
 From the Desk of Gus Mueller
From the Desk of Gus Mueller
Have you ever stopped to think about it—a lot of good things come in bunches of three. As audiologists, I guess we should get the most excited about the ossicles, but what’s not to like about Alvin, Simon and Theodore, or ZZ Top? And really, who in the world doesn’t like a good BLT?

Gus Mueller
Sometimes, audiology articles come in groups of three too. And that’s what is happening here at 20Q. For you loyal 20Q readers, you know that in April we started off with Josh Alexander talking about the “Highs and Lows” of frequency lowering amplification. With that great launch into the frequency lowering topic, in May we followed with Susan Scollie discussing the “Ins and Outs.” Both great articles, but in general, I was a little disappointed with our roaming Question Man, as even after 40 questions, there were still things about frequency lowering amplification that hadn’t been addressed.
So I decided to give the Question Man a month off, and tackle the June 20Q project myself by sitting down with our two frequency lowering experts. Our goal was to see if among us, we could address all the remaining questions. I hope you enjoy our casual discussion—this time we didn’t even keep track of the number of questions—just talked. We tried to comment on everything we could think of, and after the Highs and Lows, and the Ins and Outs, as we end this trilogy I think we finally have . . . The Whole Shebang.
Gus Mueller, PhD
Contributing Editor
June 2013
To browse the complete collection of 20Q with Gus Mueller articles, please visit www.audiologyonline.com/20Q
20Q: Frequency Lowering - The Whole Shebang
Gus Mueller: It’s great that the two of you were willing to take some time off your hectic schedules to have this discussion. I know you were busy before, but with all the fan mail you’ve been getting regarding your recent 20Q articles (Alexander, 2013a; Scollie, 2013), you must now be totally swamped. While our 20Q readers of course would enjoy anything that the two of you write, I’m sure that one reason for all the interest is that frequency lowering is a topic that just hasn’t been written about a lot. Although the two of you covered just about everything in your 20Q articles, there are still a few more issues to discuss, so today we’re going to dig a little deeper, and hopefully when we finish we will have the “The Whole Shebang.” As you know, most of our readers are clinicians, and many of them are fitting frequency lowering on a regular basis, so I am going to try to keep us focused more or less on clinical topics.
But before we get seriously started, I have to ask something—you might recall that in one of the 20Q introductions, I referred to the two of you as the “best back-to-back since Mantle and Maris?” Were you both okay with that?
Susan Scollie: Since my 20Q article was second, I guess that would make me Maris. Who is Maris?
Mueller: Maris? Roger Maris? You don’t know Roger Maris? The home run king of the New York Yankees in the early 1960s? Susan, I’m bit surprised you haven’t heard of him as he was from Fargo, North Dakota. Didn’t you just tell me last month that Fargo was your favorite movie?
Scollie: North Dakota?
Josh Alexander: That makes me Mickey Mantle, eh? Did you know that half of the time that Mantle came up to bat he hit a home run, walked, or struck out? Let’s see how I do with what you throw at me today. Fortunately, I have a good teammate to back me up.
Mueller: Well Josh, you actually are up to the plate first, as I think we’ll start our frequency lowering discussion today by getting back to the technology itself, which was the focus of your April 20Q article. What I really want to get at is the potential advantages (or disadvantages) of one strategy versus another. That seems to be a common clinical question.
Alexander: Maybe I should briefly review the different strategies first, just in case we have readers who are new to the topic and missed our 20Q articles?
Mueller: Good idea. Go for it.

Joshua Alexander
Alexander: A useful classification system for describing the strategies that are available today, and perhaps those yet to come, has two dimensions: (1) how frequency lowering is accomplished, and (2) when it occurs. I’ll address these one at a time.
Frequency lowering is accomplished using one of two general approaches. The first is compression. With compression, the bandwidth between two points is reduced. Everything in the original input band (source region) is present in the output band (destination region), but with reduced spectral detail (and lower in frequency, of course). Analogies of a squeezing a spring come to mind. The exact relationship between the old and new frequencies will vary between manufacturers. However, of greater consequence is the frequency at which lowering begins, often called the start frequency or fmin. As mentioned in my April 20Q (Alexander, 2013a), the term ‘nonlinear frequency compression’ has been used to describe a subclass within this strategy, in which the start frequency (fmin) effectively divides the spectrum into two pieces: an uncompressed region below it and a compressed region above it. Therein, lies the advantage: you can treat one part of the spectrum (the mid to high frequencies) without affecting the other part of the spectrum (the low frequencies).
The other strategy by which frequency lowering is accomplished can be broadly classified as ‘transposition.’ With transposition, only a segment of the mid- or high-frequency spectrum is reproduced at a lower frequency. The segment selected for lowering might be a dominant spectral peak or some ‘feature’ determined by a speech-like classifier. Therefore, what is lowered depends on the characteristics of the incoming signal.
