
Editor’s Note: This text course is an edited transcript of a live webinar. Download supplemental course materials.
This is going to be an old-school course. A few months ago, a colleague of mine asked me about an article. I was looking around in some old issues of Ear and Hearing and the Journal of the American Academy of Audiology (JAAA) to try to track down an article that I had a vague memory of. While I was doing that searching, I realized how many very good papers were written back at the time when I was in graduate school. I got my Master’s degree in 1984 and my doctorate in 1988. I was, of course, very interested in the sort of things then that I am still interested in now, which are sensorineural hearing loss, speech perception, and what hearing aids can do. I was reminded of how much information was being discovered at that time about the nature of sensorineural hearing loss and how complicated it could be.
Importantly, during the 60’s and 70’s, the field of audiology was looking at sensorineural hearing loss very much in terms of diagnostics. What could hearing testing tell us about the status of a person’s auditory system? Do they have an VIIIth nerve tumor? Do they have some other issue? As imaging studies got better, the interest in the nature of sensorineural hearing loss turned much more to the rehabilitation side to get a better understanding of the nature of sensorineural hearing loss and what could be done with hearing aids or other rehabilitation approaches to minimize the effects of hearing loss.
What I have noticed over the years, however, is that once multichannel nonlinear hearing aids entered the scene in the early 1990’s, the discussion of the nature of sensorineural hearing loss took a backseat, because it seemed like the only psychoacoustic aspect of sensorineural hearing loss that became interesting was audiometric thresholds, loudness growth and the width of the dynamic range. There are a tremendous number of papers that have been written over the last two-and-a-half decades about how to set up a hearing aid to compensate for threshold loss and to correct for the minimized dynamic range that comes with sensorineural hearing loss, but very little work has been done looking at other aspects of sensorineural hearing loss and what the implications are. When I was reading through the list of articles from the 80’s, it brought me back to my graduate school days and everything that I was learning about sensorineural hearing loss and the potential implications for fitting of hearing aids. I feel like a lot of that information has been forgotten or not viewed as relevant anymore for a variety of reasons. I decided to do this course examining what we really know about sensorineural hearing loss and take a new look at what we currently do in hearing aids and potentially in the future to compensate for some of these effects.
The A & D Components of Hearing Loss
In the title I talk about the distortional aspect of sensorineural hearing loss. That term comes from a paper written by Reinier Plomp, who is from the Netherlands, back in 1986. It was the culmination of a variety of different work that he was doing with his colleagues at the time, trying to better describe the nature of sensorineural hearing loss. He was also very interested in modeling, or, in other words, creating formulas to describe sensorineural hearing loss.
Very importantly in that paper, Plomp (1986) talked about the A and D components of sensorineural hearing loss. The A and D components refer to the attenuation that is created by the threshold change plus the distortion that occurs above threshold. So when sound is presented in the auditory system with sensorineural hearing loss and the sound is known to be audible because it has been verified to be above a person’s threshold, what changes occur to the way that sound is encoded by the peripheral auditory system that is different than normal? In other words, what sort of distortion does the peripheral auditory system add to the signal? Distortion can happen in a lot of places in the auditory system within the ascending tracks in the central auditory system, but I am going to the limit my comments today very specifically to the distortion that is added by the peripheral auditory system.
There is a lot of distortion added by the peripheral auditory system. The nature of that distortion and the amount of that distortion varies significantly from person to person with sensorineural hearing loss, and it can even vary significantly from one side of the head to the other. I am doing another talk in this series, specifically focusing on asymmetrical hearing loss. Therefore, I am not going to spend a lot of time talking about asymmetries in the auditory system today. I do want to quickly point out that these distortional aspects that happen in the auditory system can even vary from one side of the head to the other. Plomp was very interested in modeling the effects of distortion and trying to understand if we could predict those effects.
One of his great conclusions (Plomp, 1986) was that the distortional aspect that comes along with sensorineural hearing loss is not very well predicted by the amount of threshold hearing loss that a person has. It is true that as you have more threshold hearing loss, the nature of the distortion and the amount of distortion in the auditory system has a tendency to be greater, but the relationship between threshold and the amount of distortion is really quite weak. Importantly, Plomp talked about the distortional aspect of hearing loss, or the D component, as a measured speech-in-noise ability. He was doing an adaptive speech-in-noise test to come up with the signal-to-noise ratio loss that a person has. He used that as the metric of distortional hearing loss. I will talk a little bit more about that specifically.
In his 1986 paper, Plomp measured thresholds of hearing loss for three different groups of patients: presbycusis, noise-induced hearing loss, and other or unverified types of sensorineural hearing loss. As you know, pure presbycusis and pure noise-induced hearing loss are a little bit harder to delineate. There are usually more overlapping things going on. There was very little relationship between the amount of threshold hearing loss that a person had and their actual distortional component as Plomp describes it, which is a signal-to-noise ratio loss for speech, which is a very important observation to make.
