
1Rush University Medical Center, Communication Disorders and Sciences
2Veterans Affairs of Northern California
Abstract
Hearing impaired listeners have linked the ability to perceive environmental sounds to safety, well-being, and aesthetic concerns. That being said, relatively little is known about cochlear implant patients' ability to perceive environmental sounds. This article provides an overview of past and present research on environmental sounds and explores factors that may affect environmental sound perception of cochlear implant patients. Somewhat surprisingly, the findings reveal that experienced postlingual cochlear implant patients demonstrate rather mediocre ability in identifying environmental sounds. Furthermore, this ability is strongly associated with their ability to perceive speech. This study highlights two important considerations. First, there is a need to develop environmental sound tests, which may be useful in predicting speech performance for cochlear implant patients. Second, cochlear implant patients may benefit from environmental sound training as part of their rehabilitation program.
Introduction & Background
Most listening environments contain a great variety of acoustic signals. Although communication researchers to date have concentrated primarily on speech and, to a lesser extent, music, there is a growing appreciation of the importance of other meaningful sounds in the rich acoustic texture of everyday life. Indeed, perception of other environmental sounds (i.e., nonspeech and nonmusical sounds that convey information about specific objects and events) plays an important role in navigating successfully through one's environment. Environmental sounds can provide the listener with information about what is happening around him/her, where it is happening, and how it is happening (Gaver, 1993). This information enables the listener to avoid danger (e.g., approaching cars) and, in general, enhances the awareness of the sound sources in the surrounding world. In addition to obvious safety concerns, perception of environmental sounds has also been linked to the overall sense of well-being. Hearing the soothing sounds of waves on the beach or birds chirping in the forest provides aesthetic and emotional satisfaction to most listeners.
Despite numerous positive and valuable aspects of environmental sound perception, there is limited knowledge about environmental sound perception abilities, relevant factors, and associated perceptual processes in normal and hearing impaired individuals. Nevertheless, historically, there have been some clinical applications of environmental sounds as test materials. Much of this work was performed during the early days of cochlear implants (CI) in order to evaluate the potential benefits of early devices (Maddox & Porter, 1983;Edgerton, Prietto, & Danhauer, 1983;Eisenberg, Berliner, House, & Edgerton, 1983;Blamey et al., 1984;Tyler et al., 1985). Other studies have been conducted with patients with cerebral lesions to compare the perception of language sounds with that of other meaningful and complex sounds (Spreen & Benton, 1974;Varney, 1980;Varney & Damasio, 1986). Still others used environmental sounds to obtain hearing evaluations for children and other difficult to test patient populations (Lancker et al., 1988).
There were, however, several potential flaws associated with early tests. These included lack of normative data, a limited and arbitrary selection of environmental sound samples (typically 20 or less), a shortage of variability among tokens used to represent each sound source, and lack of uniformity in scoring procedures. Many early environmental sound tests given to CI patients were administered in an open-set format (Edgerton et al., 1983;Proops et al., 1999;Schindler & Dorcas, 1987), in a closed-set format (Eisenberg et al., 1983;Tye-Murray, Tyler, Woodworth, & Gantz, 1992;Tyler et al., 1988), or in both formats in a single study (Blamey et al., 1984;Tyler et al., 1985). Scoring procedures for open-set identification responses were rarely explained (e.g., could 'baby' and 'crying' both count as correct responses for the sound of 'baby crying'?). When tests were given in a closed-set format where the number of response alternatives was fewer than the number of test sounds (Maddox & Porter, 1983), it was not clear how the response alternatives had been selected for specific sounds. Environmental sound tests administered to other patient populations such as patients with brain lesions (Spreen & Benton, 1974;Varney, 1980;Varney & Damasio, 1986) or children with autism (Lancker et al., 1988) shared similar limitations.
The results of early CI studies indicated clear implant benefits;however, there was a wide range in performance in environmental sound identification among CI patients, from marginal to nearly perfect. Anecdotal reports and studies where multiple environmental sound tests were administered over time indicated that after a marked initial improvement, environmental sound performance became asymptotic (Proops et al., 1999). Numerous factors could have accounted for these findings. In addition to the potential limitations of test materials discussed above, most of these studies were performed using single or few-channel implant devices. Therefore, it is reasonable to expect that recent advances in device design and signal processing, coupled with a generally better hearing ability of many CI patients, may result in better overall environmental sound identification. More recent experimental evidence provides some support for this possibility (Reed & Delhorne, 2005), although other results are less encouraging and demonstrate mediocre performance (Inverso, 2008).
In the study conducted by Reed & Delhorne (2005), 11 experienced CI patients (six-channel Ineraid or eight-channel Clarion devise users) were asked to identify four sets of 10 environmental sounds, each represented by three different tokens. Each set represented one of four typical environmental settings (general home, kitchen, office, and outside). The patients were always told the name of the environmental setting to which the stimuli belonged (e.g., kitchen sounds). The mean environmental sound identification accuracy across all sets was 79% correct, with a range of 45% - 94%. The authors reported that patients appeared to rely on temporal cues such as sound duration and gross envelope properties. Furthermore, temporal and spectral cues were used more effectively by patients with better speech perception scores.