Mueller: So getting back to our original question, do you see an advantage of this approach?
Alexander: Well, with transposition, only a portion of the mid to high frequency spectrum is lowered, so one potential advantage of this strategy is that it might be able to ‘code’ a wider range of input frequencies (source region) in a lower and narrower range of output frequencies (destination region). Albeit, segments from different parts of the input spectrum might share similar, or even the same, parts of the output spectrum. Another advantage is that depending on how transposition is carried out, the low frequencies can be used to code higher frequencies without disrupting the frequency relationship between harmonics, which is very crucial to pitch and sound quality.
The other big distinction between strategies is when frequency lowering occurs. There are both compression and transposition strategies that are activated for all incoming sounds and there are those that are activated only when the processor determines that there is sufficient high frequency content (overall energy or some speech feature) in the signal. One potential advantage to having frequency lowering always activated is that disruptions and artifacts associated with switching between activation and deactivation are eliminated. With advances in signal processing, this is less likely to be a concern. An advantage of engaging frequency lowering selectively in time is that the speech segments with strong low frequency content (e.g., vowels) can be presented without artificial processing.
Mueller: What do you think Susan? Agree with Josh’s thoughts?

Susan Scollie
Scollie: The first thing I’d say is that most of what we can say right now about one technology versus the other is speculation. There’s very little actual data on which is best, or best for which types of losses. I can’t think of any published studies with head to head trials. Electroacoustically, there are very clear differences between them, with some providing much more frequency lowering of the high frequencies. All of them provide different frequency lowering strengths across the settings in the hearing aid from very mild to moderate to strong. To my mind, it doesn’t make sense to talk about these processors without considering how they are fitted, any more than we talk about hearing aid gain: both need to be appropriate for the user’s hearing loss.
Mueller: We maybe should also talk about disadvantages. Does one strategy have a greater potential for a downside?
Scollie: Some processors filter out parts of the signal at very strong settings. This is just one of the reasons to be very careful when fitting any frequency lowering strategy at strong settings – these should only be used when necessary.
Mueller: In your May 20Q (Scollie, 2013), you touched on how lowering strategies might impact listening to music, and this generated some questions from our readers, right?
Scollie: Right—one reader questioned if whether a transposer system should be used rather than frequency compression because it will maintain harmonic relationships in music? This is an interesting question that could use more exploration. Because transposers work on octaves, they are described as maintaining harmonic structure, but they may also have other effects on the music signal, such as filtering, that may be benign at mild settings but important at strong settings. I’ve had some patients enjoy music more with frequency compression than without, but have not had the opportunity for a head to head comparison across frequency lowering types for music specifically – remember that these processors were often developed with speech audibility in mind, just like cochlear implants were. We need to find what works for individuals, and this will depend not only on the technology but also on the specific settings used.
I might add, that as I watched the International Space Station astronauts land a few weeks ago, I was reflecting on the difficulty of their mission and clenching my fists in hopes that they would land safely. As audiologists, all we have to do is click a button to take these frequency lowering processors to a different setting – it isn’t rocket science.
Mueller: Be careful what you say! Josh has a patent pending related to this technology—he might have a rocket science angle in mind.
Alexander: No problem—Susan’s absolutely right, the programming software allows us to "fix" most things pretty easily. Regarding your question about a potential downside, let me first say that some 20 years after the introduction of WDRC, we are still discussing who should have fast-acting compression and who should have slow. We still have a lot to learn about frequency lowering technology.
In general, the more we manipulate (distort) the low frequencies, the more we must be watchful for negative side effects like altered vowel perception or sound quality. How much we do this will depend on the how the frequency lowering parameters are set for the individual loss. Because the relationship between harmonics is not preserved with frequency compression, either the activation of the feature must be input dependent and/or the low frequencies (especially ≤ 2000 Hz, or so) must be unaltered as with certain nonlinear frequency compression settings.
Transposition strategies generally move information to much lower frequencies than nonlinear frequency compression strategies. Even though transposition strategies have been designed to maintain harmonic spacing, because they mix the newly lowered signal with the original low frequency content they might create a peak in spectrum that either masks or mimics a low frequency formant.
While there is an obvious advantage to activating frequency lowering for segments of speech that need it the most, a potential disadvantage arises because the transposition strategy relies on the accuracy of a signal classifier, which likely decreases as the signal-to-noise ratio decreases. When there is a miss, then users might miss an important part of speech. When there is a false alarm, then it will lower noise and potentially mask the low frequency parts of speech.
Mueller: So there does seem to be potential advantages and disadvantages of both strategies, which is probably why a lot of clinicians ask about research comparing the different strategies. I know there was a poster presented at the American Auditory Society meeting last year from the Starkey research group comparing different strategies (Rodemerk, Galster, Valentine, & Fitz, 2012), but are either of you aware of independent research in this area?
Scollie: I’m not aware of any independent studies that have been published on this—we haven’t completed any in our lab. But I’m thinking that Josh has done this sort of thing.