Just this morning I was in contact with a colleague of mine, Michael Nilsson. Michael Nilsson works for Oticon in Denmark now, but he spent several years working at House Ear Institute. He was one of the major drivers of the development of the Hearing in Noise Test (HINT). I wanted to ask him what the relationship is between the amount of threshold hearing loss and the HINT scores. He came up with the same findings, that there is a very low correlation between the amount of hearing loss a person has as measured by pure-tone thresholds and what their signal-to-noise ratio loss is. This is an important observation because it suggests that those two dimensions are relatively independent, meaning that there are reasons to measure on both dimensions. Of course, all audiologists measure threshold; that is what we do. If we did not measure threshold, I do not know what we would do with our hands during the day.
The idea of determining how much signal-to-noise ratio loss a patient has is much more hit-and-miss in our field. Importantly, since those two dimensions are pretty much independent according to the data from Plomp (1986) and the data on the HINT, which would tell us something different about a patient that we should know. Unfortunately, we have not done a lot with that measure in our field. We do not use that measure to drive technology selection or rehab selections for patients in a big way. Sometimes we have a patient who really struggles in noise. Maybe it is a counseling issue about what their expectations could be, but we do not change the type of hearing aid that we fit for a person in a very planned way based on their threshold or what their change in signal-to-noise ratio loss is.
With our fitting routines, as you change the threshold, you change the fitting of a hearing aid; the more hearing loss you have, the more gain and compression is prescribed. But when you talk about measuring the D component or how much signal-to-noise ratio loss a person may have, we do not necessarily say, “Well if the D component is within 5 dB of normal, you do this with technology.” We do not have those sorts of rules, which is a reflection of the fact that we have not truly developed this side of our understanding about sensorineural hearing loss or changed fitting rules based on how much threshold loss or how much reduction in dynamic range a person would have.
The other comment I want to make about the D component is to think about it in a broader context. Plomp (1986) talks about the D component as measured by speech understanding in noise. When I talk about the D component, though, I would have you think of D as just the general distortion that occurs in the auditory system. One of the things that you will find over the next 45 minutes is that this D component can show up in a lot of different ways in the peripheral auditory system. It can be measured in a lot of different ways. The way it shows up for one patient can be quite different from another patient. Maybe for one patient it shows up in temporal processing. For another patient, it might show up more in terms of frequency discrimination abilities. For another patient, it might show up as upward spread of masking. I would encourage you to not think about distortion just as a signal-to-noise ratio score, but to think about it broadly in terms of changes in the core way that the peripheral auditory system encodes information.
The Distortional Component of Sensorineural Hearing Loss
Let’s talk about the distortional component of hearing loss. As I said, we have studied a lot about threshold and loudness changes in sensorineural hearing loss, or at least dynamic range size changes in sensorineural hearing loss and how you would change the prescribed compression in a hearing aid based on loudness changes. Of course, there are many more elements of the processing disruptions in sensorineural hearing loss.
Loudness Growth
Before we get into the other changes, I do want to spend a few minutes talking about loudness changes in the impaired ear. This is another area where the amount of evidence we have about what occurs as a result of loudness growth changes in an ear is not reflected in our clinical practice. Typically, the way a person fits a nonlinear hearing aid is to measure auditory thresholds and let the fitting software predict the upper range of hearing. Maybe they will measure uncomfortable loudness levels (UCLs) and put those in the fitting software, but once that goes in, there is little attention paid to how that actual growth of loudness will occur in a patient’s ear. We act as if that function is the same for all the ears within the fitting software. The reality is that it is not.
There are a variety loudness growth functions that could show up for different patients with different sensorineural hearing losses (Figure 1). Differences can occur within the same patient at two different frequencies or within the same patient in two different ears at the same frequency. One of things that we know is that some patients have a very restricted dynamic range where loudness grows very quickly, to a point where they need a much lower maximum output or amount of gain for loud inputs because they have a very restricted dynamic range, shown as the red line in Figure 1. Even two patients with the same threshold and same approximate UCL can have a very different way of getting between those two points. The light blue line is the typical pattern we think of in a loudness growth function, but you can also have patients where you see a much more shallow growth of loudness, where the sounds are softer for patients through a broader part of their dynamic range and then get loud very quickly towards the upper range of the dynamic range. You can also have patients where the growth of loudness is reflected in the green line, such that they never experience sounds as being very loud; in other words, there is something about the way loudness is encoded in the auditory system where you are never going to get things to be too loud for the patient. All those different functions can occur with the same amount of threshold hearing loss.
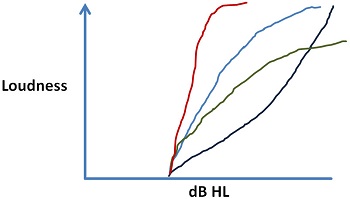
Figure 1. Typical patterns of loudness growth that can be seen in different patients or between different ears.
We have data from a paper by Gerry Studebaker and colleagues in 1999 where he presented speech at various different levels. He measured how much speech information the patient should get based on how much of the signal is above threshold and above the physical masking level of noise. Then he measured the actual performance of those patients, and he came up with a different score. If you remember RAU (rationalized arcsine transform), RAU is a variation of percent correct score. For this purpose, you could think about it as a difference in percent-correct score. One of the things to notice is what happens when you present speech at higher and higher presentation levels. This data happens to be for patients with sensorineural hearing loss. You would see the same function with individuals with normal hearing. What Studebaker et al. noticed is that the difference between how much speech understanding the patient should achieve and how much they do achieve gets greater and greater at higher presentation levels. In other words, if you push inputs up to the top end of the person's dynamic range, you start to decrease the ability of the ear to extract information from the signal. The human auditory dynamic range is not equally useful, whether or not you are talking about normal hearing people, but especially with people with sensorineural hearing loss. If you are at the top end of the range, you are dealing with a part of the dynamic range that does not encode information as effectively as other parts. Just because you have established a dynamic range does not mean that the ear is necessarily great at getting information from the signal. Even within the notion of loudness and loudness growth, there are variations from patient to patient of which we should be aware.