In another recent study (Inverso, 2008), a group of 22 postlingually deafened users of Clarion implants showed a poorer performance than mentioned in the previous study. These patients were asked to identify 50 environmental sounds and then assign them to one of five categories (animal sounds, human nonspeech sounds, mechanical and alarm sounds, nature, or musical instruments). Overall patients achieved 49% accuracy for sound identification and 71% on sound categorization. One reason for the difference in performance between the two studies might be the more constrained testing conditions used in the first study (i.e., patients knew the environmental context for each of the ten sounds in the set). Thus, their task might have been somewhat easier to perform. However, both studies demonstrate that even experienced CI patients have difficulties with environmental sound perception.
In order to maximize implant benefits and improve CI patients' perception of environmental sounds, it is important to understand what factors are involved in their identification. In the remainder of this article, we will review physical and perceptual factors involved in environmental sound perception, provide initial environmental sound data from CI patients with modern-day devices, and suggest some directions for future clinical and research work in environmental sound perception in CI patients.
Acoustic Factors and Signal Processing Parameters
Similar to speech and music, environmental sounds are semantically and acoustically complex heterogeneous signals with a variety of periodic and aperiodic components. There are multiple spectral and temporal cues that listeners can use in environmental sound identification. The redundancy of cues is such that listeners can adopt different strategies for identifying a sound and still achieve the same level of performance (Lutfi & Liu, 2007). However, only some of these cues may be transmitted by implant devices when acoustic signals are transformed into electrical impulses that stimulate the auditory nerve. Therefore, it is important to understand how implant processing modifies the perceptually salient cues in the acoustic signal and what effect it has on environmental sound perception. This knowledge can provide a basis for optimizing signal processing parameters for perception of a large variety of environmental sounds.
One useful and convenient way to determine relevant acoustic factors and signal processing parameters in environmental sound perception is by using vocoder simulations of implant processors. All acoustic signals recorded by the implant are transformed by the speech processor into electrical signals delivered to the auditory nerve by the implanted electrodes. In most processors, after initial automatic gain control, input signals are sent through a bank of band pass filters, followed by envelope extraction from each frequency band. The energy envelope of each band of the signal is then used to modulate the amplitudes of electrical pulses delivered by implant electrodes. A similar algorithm is followed in a vocoder simulation, but instead of modulating electrode pulses, the energy envelope of each band modulates the dynamic amplitude of a particular carrier signal (typically a noise band or a sine wave) specific to the frequency of each band. The resulting output is thus acoustic rather than electric (Figure 1). However, in both cases, only information about the gross energy patterns for each frequency band is preserved in the stimulation pattern delivered by the implant;information contained in fine-grained spectral details and temporal fine structure is lost or distorted during processing.
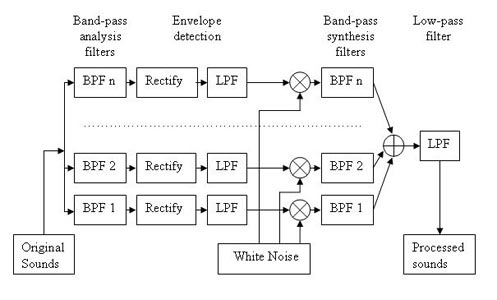
Figure 1. Block diagram illustrating the envelope-vocoder algorithm used to simulate cochlear implant processors. In Experiment 1 and 3, the actual number of filters in the analysis and synthesis filterbank varied between 2 and 32 (Adapted from Shafiro, 2008a).
Vocoder simulations provide an opportunity to investigate the effects of various signal processing manipulations in normal hearing listeners rather than actual CI patients. In a sense, acoustic simulations mimic the information that can 'ideally' be transmitted by the implant and avoid various confounding factors that are difficult to control in CI patients (e.g., electrode placement and depth of insertion, electrode cross-talk, number of surviving ganglion cells, duration of deafness, etiology of hearing loss). Although simulations are only approximations of real implant results, they have been used extensively in the past in addressing various questions in speech perception of CI patients, and simulation results often show good correspondence with that of CI patients.
Optimal Number of Frequency Channels for Environmental Sound Perception: Initial Findings
One of the central questions in implant processing is how many frequency channels are needed for adequate perception? Because implant processing results in a reduction of fine spectral and temporal details of the signal, it is important to know how much of this reduction can be tolerated without substantial losses in perception. For example, only four spectral channels may be needed to perceive speech (Shannon, Zeng, Kamath, Wigonski, & Ekelid, 1995). Although this number varies somewhat as a factor of listener experience and difficulty of materials, it is generally agreed that fairly accurate speech perception in quiet can be obtained with 8-12 channels.
In a recent study (Shafiro, 2008a), we investigated the optimal number of frequency channels for environmental sounds. The environmental sound stimuli included 60 environmental sounds which represented a variety of sound source categories and included a) human and animal vocalizations and bodily sounds, b) signaling and alarm sounds, c) water related sounds, d) sounds of interacting mechanical components, and e) aerodynamic sounds. These sounds were processed through a noise-based vocoder (Figure 1) with a varying number of frequency channels (i.e., 2, 4, 8, 16, 24, and 32). The six frequency channel conditions were blocked and presented to 60 normal-hearing listeners in a Latin-square design in which every listener heard each of the 60 sounds in only one frequency channel condition. In the end, every listener heard all 60 original sounds to establish baseline accuracy.