Alexander: Other than my own study (Alexander, Lewis, Kopun, McCreery, & Stelmachowicz, 2008) that I reviewed in my April 20Q, I am not familiar with any independent studies that have compared two strategies. Recall from my 20Q discussion that the basic finding was that for mild-to-moderate losses where we could provide aided audibility out to a little more than 5000 Hz, that positive outcomes for fricative discrimination were associated with nonlinear frequency compression and negative outcomes with transposition. This was attributed to where the frequency lowering occurred. For the former, the effect of lowering was simply a reduction in the bandwidth of frication, whereas, with the latter, the effect was to lower the energy of /s/ into the range of / /, hence increasing these confusions and as well as some others. This is not to say that one strategy is better than the other, rather, the point is that when comparing outcomes from any study, we must also consider the individual’s frequency range of audibility and the frequency lowering settings as mediating factors.
Mueller: A technology question that I haven’t seen explained very well is how exactly the “lowered signal” interacts with amplitude compression. Let’s say you have your WDRC set with a 40 dB SPL kneepoint and a 2.5:1 ratio for 3000 Hz. You now “lower” (by whatever method) speech in the 6000 Hz range, and place it at 3000 Hz. Does this lowered signal receive the same compression treatment, or is it treated independently?
Scollie: With the frequency compression systems that I’ve worked with, the lowered energy moves with the rest of the aided signal, and the amplitude compression in the destination region is applied. There are some systems that let you assign extra gain to the lowered signal.
Alexander: As you say Susan, this does vary by manufacturer. For nonlinear frequency compression as implemented by Phonak and Siemens, I have not seen any evidence to suggest otherwise. That is, it appears as if the frequencies are first lowered, and then WDRC is applied as if they originated from their new frequencies. This was something we were just looking at in our lab the other day, so let me share some comparative testing with you. Figure 1 shows the output for a 65 dB SPL speech input (Verifit Male Talker, often referred to as the “Carrot Passage”) for a Phonak hearing aid with frequency lowering deactivated (green), and with two nonlinear frequency compression settings: one starting at 2000 Hz with a 2.2:1 frequency compression ratio (magenta), and another starting at 1500 Hz with a 3.2:1 frequency compression ratio (orange). No gain adjustments were made as the settings were changed. As shown, the output for the frequency compressed regions (between the start frequency and response roll-off) is essentially the same as it is without frequency lowering, which suggests that the lowered signals are being treated as if they originated at their new frequencies. This makes sense because with frequency compression there is no overlap between the lowered and the original signal.
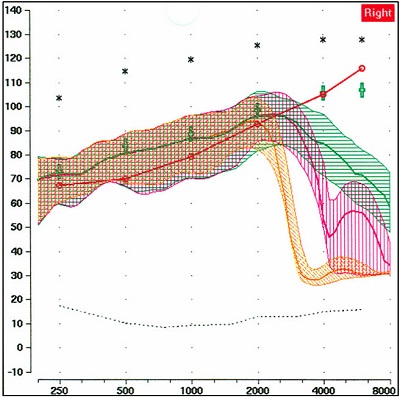
Figure 1. Example showing nonlinear frequency compression hearing aid, illustrating that frequencies are first lowered, and then WDRC is applied as if those lowered signals originated from the new destination frequencies. The upward sloping red line is the patient’s thresholds (converted to earcanal SPL). The upper black asterisks are the predicted LDLs for this patient. The green curve is the output for a 65 dB input signal with frequency lowering turned off; the green crosses are prescriptive targets. Using the same input signal and hearing aid settings, the magenta curve is with frequency lowering turned on, starting at 2000 Hz with a 2.2:1 compression ratio. The orange curve is with frequency lowering on, starting at 1500 Hz with a 3.2:1 compression ratio.
Mueller: So that example was for frequency compression. It’s different for the transposition strategies, isn’t it?
Alexander: Yes, these products allow gain for the lowered signal to be adjusted independently from the rest of the signal. One manufacturer that uses transposition has indicated that this is accomplished using separate compressors, one for the untransposed signal and one for the transposed signal, with the gain prescription of the transposed signal set according to its new frequency.
Mueller: Okay Susan, here is a question for you, since you’re the guru of DSL-Land. From what Josh was just saying, this probably only applies to frequency compression strategies, where you don’t have a separate gain adjustment for the lowered signals. Let’s say that we initially fit our patient to DSL targets through 3000 Hz, and then we plan on using frequency compression for the frequencies above 3000 Hz. After adjusting the frequency lowering compression parameters the best we can, we see from our probe-mic measures that the lowered signals are still not appropriately audible. If we could adjust the lowered signals independently, that might be a solution, but this isn’t an option. However, we could make the lowered signals audible by increasing gain for this frequency region, but then we’ve messed up our excellent match to DSL5 prescriptive targets for the frequencies originating at this region. What do we do? What has priority?