Frequency Resolution
Let’s talk about some other aspects of sensorineural hearing loss and processing. First, we will address frequency resolution. Frequency resolution is purported to be how well the ear can tell apart two sounds that are close in frequency. Most audiologists remember from their psychoacoustic training that frequency resolution can be relatively poor in cases of sensorineural hearing loss. Data from Nelson and Turner (1980) documents this. The psychoacoustic tuning curve is an indication of how precisely frequency is encoded in the auditory system. It indicates that if you put a sound in at 1,000 Hz and you measure the resolution of the auditory system, you see a very sharp resolution right around where you put the tone. The auditory system becomes very insensitive to sounds on either side of that tone very quickly, because of very precise tuning.
If you move to someone with a flat sensorineural hearing loss, and you do the same experiment, the psychoacoustic tuning curve requires a higher level of stimulation before you can get a response from the patient. You see much broader tuning. In other words, sounds at a very similar level, maybe a half octave difference, still can create stimulation and perception in the auditory system in the same frequency region. Basically the person has lost the ability to tell two closely aligned tones apart from each other. This is one of the observations that I think most audiologists are pretty comfortable with.
This loss of tuning shows up in different functional ways, and I want to dig more into that. Before I do, let me talk about some data from Simon and Yund (1993). There is tremendous resolution variability from person-to-person. In general, as you get more hearing loss, difference limens get greater, meaning the resolution is getting poor. The reason I like their graphic in the paper is that it shows you the amount of variation. Just like the observation that Plomp (1986) made about the signal-to-noise ratio loss is that the relationship between threshold and this level of distortion is weak at best, and there is a lot of variability from person to person. That is going to be a theme you are going to hear from me for the rest of the hour. The distortional aspect can show up with a lot of variability from person to person.
Inhibition
Another way of looking at frequency resolution is the loss of inhibition. One of the best ways to demonstrate inhibition is to show how it shows up in the visual system (Figure 2). You have probably seen this type of demonstration before, but when you look at that graphic with the black boxes and the white crosses, what you notice is the ghostly gray dots. You have this vague in-and-out perception of these gray dots that occur at the cross sections of the white bars. What you are seeing is the effect of inhibition.

Figure 2. Visual illusion as a result of the inhibitory system.
The visual system likes edges. It likes to know when an object starts and stops in space because it helps to define the object. The way it shows up is when you are firing one part of the retina, there is a de-sensitivity that occurs right next door to that part to help better define where that stimulation occurred. This is inhibition. It helps define the edges in the visual field. What ends up happening in this example is that when you see the gray dot from time to time, it usually does not happen if you are staring right at it. You have to look somewhere else and then the gray dot shows up. The reason the gray dot shows there is that you getting a lot of firing because of the white showing up in various places between the black boxes. Because you getting a lot of firing right in that area, all the de-sensitization adds up at those intersections. You are less sensitive to light coming from those intersections because your retina is really firing quite actively on the border between the black and white to you help you define that edge. That is where the ghostly gray dots come from.
The same effect occurs in the auditory system. This is data from a paper by Arthur et al. (1971). This was a psychoacoustic-tuning-curve-type experiment where you put in a probe tone at one particular frequency and you measure the sensitivity to that probe tone. In general, the sensitivity of the auditory system becomes less off-frequency from that probe tone as the intensity increases. These regions of gray are the inhibition regions. These are regions in which the response to a tone right at that particular frequency decreases in sensitivity, both to tones right above the frequency and right below the frequency. That is an indication of the same kind of edge affects that you see in the visual field. You do also see them in the auditory system. When the auditory system is responding to a sound at one particular distinct frequency, it decreases sensitivity to sounds close-by in frequency. One of the things we know about sensorineural hearing loss, and this has been established by a group of individuals I used to work with at Medical University of South Carolina a couple decades ago, is that one of the effects that happens in sensorineural hearing loss is that this inhibition is decreased. One of the effects of this loss of frequency resolution is that the zones of the inhibition are lost. The active processes within the cochlea that decrease sensitivity in those neighboring regions are lost in the presence of sensorineural hearing loss. That is one of the explanations for why tuning becomes broader in the auditory system.
One of the other observations that my former colleagues in South Carolina made is that there is a lot of variation from patient to patient with sensorineural hearing loss and the way these inhibition effects show up. Again, it comes back to the same theme over and over again that there is great variability from patient to patient.
Temporal Resolution
I want to talk about temporal resolution. Temporal resolution is an indication of how well the person can tell differences in the events that occur in the auditory system. The classic, basic way you measure it is gap detection. You turn on a tone that occurs over time, then you pause the tone very briefly and start it again. The question is how big of a gap is necessary for the person to be able to tell that the tone started and stopped. Normal hearing individuals need a very small gap; patients with sensorineural hearing losses typically need greater gaps. In general, once again, there is variability from patient to patient in how big that gap has to be.