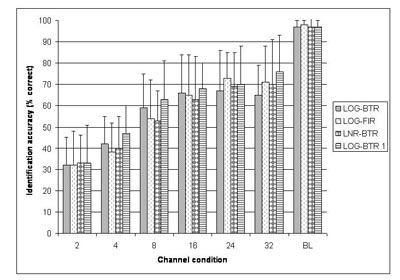
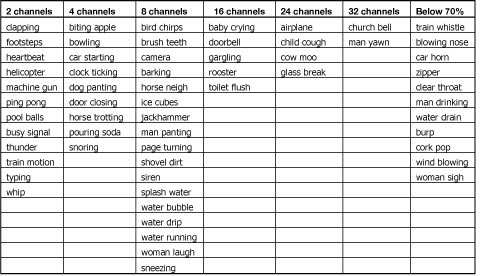
As expected, listeners were highly accurate in the perception of nonvocoded original sounds (P(c) = 95%), confirming that all selected sounds were highly recognizable. Across the frequency channel conditions, however, identification accuracy was low in the two and four channel conditions (P(c) =32% and 42%, respectively), increased rapidly in the eight channel condition (P(c)=59%), and was asymptotic thereafter (Figure 2, LOG-BTR). Environmental sound stimuli that could be identified with low numbers of frequency channels (i.e., two and four) included relatively long sounds with distinct temporal energy patterns and typically noisy spectra (e.g., footsteps, helicopter). Sounds identified only with a high number of frequency channels (i.e. 16 and 32) showed distinct resonant structure and less temporal variation (Table 1).
Click Here to View Larger Version of Fig 2 (PDF)
Figure 2. Average identification accuracy across channel conditions for four different signal processing methods used in Experiments 1 & 3. LOG-BTR denotes the signal processing used in Experiment 1, while LOG - FIR, LNR - BTR, LOG - BTR 1 represent the three signal processing methods in Experiment 3. BL denotes the band-limited control stimuli with preserved fine spectra obtained from all listeners in each of the four signal processing conditions (Adapted from Shafiro, 2008a).
Click Here to View Larger Version of Table 1 (PDF)
Table 1. Environmental sounds, arranged by the minimal number of channels needed to reach an identification accuracy of 70% or higher. The last column contains sounds that did not reach 70% accuracy in any channel condition of Experiment 1 (Adapted from Shafiro, 2008a).
Acoustic analysis demonstrated that when sounds were grouped by the number of frequency channels required for 70% correct identification, they differed significantly on a number of acoustic measures. Sounds were divided into two groups: (a) sounds identified with 8 frequency channels or less and (b) sounds that needed 16 channels or more, which included those not identified with 70% accuracy at all (on the assumption that these sounds required spectral resolution of more than 32 channels to be identified). The statistically different measures included: pause-corrected and raw root-mean-square (RMS) energy, envelope peak statistics (i.e., maximum peak height, standard deviation of peak height, range of peak height), number of bursts in the envelope, moments of the modulation spectrum (i.e., centroid, standard deviation, skewness, kurtosis), number of peaks in the envelope autocorrelation, mean pitch salience, and centroid velocity (maximum, mean and standard deviation). Interestingly, no significant differences were found within these broad channel groups (i.e., either within 8 channels or less or within 16 channels or more).
Follow-up discriminant analysis further revealed that based on only two of these acoustic measures, the number of bursts in the envelope and the standard deviation of centroid velocity, sounds could be classified into the two broad groups (8 channels or less and 16 or more) with a relative high accuracy of 83% (Figure 3).
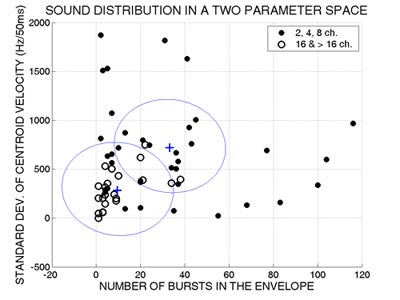
Figure 3. Sound distribution in a two parameter space. Filled circles represent the sounds that required 8 or fewer channels to be identified with a 70% or better accuracy. Empty circles designate sounds that required 16 channels or more. The two crosses mark the centroids of the two groups. The line between the two centroids separates the sounds into those optimally classified by the discriminant analysis as requiring 8 channels or fewer vs. those requiring 16 channels or greater. (Adapted from Shafiro, 2008a).
Sounds that have a high number of bursts in the envelope (e.g., helicopter) or contain considerable variation in centroid velocity (e.g., camera) needed only a small number of frequency channels (Figure 4).
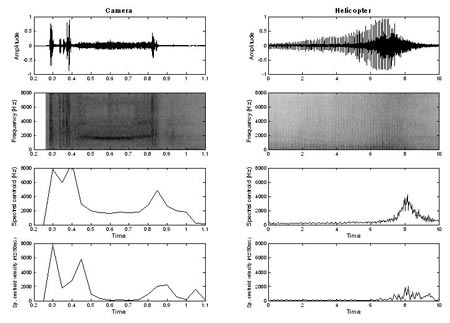
Figure 4. Waveforms, spectrograms, spectral centroid, and spectral centroid velocity vs. time of two sounds in the group requiring lower spectral resolution (2 - 8 channels). The sound on the left (camera) required 8 channels, whereas the sound on the right (helicopter) required 2 channels to be identified with 70% accuracy in Experiment 1. Note the large differences in duration of the two sounds (Adapted from Shafiro, 2008a).
On the other hand, sounds that have low values on these two acoustic measures (e.g., rooster and clearing throat) needed a much greater number of frequency channels (Figure 5). Overall, it appears that simple spectral and temporal acoustic measures can be quite accurate in predicting the number of frequency channels required for environmental sound identification in simulated CI processors.