Scollie: I don’t know about the guru thing, but I can give you the steps that I’d follow. First, I’d have a look at the overall audibility in the fitting, which is different than the fit to targets. The targets are set for the average levels (or root mean square, RMS) of speech. Above that are the peaks of speech, which are about 10 to 12 dB above the average levels. Those peaks are often audible even if the targets and average levels are not. In your example, you might have audible speech peaks at 3000 Hz to even 4000 Hz. If so, you might be able to place some nicely audible “s” and “sh” cues in that 3000 to 4000 Hz region with just a little bit of frequency lowering and you might not need any more gain. If not, we can move on to the second step. You could consider using a stronger frequency lowering setting to move the high frequency cues to a portion of the frequency response that has better audibility, possibly where the targets themselves are also above threshold. I have often done this, and found that as long as I have fitted the least amount of frequency lowering needed to make “s” and “sh” audible, yet keep them separated, a successful fitting is possible. Because we want to avoid unnecessarily strong frequency lowering, it helps a lot if we maximize the high frequency audibility from the hearing aid gain and output by using a validated prescription (DSL5 or NAL-NL2), verified with probe-mic measures. If you maximize the fitting in the first place, you minimize what you need from frequency lowering. This keeps the sound quality as high as possible. As a last resort, you could fit slightly over prescribed targets with a weaker frequency lowering setting to try to provide the desired speech cues. I’d attempt this in small steps and only if I could keep track of how much over target I was fitting (again, using sequential probe-mic measures). And let’s not forget the patient—I’d also be monitoring the patient’s loudness and comfort reactions. This approach would be my last resort, but I have had a few “young-old” patients with high listening demands who prefer the loudness and clarity of the DSL5-child prescription, which is on average 7 dB higher than DSL5-adult. So, small amounts of fine tuning above a specific prescriptive target levels are sometimes a tool to have in your back pocket.
Mueller: Sound like a pretty reasonable approach to me! Since we’re on the topic of amplitude compression, let’s talk about setting the maximum power output (MPO). I would guess that audiologists out there following clinical best practice would typically measure frequency-specific loudness discomfort levels (LDLs), and then use these values to set the channel-specific AGCo kneepoints—easy to do with the many channels of AGCo available with today’s products. So would you do anything differently when you’re applying frequency lowering? For the region that was lowered? Or for the destination region? And does it depend on the lowering strategy that is applied?
Alexander: I am not sure I would do anything differently as far as setting the MPO because the ear shouldn’t care at what frequency the signal originated from, only where it is when it excites the basilar membrane.
Scollie: I regard MPO and frequency lowering as separate aspects of the hearing aid’s signal processing, so I fit the MPO with the frequency lowering turned off as part of setting the basic gain and frequency response of the fitting. Some of the processors allow you to increase the gain for the frequency lowered signal on its own, so it wouldn’t hurt to check the MPO again if a lot of adjustment had been made to this type of gain.
Alexander: Seems to me that you should still be okay for those strategies that mix the lowered and original signals. At least this should be true if both signals share the same AGCo. If there were separate AGCo’s (but with the same settings), then, due to summation effects we risk having a signal that is greater than we think we do and we would adjust accordingly, but I have not seen anything like this put out by the manufacturers.
Mueller: True. If you’re using AGCo to limit output, as we usually do, it shouldn’t matter even if you increase gain for the lowered signal, as that won’t impact the MPO. But you do get some funky-looking MPO curves when frequency lowering is applied, right?
Scollie: Most certainly. The problem is that we usually use a swept pure-tone for this analysis, and our hearing aid analyzers are designed to present and measure at the same frequency (usually 1/3 octave wide), so MPO measurements of a frequency-lowered signal can “miss” the aided output that is happening further down the frequency axis. This is a measurement problem that could use some attention. As more and more companies release these processors, I hope we will see more measurement standardization.
Alexander: As Susan is saying, because of the way the analysis is designed, the farther the test frequency is from the start frequency, the greater the mismatch and the lower the output. I ran a real example of this in our lab, which is shown in Figure 2. Here, you can clearly see how the MPO curves with frequency lowering activated (blue and orange) begin to deviate from the MPO curve that was obtained when the frequency lowering algorithm was deactivated (magenta). In fact, this is an easy objective test to find the approximate start frequency of lowering, or simply to verify that things are working as you expected.
