the hearing thresholds are not as severe, or the shape of the audiogram is flatter or slightly upward-sloping. Sounds below the cutoff frequency are not affected by SoundRecover, so there is no mixing or overlapping of sounds having different input frequencies.
After initial fitting, the amount of frequency compression that is applied can be adjusted for each user by means of a single adjustment slider in the fitting software. When the strength is varied, the cut-off frequency and the compression ratio are changed together based on an internal calculation. For example, if the user's audiogram slopes fairly uniformly from a threshold level of 60 dB HL at 250 Hz down to 95 dB HL at 4 kHz, the automatic initial fitting will set the cut-off frequency to 2.5 kHz and the compression ratio to 1.8:1. Subsequently, if the strength is decreased, the cut-off frequency will increase, resulting in frequency compression being applied across a narrower range of high frequencies. Conversely, if the strength is increased, the cut-off frequency will decrease. In the previous example, an increase in strength by two steps from the initial default setting will lower the cut-off frequency to 1.8 kHz. In general, the compression ratio changes in the same direction as the cut-off frequency, resulting in a smooth variation in the perceptual effect of frequency compression when the strength is adjusted. However, when the cut-off frequency reaches either the upper limit or the lower limit of the range (1.5 or 6.0 kHz), further strength adjustments result in changes made only to the compression ratio.
Current research suggests that even users of hearing instruments with mild losses find that SoundRecover can provide comfortable listening if the cut-off frequency is set relatively high, above 4 kHz (Boretzki & Kegel, 2009). This is not surprising, because there is little or no harmonic pitch information present in the high frequencies affected by frequency compression with such settings. On the other hand, there is useful information present in some high-frequency sounds, particularly the fricative consonants of speech. It is plausible that the perception of those sounds would be improved by limited application of frequency compression. Even people with normal hearing could theoretically benefit under certain listening conditions. In particular, when using a telephone, which has an upper frequency limit below 4 kHz, it can be difficult to understand unfamiliar words if they contain certain high frequency phonemes. For example, over the telephone /s/ is easily confused with /f/, and in many cases is not audible at all. Under these conditions, some frequency compression above a relatively high cut-off frequency could improve the listener's ability to hear and to discriminate such speech sounds. Therefore, it is highly likely that SoundRecover, when appropriately fit, could provide benefit to a majority of hearing instrument users.
References
Boretzki, M. & Kegel, A. (2009, May). SoundRecover - The benefits of SoundRecover for mild hearing loss. Retrieved on October, 30, 2009, from Phonak Field Study News: www.phonak.co.nz/com_fsn_srmildhl_may09-xx.pdf
Glista, D., Scollie, S., Bagatto, M., Seewald, R., Parsa, V., & Johnson, A. (2009). Evaluation of nonlinear frequency compression: Clinical outcomes. International Journal of Audiology, 48(9), 632-644.
Hogan, C.A. & Turner, C.W. (1998). High-frequency audibility: Benefits for hearing-impaired listeners. Journal of the Acoustical Society of America, 104, 432-441.
Kuk, F., Korhonen, P., Peeters, H., Keenan, D., Jessen, A., & Andersen, H. (2006). Linear frequency transposition: Extending the audibility of high frequency information. The Hearing Review, 13(10). Retrieved on October 30, 2009, from www.hearingreview.com/issues/articles/ 2006-10_08.asp.
Kuk, F., Keenan, D., Korhonen, P., & Lau, C. (2009). Efficacy of linear frequency transposition on consonant identification in quiet and in noise. Journal of the American Academy of Audiology, 20(8), 465-479.
McDermott, H.J., Dorkos, V.P., Dean, M.R., & Ching, T.Y. (1999). Improvements in speech perception with use of the AVR TranSonic frequency-transposing hearing aid. Journal of Speech, Language, and Hearing Research, 42,1323-1335.
Moore, B.C.J. (2001). Dead regions in the cochlea: Diagnosis, perceptual consequences, and implications for the fitting of hearing aids. Trends in Amplification, 5,1-34.
Nyffeler, M. (2008) Study finds that non-linear frequency compression boosts speech intelligibility. The Hearing Journal, 61(12), 22-26.
Simpson, A., Hersbach, A.A., & McDermott, H.J. (2005). Improvements in speech perception with an experimental nonlinear frequency compression hearing device. International Journal of Audiology, 44, 281-292.
Stelmachowicz, P.G., Pittman, A.L., Hoover, B.M., & Lewis, D.E. (2002). Aided perception of /s/ and /z/ by hearing-impaired children. Ear and Hearing, 23, 316-24.