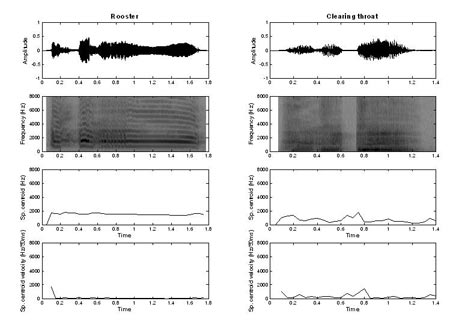
Figure 5. Waveforms, spectrograms, spectral centroid, and spectral centroid velocity vs. time of two sounds in the group requiring higher spectral resolution (16 or more channels). These sounds required 16 channels (rooster) to be identified with 70% accuracy or did not reach 70% accuracy (clearing throat) in any channel condition of Experiment 1 (Adopted from Shafiro, 2008a).
One unexpected result of this experiment was that for many environmental sounds, an increase in the number of frequency channels did not lead to an improvement in identification accuracy. For almost a third of the test sounds, as the number of frequency channels continued to increase, identification accuracy declined by one standard deviation or more relative to the accuracy already reached with less channels. Possibly because of this decline, overall identification performance remained asymptotic and well-below that for original sounds, even in higher frequency channel conditions (Figure 2, LOG-BTR vs. BL).
Further investigation revealed that most affected sounds were sounds that contained temporally-patterned brief impact components (e.g. footsteps). An examination of waveforms of these sounds across frequency channel conditions showed significant spectro-temporal distortions as the number of channels increased (Figure 6). As can be seen in the two upper panels of Figure 6, the high and low frequency energy corresponding to individual footstep events is temporally aligned for original and two-channel stimuli. However, as can be seen in the lower panel of this figure, the low frequency energy is delayed relative to the high frequency energy in the 32-channel stimulus. This distortion could have resulted from the variation in the filter release time as a function of filter group delay specific to each of the analysis filters. Because the bandwidth of the vocoder analysis filters implemented in the stimulation varied logarithmically across the frequency range, the group delay times of the narrow low frequency filters were much larger than group delay times of broader high frequency filters. These differences were most pronounced in conditions with a high number of frequency channels, confirming the potential involvement of group delay effects.
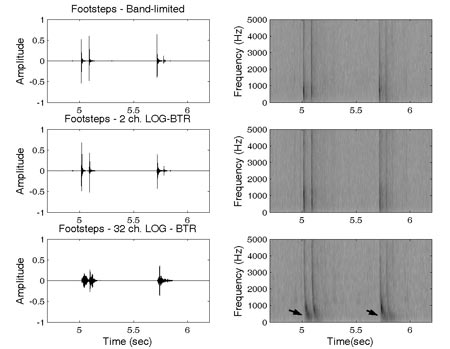
Figure 6. Waveforms and spectrograms of the sound 'footsteps' in band-limited, 2 and 32-channel conditions. The arrows on the spectrogram of the 32-channel sound indicate the spectral region where the effects of cross-channel asynchrony can be observed (Adapted from Shafiro, 2008a).
Effects of Cross-Channel Asynchrony
A follow-up experiment, Experiment 2, was conducted to investigate the role of spectral asynchronies produced by unequal filter group delays in environmental sound perception (Shafiro, 2008a). The stimuli in this experiment were 45 environmental sounds that were not identified with 100% accuracy in the 32 channel condition of the aforementioned study (Experiment 1). There were three spectral asynchrony conditions. Two of the conditions manipulated the spectral asynchrony induced by group delays but preserved spectral information in each frequency band. That is, in the first condition, all 45 sounds were processed by a bank of 32 band pass filters, same as the filters used in the 32 channel condition of the first experiment (FLT1). In the second condition, the processing was the same except that the stimuli were processed by the filter bank twice, thus doubling the amount of delays for each frequency band (FLT2). In the third condition, the stimuli were the same as in the vocoded 32-channel condition of Experiment 1 and thus had reduced spectral information in addition to spectral asynchrony effects (SMR32). Ten normal-hearing subjects identified all of the stimuli randomized and blocked by delay condition, and in the end, they all identified the original control stimuli.
Results indicated a significant effect of spectral asynchrony in the first two conditions even without the reduced spectral resolution present in the third condition (SMR32). Error rates for the FLT2 stimuli that were sent twice through the filter bank were greater than those of the original stimuli, or FLT1 stimuli, that were processed only once (Figure 7). As can be seen in Figure 7, subjects made the largest number of errors in the SMR32 condition that combined spectral reduction and spectral asynchrony effects. This finding suggested that spectral asynchrony induced through filter group delays might have contributed to the decline in identification performance observed for some sounds in the previous experiment, especially when combined with reduced spectral resolution. However, these results could not indicate how much the negative perceptual effects of spectral asynchrony contributed to the decline in identification performance in Experiment 1.
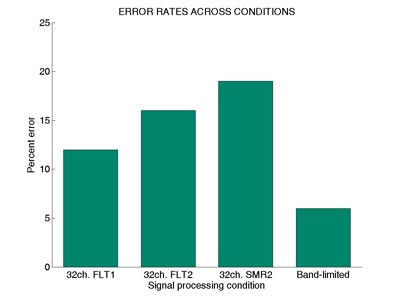
Figure 7. Mean error rates across two spectrally preserved (FLT1 and FLT2),
spectrally smeared (SMR2), and control (Band-limited) conditions of Experiment 2
(Adapted from Shafiro, 2008a).