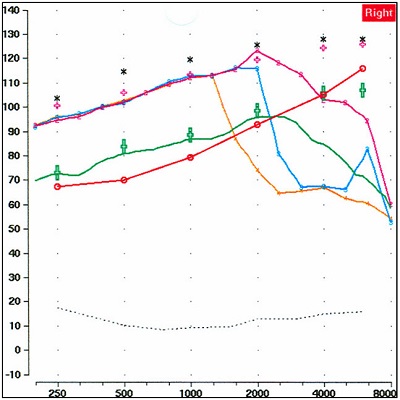
Figure 2. Example illustrating that the farther the test frequency is from the start frequency, the greater the mismatch and the greater tyhe impact on the MPO measurement. The lower red line is the patient’s thresholds (converted to earcanal SPL). The green curve is the output for a 65 dB input signal—the green crosses are prescriptive targets. The upper black asterisks are the predicted LDLs for this patient; the pink crosses just below represent the patient’s measured LDLs (typically considered the upper boundary for the MPO). The magenta curve is the MPO obtained for an 85 dB SPL swept tone with frequency lowering turned off. The blue curve shows the measured MPO for the 85 dB signal when the lowering was activated at a kneepoint of ~2500 Hz, and the orange curve shows the measured MPO for a lower kneepoint.
Mueller: And of course, we would assume that some aided behavioral loudness measures would also be conducted, which would alert us to any unforeseen problems with the MPO settings. I want to change the topic a little and talk about candidacy. I know that both of you addressed this in your 20Q articles, and I think you more or less agreed, from an audiometric standpoint, when frequency lowering might be implemented. But I want to get a bit more specific—let’s limit our discussion to the 3000-4000 Hz range, as these frequencies are the ones that generate the most clinical questions. In a typical downward sloping hearing loss, it seems to me that we would only apply frequency lowering for the 3000-4000 Hz region if we are unable to obtain acceptable audibility with traditional amplification. Yet, I know some clinicians routinely apply frequency lowering to these frequencies when the hearing loss is only 65-75 dB HL. What are your thoughts?
Alexander: So what you’re asking is, why use lowering in place of amplification? Because lowering entails intentionally limiting the bandwidth of amplification, we should first question the clinician’s motive for doing this. I can think of two: 1) concerns about reducing speech intelligibility by amplifying a dead region, and 2) attempts to avoid feedback. If the clinician has legitimate concerns about dead regions, then I will reiterate a point I made in my April 20Q after I reviewed conflicting data on the matter, “based on the information available (or lack thereof), you should not use the possibility of a dead region as an excuse to implement frequency lowering in a way that limits the audible bandwidth you give to your patient.” The use of frequency lowering to avoid feedback is, at minimum, a lazy practice because it increases the risk of decreasing speech intelligibility (remember from our previous discussion that there is a give and take associated with the use of frequency lowering). There are much better ways to handle feedback issues.
Scollie: I have some thoughts on this topic too. As I discussed in my 20Q, whether the fitting “needs” frequency lowering not only depends on the hearing loss, but also on other aspects of the fitting. If the prescriptive formula, fine tuning, or plumbing hold the fitting back from providing high frequency audibility, then frequency lowering may have a role where it otherwise wouldn’t. The problem there is that the more we use frequency lowering as a Band-Aid, the stronger the settings we’ll invoke. Stronger-than-necessary settings lead to poorer sound quality. The best starting place is a traditional, comfortable but broadband hearing aid fitting, fine-tuned in the ear for speech inputs, with frequency lowering off. Once that’s done, you can evaluate whether there is any further high frequency cues to be gained. If there’s nothing to gain by activating frequency lowering, then you don’t need it.
Mueller: Sounds simple, but you make an important point Susan—if you start off with inappropriate audibility with your fitting, the frequency–lowered signals will have inappropriate audibility too. And, of course we know you can’t just push a magic button in the software and assume things are okay. I’m reminded of the work of Aazh, Moore and Prasher (2012) who showed that with at least one manufacturer, even when you selected the NAL fitting algorithm in the software, you were still 10 dB or more below NAL targets in the real ear in over 70% of the fittings. And speaking of fitting to prescriptive targets, here’s a question for you two regarding frequency lowering for new hearing aid users. Should we fit them with frequency lowering on day one, or should we allow them to first acclimatize to the amplification provided by the NAL or DSL prescription (for a month or so) and then introduce frequency lowering? It seems to me, if you believe it works, why wait?
Scollie: The jury is pretty much unavailable on that one. The only acclimatization studies I’ve seen have been on kids, and have used both strategies. I’ve seen some adults perceive the hearing aids as less loud when frequency lowering is used, so from that point of view you could fit it right away and it might help them accept the new hearing aids. Others seem to believe that adults have a hard time accepting the sound quality of frequency lowering. I know I keep bringing this up, but I’ll go back to setting the strength of the lowering: excessively strong frequency lowering can cause sound quality problems. I like to keep the frequency lowered band confined to just the high frequencies if possible, which protects the formant structure of the vowels and minimizes negative sound quality effects. Not all fitting strategies are designed that way.
Alexander: As Susan says, the jury probably is still unavailable, but here are my thoughts. Many things are going to sound different for a new hearing aid user, so why not try to get them used to the technology on day one if this is your final plan? If they are having trouble acclimating, then you can always decrease the amount of lowering and/or deactivate it to see if this is the cause of their problems. I’m assuming that prudent audiologists have used the objective verification techniques we have described in our previous 20Q articles; if not, then maybe you shouldn’t be fitting this technology in the first place since you run a real risk of making speech understanding worse.