A demonstration of the functional effects of temporal resolution was attempted by a group of researchers in Plomp’s lab back in the 90’s (Drullman, Festen & Plomp, 1994). They made a spectrograph of a speech signal and then they replicated or modeled the effect of poor temporal resolution. In other words, they tried to describe something that they believed would take effect if a person had poor temporal resolution. When you compare their recordings, the modeled spectrograph suggests that events in the auditory system are just not very well defined. In the original recording for a stop consonant, there was a very visible clear time period where the signal is gone, and then it starts again in a very rapid and dramatic way. For the reproduced model of loss of temporal resolution, that transition point is very obscured and blurry. It does not happen with a very clear, sharp sort of effect that you would expect if temporal resolution was very clear.
Other data I found was from a chapter that I read out of the Yost and Nielsen (1985) book, which was my psychoacoustic textbook when I was in grad school. It reminded me how important something like that is. This is replications of the pattern of firing in a variety of different nerve fibers throughout the auditory system. Normally we think of it occurring in what we refer to as a tonic nerve firing, meaning that if a signal starts, then the nerve starts to fire, and when signal goes away, the nerves stops firing. In reality, if you look at the firing patterns across a lot of different fibers in the auditory system, you see a lot of different patterns. You see that some only fire when the stimulus comes on, some that fire only when the stimulus turns off, some that fire when the signal starts and stops, but not while it is on. You can even see a pauser or chopper effect in the tone over time. The point is that the auditory system likes events. It likes the beginning and the end events. If you have poor temporal resolution or poor inhibition, those events are not well defined within the auditory system.
Upward Spread of Masking
One of the effects that you may remember learning about in grad school but do not think about much anymore is the idea of upward spread of masking. Upward spread of masking is based on the notion that, because of the asymmetrical nature of the traveling wave, you can have the effect that sounds of a low frequency will affect sensitivities higher in frequency because of the physical properties in the ear. The upward spread of masking occurs even in individuals with normal hearing, but it occurs more often and more dramatically in individuals with sensorineural hearing loss. In other words, every ear will have upward spread of masking. That is the effect of the traveling wave, but the effects vary from patient to patient.
The other thing about the upward spread of masking is that it gets greater in the higher frequencies at higher intensities. Figure 3 shows data for normal hearing for upward spread of masking, adapted from Gagné (1988) from Canada. The blue lines are the thresholds in the presence of a noise band at 500 Hz. You notice when the noise band is presented at 60 dB SPL that you get a certain threshold pattern in the higher frequencies. This is how much upward spread of masking you would expect to see for lower-level presentation. As you get to a higher presentation level for that frequency, you notice that these patterns become flatter, meaning that this noise at 500 Hz has a greater effect in the higher frequencies as you present higher intensities in the auditory system. This means it is very similar to the observation that Studebaker et al. (1999) made with speech presentation levels. The higher your push into the dynamic range of the person, the more likely you are going to get these upward spread of masking effects, even in the presence of normal hearing. Normally we talk about the upward spread of masking as a low-frequency to high-frequency effect. You should think of it as an effect that moves towards the high frequencies. In this case (Figure 3) even with the noise band set at 1,000 Hz, you still get these upward spread of masking effects.
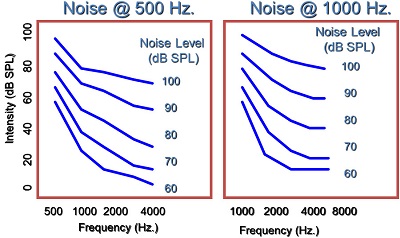
Figure 3. Normal hearing and the effects of upward spread of masking (Gagné, 1988).
Figure 4 is an example how it would show up in the audiogram. Imagine that you introduce a low-frequency noise. You would expect thresholds for that noise to follow the physical line of the noise. What you would really see, even in normal hearing is something that looks more like the dotted line, or the upward spread of masking effect that occurs even in normal hearing. If the individual represented in Figure 4 has a sloping high-frequency sensorineural hearing loss, then you would expect their sensitivity pattern to follow the noise level of the low frequencies. This blue line is what you could expect from a person with sensorineural hearing loss, meaning this would be their thresholds in the presence of that noise. Any difference between the blue line and the black line would be an indication of the excessive amount of upward spread of masking that is occurring because of the sensorineural hearing loss.
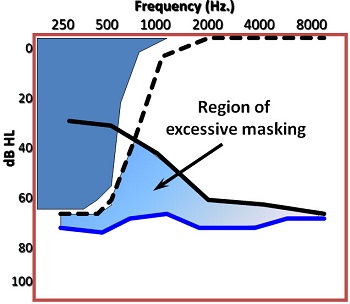
Figure 4. Measuring excessive masking in an individual with sensorineural hearing loss.