Optimal Number of Frequency Channels: Reducing Cross-Channel Asynchrony
To determine whether environmental sound perception across frequency channel conditions would improve if group delay differences were minimized during signal processing, Experiment 3 was completed. Experiment 3 replicated Experiment 1 using three different signal processing methods that minimized cross channel group delays. The stimuli used in each original frequency channel condition were obtained by (1) using long FIR filters that all have the same group delays and preserved the same filter bandwidths as in the initial logarithmically spaced analysis bands (LOG-FIR);(2) using linearly spaced 6th order Butterworth filters (LNR-BTR) that have the same group delay;or (3) modifying the vocoder algorithm to process a white noise carrier through the synthesis filters before multiplying it with each band envelope (LOG-BTR1), which reduced the original group delay by about one half. With a between-subject design, the stimuli were presented to three groups of 24 subjects each. However, as can be seen in Figure 2, the pattern of results across frequency channel conditions was remarkably similar to that in Experiment 1. Thus, the negative effects of spectral asynchrony play only a marginal role in identification accuracy and therefore in the decline in environmental sound identification. Other factors, such as the distortions of temporal fine structure or the need for much greater spectral resolution by some sounds, are also likely inhibitors of further improvement in overall accuracy in the conditions with a high number of channels.
Overall, the results of the preceding experiments demonstrate fair environmental sound identification accuracy (i.e., approaching 70%) with 8-16 frequency channels. Vocoder type signal processing, implemented in most implants, can introduce cross-channel spectral asynchronies to the implant output;however, the negative effects of asynchrony on environmental sound perception appear to be small and do not have a major impact on the overall identification accuracy. Finally, simple spectral and temporal acoustic measures seem to be able to account for the differences in spectral resolution required for 70% correct identification and can be used to predict, with reasonable accuracy, the number of channels required for identification of specific sounds.
Behavioral Findings
Another aspect of environmental sound perception that contributes to CI patient performance is the ability of individual listeners to make use of the low-level sensory information transmitted by their devices. Depending on a number of patient specific factors, which include etiology, person's age, the duration of deafness, and the amount of experience with the implants, the performance of individual CI patients may vary widely among their peers and in comparison to simulation studies. Thus, the following experiments explored the performance of actual CI patients and rehabilitative techniques that may lead to improved performance (Shafiro, 2008b;Shafiro et al., 2008).
Previous findings with acoustic simulations, as described above, indicate that normal hearing listeners are able to achieve approximately 60-70% accuracy in environmental sound identification tests with 8 to 16 channels. This frequency channel range is available in most of the present-day implants. Therefore, one might expect that CI patients will perform similarly to simulated implant participants, especially given that CI patients also may have more implant listening experience. However, given technological improvements in implant design and signal processing in the last decade and the paucity of data available on environmental sound performance in patients with modern-day implants, it was important to assess just how well CI patients can identify environmental sounds. To do this, we developed a new environmental sound test that could provide a more sensitive measure of environmental sound identification performance and also be used for training and rehabilitation purposes.
Extended Environmental Sound Test
In an attempt to develop a comprehensive standardized test of environmental sound perception, a new 160 item environmental sound test was compiled (Shafiro, 2008b). It consists of 40 unique sound sources, each represented by four different tokens, thus increasing the variability among specific representations of each source. The selected sounds represent a variety of sound sources and included (a) human and animal vocalizations and bodily sounds, (b) mechanical sounds of interacting inanimate solids, (c) water related sounds, (d) aerodynamic sounds, and (e) electric and acoustic signaling sounds. Most of the selected sounds overlap with those used in previous environmental sound research with normal-hearing (Gygi, Kidd, & Watson, 2004;Shafiro, 2008a;Marcell, Borella, Greene, Kerr, & Rogers, 2000;Shafiro & Gygi, 2004;Ballas, 1993) and hearing-impaired listeners (Reed & Delhorne, 2005;Owens, Kessler, Raggio, & Schubert, 1985). The specific stimuli were selected from previously used stimulus sets with known identification accuracy. Remaining stimuli were obtained from royalty-free internet sound libraries (Shafiro & Gygi, 2004). Twenty-one normal hearing listeners identified selected sounds in a 60 alternative closed set response task with the average accuracy of 98% and a standard deviation of 4%.
Perception of Environmental Sounds by Cochlear Implant Patients
To obtain preliminary data about CI patients' ability to identify environmental sounds and investigate an association between speech and environmental sound perception, the environmental sound test described above and four speech tests (the HINT, CNC, and individual 20 consonant and 12 vowel tests) were administered to 17 CI patients. The test battery also included tests of basic auditory abilities (audiometric thresholds, gap detection and temporal order tests) and a backward digit recall test. All participants were postlingually deafened adults, having one to seven years of implant experience.
As can be seen in Figure 8, the results indicated substantially reduced ability to identify common environmental sounds in CI patients relative to normal hearing listeners (P(c) = 46% vs. 98%, respectively). Such sounds as brushing teeth, wind, pouring soda into a cup, and blowing nose were least recognizable, whereas laughing, dog barking, doorbell, and birds chirping were most recognizable. The patient accuracy scores on speech tests were P(c) = 68% HINT in quiet, 55% HINT in noise, and P(c) = 52% CNC. All speech test scores correlated strongly and significantly with the environmental sound test scores: r = 0.78 for HINT in quiet;r = 0.76 for HINT in noise, r = 0.75 for CNC, r = 0.69 for vowels, and r = 0.72 for consonants. Several tests of basic auditory abilities also correlated with speech and environmental sound scores. There were moderate-to-strong negative correlations between the temporal order test and the environmental sound and speech tests, ranging from r = - 0.44 to - 0.64, indicating that patients with better speech and environmental sound scores could judge pitch changes in shorter tone sequences.