Mueller: Let’s keep going with the frequency lowering candidacy thing. How about the need for the same technology on both ears? There certainly are times when a regular user of bilateral amplification only needs one of his two hearing aids replaced. The two of you weren’t fitting hearing aids in the early 1990s, but a common question then was if it was okay to fit WDRC to one ear if the patient was using linear in the other? And then, ten years later we heard the question: Is it okay to fit digital to one ear if the patient is using analog in the other? You can see where I’m going with this—is it okay to fit frequency lowering to one ear, when the patient doesn’t have this technology in the other? We’ll assume the patient has a symmetrical hearing loss. My thought is, no problem, as somehow the brain will find the most useful information from the two ears. What are your thoughts?
Alexander: I don’t recommend it, but I have to admit that I haven’t tried it. I imagine that having the same sound generate different percepts in between ears would be weird and distracting at the least. If the frequency lowering setting in the one ear was mild (e.g., nonlinear frequency compression with a high start frequency), then maybe it wouldn’t be too noticeable for broadband signals.
Mueller: Josh, you say “having the same sound generate different percepts.” I guess things maybe would sound different at the destination frequencies of the lowered signals, but as far as the signals that were being lowered—if they had been audible in the first place we wouldn’t have lowered them. So to my way of thinking, it isn’t like the /s/ would sound different in one ear versus the other, it would just be audible in one ear (albeit at a new frequency) and inaudible in the other. Your opinion on this, Susan?
Scollie: I’m not a big fan of bilaterally asymmetric frequency-lowering fittings. Too much of the binaural system relies on a frequency match between the inputs to the two ears. I’d avoid that type of fitting if possible.
Mueller: Okay, so it sounds like I’m out-voted, but I haven’t changed my mind and I’m going to keep after this topic just the same. Your answer Susan, then leads to a different but related issue. Let’s take a patient who has a precipitous downward sloping hearing loss in both ears. In the right ear, the loss drops to 50 dB at 1500 Hz, and >80 dB at 2000 Hz and above. In the left ear, the hearing is a little better and the loss doesn’t drop to 50 dB until 2000 Hz, and is then >90 dB at 3000 Hz and above. Now if you’re an audiologist who is fond of frequency lowering, you’d apply this technology for both ears. I’m pretty certain that the software from most manufacturers would recommend different lowering parameters for these two different ears—which intuitively would make sense, as you would think you’d need more aggressive lowering for the right ear. However, this would result in a high frequency speech sound like the /s/ being heard at a different frequency in the right ear than in the left. So if I understand you correctly Susan, to maintain symmetry of the lowered signals, you would pick some compromise setting of the lowering parameters and set both hearing aids the same, so that the lowered signals are at the same frequency in both ears?
Scollie: Actually, some of the software systems link the frequency lowering strength between ears to force symmetrical frequency lowering between the two ears. I did have a patient with the type of hearing loss that you mention, who we had originally fitted with frequency lowering set according to the better ear. After a period of successful use, he requested a trial with a stronger setting for the poorer side, in order to hear well from both ears. This is possible in programming of course, but may not be available in the default settings. We sent him out with that stronger setting on a trial basis and he had no major complaints, but it would be nice to see some hard data on this question. It comes up a lot.
Mueller: Related to the downward sloping hearing loss configuration I was just talking about, many people who are candidates for frequency lowering have fairly normal hearing in the lows, and are good candidates for open canal (OC) fittings. I’ve heard some say, however, that we maybe shouldn’t use frequency lowering with OC fittings. I’m not sure of the reasoning behind this caution. Something to do with summation effects or sound quality, because maybe the amplified lowered signals are mixing with the direct signals? It seems unlikely to me that there would be a significant interaction between these signals—Todd Ricketts and I looked at this several years back when OC fittings were just becoming popular and it was pretty much a non-issue, simply because of the cut-off frequencies for direct versus amplified sounds (Mueller and Ricketts, 2006). But maybe I’m missing something here.
Scollie: I tend to agree with you, Gus. The direct sound path exists below 1500 Hz. For most of the commercially available products on the market, the frequency lowering only starts at that frequency and does not go below that (this applies to Phonak, Unitron, Siemens, and Starkey) so mixing is a non-issue. For the Widex processor, it is possible to lower sound to below 1500 Hz . . . so some combined effect is theoretically possible. But even with this product, the lowered sound would only be triggered by a peak in the energy above 1500 Hz, so the lowered cues would be at different points in time and simultaneous mixing should not be a big issue.