This pattern you see (Figure 4) is typical of a patient with sensorineural hearing loss. Maybe it is not quite as dramatic for some patients, but you still should see more upward spread of masking. Another example (Figure 5) is from Alan Klein and colleagues (1990) from Medical University of South Carolina. He presented a 1,000 Hz low-pass noise into ears and measured the person’s threshold. The gray line would be what a person with normal hearing would get with the presence of that noise. You see some upward spread of masking effects. If you did not see upward spread of masking even in normal hearing, the thresholds would be all the way back to zero by the time you got to 2,000 Hz, and you do not see that effect. Lower frequency sounds can be disruptive toward the higher-frequency sounds. It is a classic hallmark of sensorineural hearing loss.
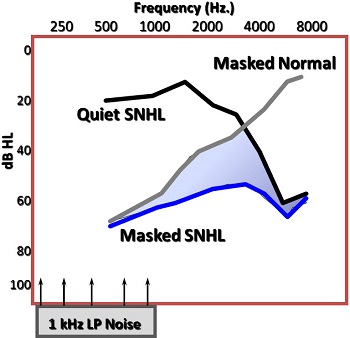
Figure 5. Excessive upward spread of masking (Klein, Mills & Adkins,1990).
How does it affect perception? Think of a vowel where you have three formants. Usually, the first formant is going to be more intense than the higher-frequency formants. If you have excessive upward spread of masking in a patient with sensorineural hearing loss, you could have an effect with the first formant of the vowel such that it obscures the perception of the second formant. The second and third formants are the formants that give an indication of the identity of that particular vowel. If you present this signal at too high a level in the auditory system and do not control for upward spread of masking, you can very easily get some perceptual complications for speech as you go higher in the auditory system.
One other aspect about masking that a lot of people forget is that there is a temporal effect (Figure 6). In other words, a physical masker that occurs at a very discrete point in time could reach backwards in time and forward in time to create a masking effect. Remember that the auditory system is not instantaneous; once you get into encoding of the neural signal, you have to get a certain amount of a stimulation built up in the in the nervous system before the fibers fire. Because of that, if you present a soft sound, there might not have been enough build-up of firing to occur before a more intense stimulation occurs right after it. This masker could reach back in time and obscure this perception of this very soft sound. It happens even more forward-wise, whereas a relatively intense sound occurs and a softer sound occurs right after that can be hard to perceive because of the lingering effect in the central auditory system of this physical masker.
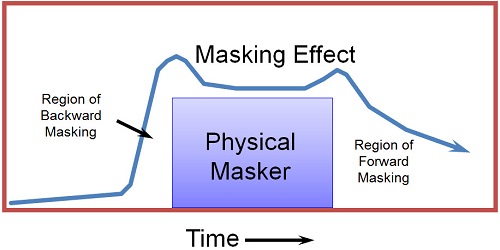
Figure 6. Effects of temporal masking.
The reason this is important is because that is the way speech is structured. We have vowels and consonants. If you have a soft consonant like /f/ or /th/ that occurs right before or after an intense vowel, you can have trouble perceiving that consonant, even if it physically should be audible to the patient. Let’s say you have an intense vowel with an intense first formant followed by /th/. If you measure just the /th/ in isolation and find that it is audible to the patient, that does not guarantee that that /th/ would be perceived by the patient in the presence of a low-frequency vowel if you are not controlling the upward spread of masking effects in the patient, which I will talk about in a few moments.
I am going to repeat one point that I made earlier that variability in psychoacoustic processing is the norm and not the exception. On any dimension of the distortional aspect of hearing loss that you look at, there is variation from patient to patient. The idea that two patients with the same audiogram are going to have ears that respond to sound in the same way is a very naïve way of treating the way the auditory system works, because we know it is more complicated than that.
The Effect: Speech Understanding in Noise
The effect on speech understanding in noise is fairly well documented. One of the things we know is that there is a lot of patient-to-patient variation in the signal-to-noise ratio needed for 50% correct when you listen to speech (Dirks, Morgan & Dubno, 1982). What you see in Figure 7 is the range of normal hearing individuals and the range of patients with sensorineural hearing loss in a variety of different speech-in-noise tasks. There is very great variability, even greater than the variability that Plomp (1986) was talking about in terms required signal-to-noise ratio. Anyone who does the HINT or the QuickSIN on a regular basis knows what this sort variability can look like.
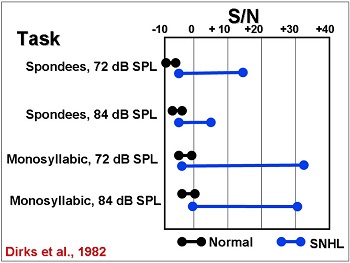
Figure 7. Range of signal to noise ratios required for individuals with normal hearing (black) and sensorineural hearing loss (blue); adapted from Dirks et al., 1982.
Although we think about speech as a broadband signal over the long term, on an individual phonemic basis the speech signal is not broadband. It is made up of, not necessarily narrow bands or pure tones, but rather something in between, where you will get energy that is distributed across relatively narrow windows of a frequency. Sometimes you get multiple windows at the same time that define a speech sound. Speech is a series of relatively narrow or moderate-band events that occur in rapid succession. Oftentimes they occur simultaneously at different frequencies.