In order to further investigate the relationship between speech and environmental sounds, partial correlations were performed, controlling for the variance of significantly correlated tests of basic auditory abilities. The results revealed some decrease in the correlation magnitudes. However, overall speech and environmental sound correlations remained in the moderate range (r = 0.58 to 0.67), indicating that most of the variance in the relationship between speech and environmental sounds was not likely to be due to "low-level" basic auditory processing. Importantly, all CI participants expressed an interest in further rehabilitation.
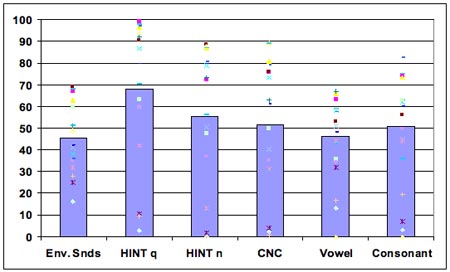
Figure 8. Performance accuracy across environmental sounds and speech tests (with individual subject data points).
Effects of Training on the Identification of Spectrally Smeared Environmental Sounds
Auditory rehabilitation has been recommended and used as a way to increase CI patient benefits (Fu & Galvin, 2007;Sweetow & Sabes, 2007;Clark, 2003;Sweetow & Palmer, 2005;Busby, Roberts, Tong, & Clark, 1991). It is based on the premise that active learning of the new patterns of distorted sensory information provided by the implant can lead to relatively quick and long-lasting improvements in neurophysiologic processing (i.e. neuroplasticity). Research evidence indicates that improvements in peripheral processing alone are not sufficient to explain the range of variation in CI performance or improvement over time (Svirsky et al., 2001). A renewed interest in active auditory rehabilitation is further stimulated by the availability of commercially available computerized training programs. Although some environmental sounds are included in at least some recent training programs (e.g., Sound and Beyond, Hearing Your Life), the selection of the environmental sounds and their use during training is not based on solid evidence. Presently, there is little systematic knowledge about the time course and the extent of perceptual adaptation to environmental sounds in CI patients. In addition, it is unclear whether learning to identify such sounds involves the re-learning of each individual sound (Tye-Murray et al., 1992) or whether after practicing with some sounds, training effects can generalize to other sound sources in the environment (Rosen et al., 1985).
To investigate the effect of training on the identification of spectrally-degraded environmental sounds, seven normal-hearing subjects were tested in a pretest-posttest design with five training sessions. Stimuli included four channel vocoded versions of the environmental sound test described above (Shafiro, 2008a). The training sounds were selected individually for each subject and comprised one half of the sound sources that were misidentified in the pretest. During training, subjects received trial and block feedback. Overall, the average identification accuracy of spectrally-degraded sounds improved from 33% correct on the pretest, to 63% correct on the posttest (Figure 9). The largest improvement (86 percentage points) was obtained for the sound tokens used during training (Figure 10). The identification accuracy for alternative tokens of the training sounds (that referenced the same sources but were not used in training) improved by 36 percentage points. Finally, the identification of sound sources not included in the training, but perceived with equal difficulty on the pretest, improved by 18 percentage points. These results demonstrate the positive effects of training on the identification of spectrally-degraded environmental sounds and suggest that training effects can generalize to novel sounds.
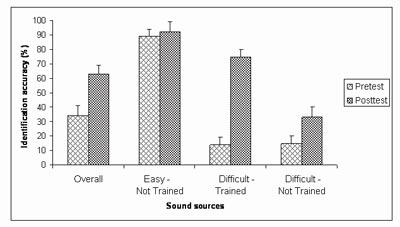
Figure 9. Identification accuracy on the pretest and the posttest of sound sources overall and in each of the three source groups: 1) Easy - Not Trained (source identified with accuracy greater than 50% correct on the pretest, and not used in training), 2) Difficult - Not Trained (sources identified with accuracy 50% correct or less, not used in training), 3) Difficult - Trained (sources identified with accuracy 50% or less, two exemplars of which were used in training). The accuracy of the sources in the last group represents the average of all four exemplars of these sources on the posttest. (Adapted from Shafiro, 2008b).
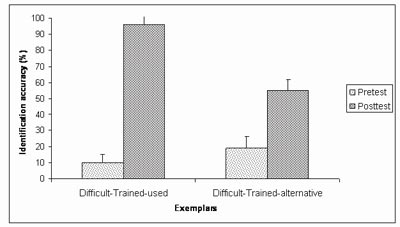
Figure 10. Identification accuracy on the pretest and the posttest for the two subgroups of the Difficult-Trained sound sources: Difficult-Trained-used (two exemplars of each source selected for training and used during training) and Difficult-Trained-alternative (two exemplars of exemplars of each source selected for training, but not used during training) (Adapted from Shafiro, 2008b).