Mueller: Maybe the lowering algorithm causes a significantly greater group delay, and this is then noticeable with an OC fitting? Seems unlikely, but . . . I’m searching for a reason. For you readers who haven’t thought about this, here is the potential problem. If the digital processing time of all the hearing aid features (e.g., compression, noise reduction, feedback suppression, etc., referred to as group delay) is too long, there will be a noticeable delay to the user when the amplified signal is compared to the direct sound of either their own voice (heard by bone conduction) or sound going directly to the ear, most noticeable in the case of an OC fitting. We don’t hear much about group delay anymore, as the delays in today’s technology are pretty small—research suggests that there probably is no need to worry about delays that are smaller than 10 msec. But—I haven’t thought much about the potential digital processing delays caused by frequency lowering.
Alexander: Well Gus, I hadn’t either, but you told me to come to this discussion table armed with information, so this is one of the things we recently looked at. We used hearing aids from five leading manufacturers who have frequency lowering as an option, and programmed the hearing aids for a downward sloping loss that most would consider a candidate for use of frequency lowering. All program features were set to their default setting, except the frequency lowering option, which was first deactivated (“FL Off”) and then activated (“FL On”) at the manufacturer’s default setting or at a setting in the middle of the available range. We then measured group delay using the Frye Fonix 7000. Figure 3 compares group delay with the frequency lowering feature deactivated (blue bars) and activated (red bars). The hearing aids are rank ordered from greatest to least in terms of group delay and I arbitrarily assigned the labels “A” through “E.” As can be seen, there was a fairly large difference in the group delays of the different instruments, but only a minor increase in group delay was associated with the activation of frequency lowering for hearing aid D. And interestingly, hearing aid C showed a repeatable decrease in group delay of about 1 msec when frequency lowering was activated.
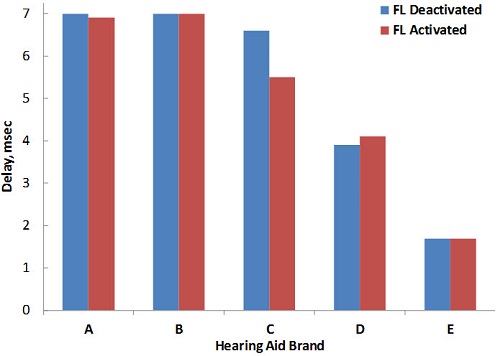
Figure 3. Measurement of group delay (msec) for five instruments from different manufacturers employing frequency lowering. Using the Frye Fonix 7000, delay was measured with frequency lowering deactivated (blue bars) and activated (red bars).
Mueller: So, the bottom line is that the group delays from all manufacturers are quite small (or at least small enough), and frequency lowering didn’t have a significant impact. Good. That leaves us with no compelling reason not to utilize frequency lowering with OC fittings, which is also good, as a lot of the frequency lowering candidates would be best fitted with an open configuration. We’ve talked about the audiogram and the hearing aid plumbing, but usually the main reason we’re fitting this technology is to help people understand speech better. What about some kind of speech testing to help determine who is a good candidate? I know that there are some special lists of the QuickSIN to help determine if a patient can make use of high frequencies. You probably recall that Robyn Cox and colleagues (2011) used that approach in the study of cochlear dead regions a couple years ago. Do you think some speech test like this would be valuable?
Scollie: As you mention, the QuickSIN does provides high frequency emphasis sentence lists, either up to 3000 Hz, or with a full bandwidth. They were designed to be used unaided, when the clinician is concerned that the testing is invalidated by audibility limitations imposed by a steeply sloping audiogram (this is why they are called “Guilt-Free” lists in the test manual). It is tempting to test with these high frequency lists versus the regular ones to see if the patient can derive benefit from the audibility. This is an interesting idea that could use further investigation to see if it works.
Alexander: I agree. That type of testing couldn’t hurt. Research that could link performance on these sorts of tests with frequency lowering outcomes would be welcome. But here’s something to think about: candidacy recommendations for directional microphones based on QuickSIN performance have been around for years, but how often is this really performed in the clinic relative to how often directional microphone technology is dispensed? In other words, even though we might find a relationship between speech testing and outcomes, clinicians would still need to be convinced of the value of such testing. But, this is another problem for another day.
Mueller: Yes, and a long day at that, I might add. Let’s move on to clinical verification. Susan, I know you gave some examples of how probe-mic measures can be used, and I want to get to that in a moment. The problem of course, related to hearing aid verification in general, is that 30% or so of those fitting hearing aids don’t have access to probe-mic equipment. A sad statistic, but true. Back in the 1970s, before the days of probe-mic, we actually conducted soundfield unaided and aided testing for hearing aid verification—something called “functional gain”. Could we dust this off and use such a measure to obtain a rough idea if the frequency lowering was performing adequately? I know there are a lot of reliability issues with this measure, but would it be better than no real ear testing at all?