Figure 8 is a spectrogram of the production “two weeks later.” The real encoding of the speech signal requires that you have precisely enough frequency coding to tell that an event occurred at this particular frequency region and/or that particular frequency region, either at the same time or different times. Since those events change rapidly over time as you produce many phonemes, you need to have very good temporal resolution to make sure that you know that a sound stopped or started. For example, you can see the closure phase of the /k/ in “two weeks” in Figure 8. You need to be able to define that something stopped and started again when the /k/ is released and the /s/ starts. You need very good frequency resolution to tell the different frequency regions apart, but also very good temporal resolution to know when these events occur and do not occur. We know that both of those get lost. Look at how small that closure phrase is on that /t/. You need that in order to find the presence of a /t/.
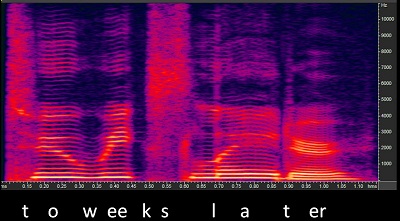
Figure 8. Spectrogram of the phrase “two weeks later.”
Speech is a series of these very precise events. We can take /s/ for example. Let’s say it is the voice you are listening to versus the voice you are not listening to. Those two are going to have a very similar frequency range, so it is not just whether or not those two sounds are audible to the patient, but whether they are defined well enough compared to the other sounds that are occurring to allow the central auditory system to identify it as an /s/, and, more specifically, as an /s/ that belongs to the voice you are listening to and not to the voice that you are trying to ignore.
You want to know that your temporal and frequency resolution is sharp enough that when the speech events occur for the voice that you are trying to pay attention to, that those stand apart from the other sounds that are entering the auditory system. Achieving speech recognition is making sure that the individual acoustic events stand out against the clutter well enough to be linked; and linked is the big word. I am not going to go into the cognition of speech understanding, but remember that speech understanding does not occur in isolation. It is not individual phonemes; rather, it is how these phonemes combine over time to create perception.
How Do We Address Distortion in Hearing Aids?
I want to talk about how we currently address this in hearing aids. What we do in hearing aids is a little bit more complex than you might think. For example, we all know that the very best thing that you can do in a hearing aid is to improve the signal-to-noise ratio and the audibility for the patient. We use multichannel, nonlinear compression to try to maximize audibility for the patient. You use directionality to try to get rid of the noise when possible. You do not use noise reduction to improve the signal-to-noise ratio. That is a misnomer. The only technology that directly affects the signal-to-noise ratio is directionality. Those are the most immediate and most obvious things that we do, but there are other subtle things that happen in hearing aids to minimize the effect of distortional hearing loss.
Control the Lows
One of the things is to control the lows. I spent some period of time talking about the presence of upward spread of masking. Obviously, upward spread of masking has been something that we identified 30 or more years ago, and it quickly made its way into hearing aid fitting. For example, for this flat hearing loss seen on the left panel of Figure 9, you can see that the NAL-NL2 gain prescription for a 55 dB input is relatively flat on the right panel. What you see is a flat amount of prescribed insertion gain at 500 Hz and above, but below 500 Hz, you see a pretty rapid roll-off in the prescribed response, even though the patient has the same amount hearing loss below 500 Hz as they do above it. We do not amplify those low frequencies because of the concerns of upward spread of masking.
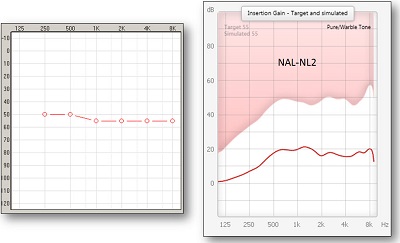
Figure 9. Moderate, flat hearing loss (left panel) and NAL-NL2 prescription for this hearing loss, with roll-off in the low-frequencies.
This is the same way it is handled in Oticon’s Voice Aligned Compression. We employ the same sort of roll-off effects in the low-frequencies. It also occurs in DSL [i/o] where they roll-off the low frequencies, even though the main goal is to increase audibility across the bandwidth. They still will try to control upward spread of masking by rolling off the low frequencies.
One of the ways to look at it is the way it affects the speech signal (Figure 10). The gray is the unamplified long-term spectrum of speech, and the red is the amplification based on the Voice Aligned Compression. The goal above 500 Hz is to get a lot of good audibility for the speech, and it will make it above threshold. But below 500 Hz, you see very little change in the ongoing speech signal. In this case, you see some compression being applied to the speech signal with very little gain. The whole idea is to keep it from creating upward-spread-of-masking effects.
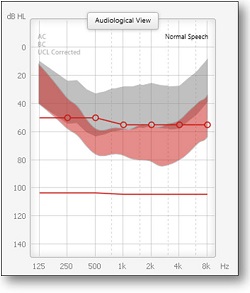
Figure 10. Controlling for upward spread of masking. The gray is the unaided long-term average speech spectrum; red is amplification based on controlling for low-frequency upward spread of masking.
One of the things I want to point out from the data from Klein and colleagues (1990) is that upward spread of masking is not something that just occurs at 250 Hz and spreads upward in frequency. It can occur at any part of the auditory system. You can have a patient who is very sensitive to upward spread of masking. It could be that the small amount of gain at 1000 Hz could harm the perception higher in frequency. It is the sort of thing that we do not have good predictions for. We do not measure this clinically, and we really do not pay much attention to it anymore. However, you should know that upward spread of masking, although it is generally controlled in the hearing aid in the very low frequencies, can also be causing problems in the higher frequencies.