An ongoing replication study by Markee, Chandrasekaran, Nicol, Shafiro, & Kraus, N. (2009) with three (instead of five) training sessions and 18 listeners, also measured changes in brainstem and cortical auditory event-related potentials (ERP) to some vocoded environmental sounds before and after training. Behavioral findings closely resembled those obtained earlier by Shafiro (2008b), in which the overall improvement after training was 30 percentage points for the Shafiro study and 21 for the Markee study. The analysis of ERP responses to two sounds (burp and cow) revealed significant changes in the amplitude of the responses at the cortical but not brainstem level. Interestingly, these cortical changes were observed both following training and following repeated testing without training, suggesting that neural plasticity can occur in some cases following simple exposure to the stimuli.
Summary and Future Research
The perception of environmental sounds, along with speech, is one of the most important ecological functions served by human hearing. It creates greater awareness of the immediate dynamic environment, helps to avoid danger, and contributes to an overall sense of well-being (Gygi et al., 2004;Jenkins, 1985;Ramsdell, 1978;Gaver, 1993). With the advances in CI technology in the last decades, it is now possible to provide functional hearing to many deaf individuals, often enabling them to perform previously impossible communicative tasks (e.g., talking on the telephone). However, CI patients' ability to perceive environmental sounds has received little attention, despite patients' considerably reduced environmental sound perception ability and their reported interest in improving it further, as described above. Although most CI patients can develop some environmental sound perception without active training, their performance remains substantially lower than that of normal-hearing listeners. It is unknown whether experienced implant patients can benefit from environmental sound training, if training effects can generalize to other sounds, or if the benefits of training are retained after training stops.
In addition to serving an important ecological function, environmental sound perception appears to be closely associated with speech perception (possibly more so than any other nonlinguistic auditory test;see, for instance, Kidd, Watson, & Gygi, 2007). If an environmental sound test is confirmed to be highly predictive of speech performance in CI patients, it may have potential for far reaching diagnostic applications. For example, it can help in determining implant candidacy or in assessing implant performance when speech tests are not available in a patient's language or when they cannot be administered due to other disabilities. Other hearing impaired patient populations that may benefit from an environmental sound test include children, prelingually deafened CI patients, and patients with brainstem implants. Furthermore, recent CI simulation research has shown that environmental sound training can produce an improvement in speech perception as well as in environmental sound perception (Loebach & Pisoni, 2008). Given that the majority of active rehabilitation programs are English-based, the possibility of gaining an improvement in both environmental sound and speech perception through non-language-specific environmental sound training appears highly attractive.
In our current research we are exploring the effects of computerized training on the perception of environmental sounds and speech, developing a new online environmental sound database that will be a resource for clinicians and researchers exploring the effects of auditory context on environmental sound identification (Gygi & Shafiro, 2007). We expect that in the near future we will be able to expand our theoretical understanding of environmental sound perception and the associated factors and processes, and we will be able to provide diagnostic and rehabilitation methods that will benefit current and future cochlear implant patients.
Support of this research was provided by NIH-NIDCD, Deafness Research Foundation, American Speech Language Hearing Foundation, and Rush University Committee on Research.
References
Ballas, J.A. (1993). Common factors in the identification of an assortment of brief everyday sounds. J. Exp. Psychol.: Human Perception and Performance, 19 (2), 250-267.
Blamey, P. J., Dowell, R. C., Tong, Y. C., Brown, A. M., Luscombe, S. M., and Clark, G.M. (1984). Speech perception studies using an acoustic model of a multiple-channel cochlear implant. J. Acous. Soc. Am, 76(1), 104-110
Busby, P.A., Roberts, S. A., Tong, Y.C., Clark, G.M. (1991). Results of speech perception and speech production training for three prelingually deaf patients using a multiple-electrode cochlear implant. Br J Audiol., 25, 291-302.
Clark, G. (2003). Cochlear implants: Fundamentals and applications. New York: Springer-Verlag.
Edgerton, B.J., Prietto, A., & Danhauer, J.L. (1983). Cochlear implant patient performance on the MAC battery. Otolaryngologic clinics of North America, 16, 267-280.
Eisenberg, L.S., Berliner, K.I., House, W.F., & Edgerton, B.J. (1983). Status of the adults' and children's cochlear implant programs at the House Ear Institute. Annals of the New York Academy of Science, 405, 323-331.
Fu, Q.J. & Galvin, J.J. (2007). Perceptual learning and auditory training in cochlear implant recipients. Trends in Amplification, 11, 193-205.
Gaver, W. W. (1993). What in the world do we hear?: An ecological approach to auditory event perception. Ecological Psychology, 5(1), 1-29.
Gygi, B., Kidd, G.R., & Watson,C.S. (2004). Spectral-temporal factors in the identification of environmental sounds. Journal of the Acoustical Society of America, 115, 1252-1265.
Gygi, B. & Shafiro, V. (2007). The effects of auditory context on the identification of environmental sounds. Proceedings of the 19th International Congress on Acoustics, Madrid, Spain.
Inverso, D. (2008). Cochlear implant-mediated perception of nonlinguistic sounds. Unpublished dissertation. Gallaudet University.
Jenkins, J. J. (1985). Acoustic information for objects, places, and events. In W. H. Warren & R. E. Shaw (Eds.), Persistence and Change, pp. 115-138. Hillsdale, NJ: Lawrence Erlbaum Associates, Inc.
Kidd, G.R., C.S. Watson, and Gygi, B. (2007). Individual differences in auditory abilities. Journal of the Acoustical Society of America, 122(1), 418-435.
Lancker, D., Cornelius, C., Kreiman, J., Tonick, I, Tanguay, P., & Schulman, M. L. (1988). Recognition of environmental sounds in autistic children. Journal of the American Academy of Child and Adolescent Psychiatry, 27, 423-7.
Loebach, J. L. & Pisoni, D.B. (2008) Perceptual learning of spectrally degraded speech and environmental sounds. J. Acoust. Soc. Am., 123(2), 1126-39.
Lutfi, R.A. & Liu, C.J. (2007). Individual differences in source identification from synthesized impact sounds. Journal of the Acoustical Society of America, 122(2), 1017-1028.
Maddox, E. H. & Porter, T.H. (1983). Rehabilitation and results with the single electrode cochlear implant. Otolaryngologic clinics of North America, 16, 257-265.
Marcell, M.M., Borella, D., Greene, J., Kerr, E., & Rogers, S. (2000). Confrontation naming of environmental sounds. Journal of Clinical and Experimental Neuropsychology, 22, 830-864.
Markee, J., Chandrasekaran, B., Nicol, T., Shafiro, V., & Kraus, N. (2009). The effect of training on brainstem and cortical auditory evoked responses to spectrally degraded environmental sounds. Poster presented at the American Academy of Audiology Convention, Dallas, TX.
Owens, E., Kessler, D. K., Raggio, M.W., & Schubert, E. D. (1985). Analysis and revision of the Minimal Auditory Capabilities (MAC) battery. Ear & Hearing, 6, 280 -290.
Proops, D.W., Donaldson, I., Cooper, H.R., Thomas, J., Burrell, S.P., Stoddart, R.L., Moore, A., & Cheshire, I.M. (1999). Outcomes from adult implantation, the first 100 patients. Journal of Laryngology and Otology, 113, 5-13.
Ramsdell, D. A. (1978). The psychology of the hard-of-hearing and the deafened adult. In H. Davis & S. R. Silverman (Ed.), Hearing and Deafness (pp. 499-510). New York: Holt, Rinehart and Winston.
Reed, C. M., & Delhorne, L. A. (2005). Reception of environmental sounds through cochlear implants. Ear and Hearing, 26(1), 48-61.
Rosen, S., Fourcin, A. J., Abberton, E., Walliker, J. R., Howard, D. M., Moore, B. C., Douek, E. E., & Frampton, S. (1985). Assessing assessment. In R. A. Schindler, & M. M. Merzenich (Eds.), Cochlear implants (pp. 479-498). New York: Raven Press.
Schindler, R. A. & Dorcas, K. K. (1987). The UCSF/STORZ cochlear implant: Patient performance. American Journal of Otology, 8, 247-255.
Shafiro, V. & Gygi, B.(2004). How to select stimuli for environmental sound research and where to find them? Behavior Research Methods, Instruments, and Computers, 36(4), 590 - 598.
Shafiro, V. (2008a). Identification of environmental sounds with varying spectral resolution. Ear and Hearing, 29(3), 401- 420.
Shafiro, V. (2008b). Development of a large-item environmental sound test and the effects of short-term training with spectrally-degraded stimuli. Ear and Hearing. 29(5), 775-790.
Shafiro, V., Gygi, B., Cheng, M., Mulvey, M., Holmes, B. & Vachhani, J. (2008). Relationships between environmental sounds and speech in cochlear implant patients. Poster presented at the annual convention of the American Speech-Language-Hearing-Association, Chicago, IL.
Shannon, R. V., Zeng, F., Kamath, V., Wigonski, J & Ekelid, M. (1995). Speech recognition with primarily temporal cues. Science, 270, 303-304.
Spreen, O. & Benton, A. L. (1974). Test of Sound Recognition. Iowa City: Department of Neurology, University of Iowa Hospitals
Svirsky, M. A., Silveira, A., Suarez, H., Neuburger, H., Lai, T. T. & Simmons, P. M. (2001). Auditory learning and adaptation after cochlear implantation: a preliminary study of discrimination and labeling of vowel sounds by cochlear implant users. Acta Oto-Laryngologica, 121(2), 262-5.
Sweetow, R.W. & Palmer, C.V. (2005). Efficacy of individual auditory training in adults: a systematic review of the evidence. J. Am Aced Audiol., 16, 494-504.
Sweetow, R.W. & Sabes, J.H. (2007). Technological advances in aural rehabilitation: Applications and innovative methods of service delivery. Trends in Amplification, 11, 101-111.
Tye-Murray, N., Tyler, R.S., Woodworth, G.G., & Gantz, B.J. (1992). Performance over time with a Nucleus or Ineraid cochlear implant. Ear and Hearing, 13, 200-209.
Tyler, R.S., Lowder, M.A., Gantz, B.J., Otto, S.R., McCabe, B.F., & Preece, J.P. (1985). Audiological results with two single channel cochlear implants. Annals of Otology, Rhinology, and Laryngology, 94, 133-139
Tyler, R.S., Abbas, P., Tye-Murray, N., Gantz, B.J., Knutson, J.F., McCabe, B.F., Lansing, C., Brown, C., Woodworth, G., Hinrichs, J., & Kuk, F. (1988). Evaluation of five different cochlear implant designs: Audiologic assessment and predictors of performance. Laryngoscope, 98(1), 1100-1106.
Varney, N.R. & Damasio, H. (1986). CT scan correlates of sound recognition defect in aphasia. Cortex, 22, 483-486.
Varney, N.R. (1980). Sound recognition in relation to aural language comprehension in aphasic patients. Journal of Neurology, Neurosurgery and Psychiatry, 43, 71-5.