Increase the Bandwidth
Another good example of what we do in a hearing aid is increasing the bandwidth. By increasing the bandwidth, the assumption is that you are allowing more speech phonemes to be audible. This is absolutely true, but remember the speech importance function from the articulation index or the speech intelligibility index (SII). There is not a lot of assumed speech energy that improves perception above 5,000 Hz. Although we know that there is energy in the speech signal above 5,000 Hz, the articulation index or the SII is not a really accurate way of thinking about what is going on in the high frequencies. One of the things we do with increasing the bandwidth is to increasingly give access to phonemes in the high-frequencies. It also increases the likelihood that the person is going to hear some speech energy in the high frequencies. In other words, they may have been able to perceive the presence of /s/ with energy only below 5,000 Hz. But if you had energy above 5,000 Hz, you might increase the chance that the particular /s/ sound would stand out above the noise or competing voices going on in the rest of the room. What you are doing is not just making the signal audible, but you are increasing the chance that the auditory system is going to notice that sound.
There is another aspect about increasing bandwidth for which people may not have an appreciation. Providing high-frequency speech energy above 8,000 Hz is a little more than you typically think about in terms of information that is necessary for the hearing impaired. By having energy from the speech signal in the very high frequencies, even though there is not necessarily a lot of phonemic information in this range, does help the listener localize where the talker is coming from. One of the things that we know about the auditory system is that knowing where sound is coming from helps to focus in on the speech signal to which we are listening.
In this experiment by Best et al. (2005), they modified the amount of speech energy that they were providing to listeners in the very high-frequencies. They noticed that as they decreased the information in the signal in the very high-frequencies, the ability to tell where the sound was coming from became worse. One of the best skills you have when negotiating a complex listening environment is being able to organize the environment and tell where sound is coming from. One of the advantages of increasing the bandwidth in the hearing aid is helping the patient better localize the speech signal in the environment. Even though they do not necessarily use that information for phonemic understanding, knowing where the sound comes from allows you to focus your attention to that part of the room. Increasing the bandwidth and thus improving localization is designed to improve speech understanding in noise.
Multichannel Wide-Dynamic Range Compression (WDRC)
Multichannel WDRC is another hearing aid feature that we use. One of the main reasons for using WDRC is to increase audibility, but one of the other things that you remember about WDRC is that it is designed to help minimize the effect of upward spread of masking. You can process the lower frequencies separately from the higher frequencies. You have what I call the decoupling of the response of the hearing aid between the vowels and the consonants. In that upward spread of masking effect where you had an intense low-frequency vowel followed by a soft high-frequency consonant, being able to set the gain independently for those two sounds is one of the advantages of multichannel nonlinear systems. It is to make sure that you can do what you want to the audibility in the high frequencies, independent of what you are going to do in other frequency regions.
The other advantage of multichannel nonlinear WDRC is that you are able to play with the time consonants in order to package the information with care. Because of the distortional differences between different ears with sensorineural hearing loss, some ears are more sensitive to what happens with compression than others. Being able to increase audibility, especially for softer high-frequency sounds, is important as long as it is done carefully. If it is done poorly, you can sometimes detract from perception because you are using too much compression in the signal. Multichannel WDRC can harm speech understanding for some patients under some conditions. In those cases, on an individual basis, compression can be thought of as being “too strong”. The compression ratios may look fine for the typical patient, but for a significant subset of patients, they may not be able to resolve the details of the signal. The problem can also be addressed by looking at compression timing parameters.
In WDRC, there is more done in the circuitry than just making everything audible. It is making everything audible, but in a way that is designed to minimize some of the effects of the distortional hearing loss. As I said, audibility and increasing the signal-to-noise ratio are the primary things that you try to do in a hearing aid to minimize the effect of the distortional aspect. In some cases, you do some more subtle things with the way these multichannel nonlinear systems are set up.
De-sensitivity
The final aspect of what we do in hearing aids is de-sensitivity. This is driven by the discussion of dead zones. Sometimes you might not be able to use high-frequency information as effectively if you have more than a moderate hearing loss. How does this show up clinically? In the NAL-NL2, they desensitize the response in the higher frequencies. I put in three relatively flat audiograms that increased in threshold by 15 dB each. If you look at the NAL-NL2 response (Figure 11), going from the lesser amount of hearing loss (left) to the moderate amount (middle) to the higher amount (right), you can notice a little bit of a desensitization or a drop in the gain in the higher frequencies compared to the mid frequencies as the hearing loss gets worse. You would think the opposite would occur. You would think you would be trying to maximize audibility for those soft high-frequency sounds, but because of this potential for dead zones, the NAL-NL2 does this desensitization to try to focus the response more in the mid frequencies were the ear is probably working a little bit better. There is a lot of variability from person to person and a lot of controversy about whether or not dead zones can be measured and predicted well. Again, you should know that it does show up in the way some of the software is applied.
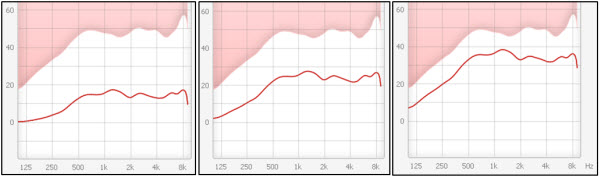
Figure 11. NAL-NL2 applications of 3 different flat audiograms: 40-50 dBHL (left), 55-65 dBHL (middle), and 70-80 dBHL (right).
What does the Future Hold?
Finally, I wanted to make a few comments about the future. The very best thing that could happen in hearing aids going forward is further signal-to-noise ratio improvements: better directionality or better signal processing to get rid of the background noise. It is not just the hearing aid industry that is interested in being able to do this. However, we are not seeing anything groundbreaking on the horizon in this area. It is a very tough nut to crack. Although that is the best thing that we can do to defeat the distortional aspect of hearing loss, you are not going to see a lot of that in the immediate future, based on what is currently going on in research labs.
Reverse Engineering of Sensorineural Hearing Loss
There is a little bit of interest in reverse engineering of the hearing loss. For example, I will go back to this example on temporal processing that I brought up. If a person’s ear is responding in a way where there is a lot of smear in the auditory system, are there enhancements that we can make to the signal that will undo or prevent this auditory smear before it happens so that the person perceives something with more clarity, even though their peripheral auditory system is going to smear the signal? The idea would be to somehow overly enhance the borders between sounds. That sort of work is ongoing, but there has not yet been a lot of breakthrough work in that area. Again, the idea is to defeat the distortional aspect before it occurs by over-processing the signal ahead of time to counteract what you know is going to happen later in the auditory system. We might see some movement on this topic over the next decade.
Phoneme Enhancement
Finally, we have phoneme enhancement. This is something that has been talked about for over 20 years in hearing aids. For example, you would go in and find some of the soft high-frequency consonants in a phrase (Figure 12). The idea would be to take the /z/ in “please” and the frication part of the affricate in “much” and “change and somehow enhance those particular phonemes without touching the other things. The problem with that is that it requires some very effective processing and algorithms that have not been described yet. Although there is work going in many different areas to try to achieve very individual phonemic enhancement, we are just not seeing a lot of that showing up in commercial hearing aids yet. Over the next 5 to 10 years, you might start to see more of that.
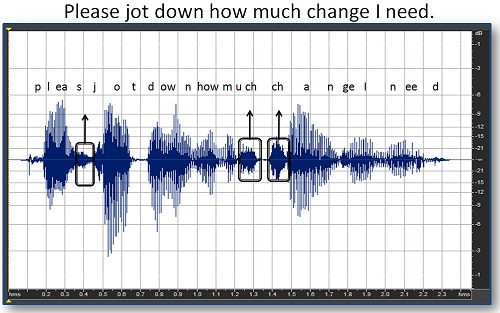
Figure 12. Soft phonemes in the phrase “please jot down how much change I need” are identified. Phoneme enhancement would attempt to heighten these phonemes for better clarity.
References
Arthur, R. M., Pfeiffer, R. R., & Suga N. (1971). Properties of “two-tone inhibition” in primary auditory neurones. Journal of Physiology, 212, 593–609.
Best, V., Carlile, S., Jin, C., & van Schaik, A. (2005). The role of the high frequencies in speech localization. Journal of the Acoustical Society of America, 118(1), 353-363.
Gagné, J-P. (1988). Excess masking among listeners with sensorineural hearing loss. Journal of the Acoustical Society of America, 83, 2311-2321.
Drullman, R., Festen, J. M., & Plomp, R. (1994). Effect of reducing slow temporal modulations on speech reception. Journal of the Acoustical Society of America, 95(5 Pt 1), 2670-2680.
Dirks, D. D., Morgan, D. E., & Dubno, J. R. (1982). A procedure for quantifying the effects of noise on speech recognition. Journal of Speech and Hearing Disorders, 47, 114-123.
Klein, A. J., Mills, J. H., & Adkins, W. Y. (1990). Upward spread of masking, hearing loss, and speech recognition in young and elderly listeners, 87(3), 1266-1271.
Plomp, R. (1986). A signal-to-noise ratio model for the speech-reception threshold of the hearing impaired. Journal of Speech and Hearing Research, 29(2), 146-154.
Studebaker, G., Sherbecoe, R., McDaniel, D. & Gwaltney, C. (1999). Monosyllabic word recognition at higher-than-normal speech and noise levels. Journal of the Acoustical Society of America, 105(4), 2431-2444.
Nelson, D. A. & Turner, C. W. (1980). Decay of masking and frequency resolution in sensorineural hearing-impaired listeners. In G. van den Brink & F.A. Bilsen (Eds.), Psychophysical, Physiological and Behavioural Studies of Hearing (pp. 175-182). Delft, The Netherlands: Delft University Press.
Simon, H. J., & Yund, E. W. (1993). Frequency discrimination in listeners with sensorineural hearing loss. Ear and Hearing, 14(3), 190-201.
Yost, W. A., & Nielsen, D. W. (1985). Fundamentals of hearing, 2nd edition. New York, NY: Holt, Reinhart & Winston.
Cite this content as:
Schum, D. (2013, July). The distortional aspect of sensorineural hearing loss: What can be cone. AudiologyOnline, Article #11976. Retrieved from: https://www.audiologyonline.com/