Scollie: Looking at aided versus unaided detection for high frequency sounds might be one way to see if a frequency lowering scheme is providing better detection outcomes. But let’s zoom in on what you’d need to do: if you want to test for the benefits of frequency lowering, you’d have to test high frequency thresholds for unaided signals, and then without and with frequency lowering. That’s three thresholds. If you aren’t sure which frequency lowering setting to try, you might have to test several possible settings. Josh’s online tool offers up to three. That could mean testing thresholds for up to five different settings just to find one to fit. This seems like a lot of test time to spend on a measurement that can’t tell you about supra-threshold speech recognition, sound quality, loudness, comfort, or speech sound confusions. I’d still rather fit with electroacoustic measures and use aided behavioral tests as a post-fitting validation measurement rather than as a fine tuning tool.
Mueller: When you say “electroacoustic measures,” you’re assuming that these people who don’t have probe-mic systems do have 2-cc coupler testing capabilities? And if so, how exactly would you use coupler measures to determine that you’ve provided the correct amount of lowering?
Scollie: Sorry for the confusion. I was lumping both probe-mic measures and 2-cc measures together with the term “electroacoustic”. That’s just the pediatric audiologist in me coming out, because sometimes we fine tune on the coupler with predictions to the real ear using the real-ear to coupler difference (RECD). My point was that fine tuning with verification is the most efficient and informative choice for setting frequency lowering, compared to behavioral methods.
Alexander: Gus, regarding you initial question about the use of aided soundfield testing, I’m going to have to take the high road on this one. I think that advanced hearing aid features, especially frequency lowering, only increase the necessity of probe-mic measures.
Mueller: I’m all about the high road too, but here’s another depressing statistic that I didn’t mention. We know that roughly 30% of audiologists fitting hearing aids don’t own or have access to probe-mic equipment, but even more striking is that only 58% of audiologists who have the equipment, use it routinely (Mueller and Picou, 2010). Now, if audiologists who have a probe system sitting next to them in the fitting room are not keen to use this verification tool for something as basic as observing if soft speech has been made audible, can we really expect them to use it for assessing frequency lowering?
Alexander: Absolutely. If you are charging people for this feature, it would be unethical to let them walk out the door without verifying that it’s adjusted appropriately. It’s what we do. And, here’s an example of why soundfield measures wouldn’t be a good alternative. Consider that one of the most important things to ascertain when fitting a hearing aid with frequency lowering is that the bandwidth of amplification within the aidable region (that part of the spectrum that we can make audible) is not restricted by the activation of the feature. I have argued that the greatest likelihood of benefit and the least likelihood of harm for speech recognition both occur when the user’s aidable bandwidth is fully utilized (Alexander, 2013b). The only way to know this is via probe-mic measures. In other words, you need to know the levels of the frequencies outputted by the receiver. Soundfield testing will only tell you if the frequencies inputted by the microphone are detected (i.e., moved into the aidable region), but not at which frequencies they are detected. Here’s an example. Let’s say that we can make frequencies up to 3000 Hz audible without frequency lowering, but you then unknowingly select a frequency lowering setting that rolls off the frequency response of the output at 2000 Hz. Let’s go back to Figure 1—the responses shown in green and orange, respectively, closely approximate such a scenario. With this frequency lowering setting, you probably will be able to obtain reasonably good aided soundfield thresholds at 3000 Hz and probably even up to 6000 Hz, but only because the hearing aid has lowered them. You will have no idea that you killed the response of the hearing aid above 2000 Hz. It shouldn’t take much convincing that we could have done a lot with that 1000 Hz band that was just thrown away.
Mueller: I’m convinced—I wasn’t even a fan of aided soundfield testing when it was popular in the 1970s! We talked about the use of speech audiometry as perhaps a “pre-fitting test,” but obviously speech testing would be another possible verification (validation) tool. I know Susan, you talked about the Plural’s Test in your 20Q article, and I believe that others have used the “S-Test.” What are your general thoughts about using some speech test for verification on the day of the fitting? Are these tests really sensitive enough to be of assistance in hearing aid adjustments?
Scollie: I think this confuses the steps of verification and validation. Verification is the stage where we fine tune and adjust the hearing aid. We use electroacoustic hearing aid analysis at this stage: it is precise, repeatable, and lets us see fine-scaled changes in the hearing aid response for specific test levels. Validation measures using behavioral responses have poorer test-retest reliability and are typically less sensitive to small changes in hearing aid settings.
Alexander: I agree and would like to expand a little on what Susan just said. I think that if you first use objective methods (e.g., probe-mic measurements and my online frequency lowering fitting assistant tools) to reduce the number of settings you plan to use for frequency lowering to two or three, then the use of formal or informal speech assessments to make the final selection is defensible. Considering that manufacturers provide the clinician with anywhere from 7-15 different settings that control what is lowered and where it is lowered, exclusive reliance on such speech assessments draws concerns about 1.)Feasibility: How much time will it take to conduct speech testing with such a large number of settings?; 2.)Sensitivity: How many trials will be needed to reliably tell the difference between pairs of settings?; and 3.)Validity: How do we know that the best setting for detecting /s/ and /z/ will not have negative consequences for discriminating between certain sets of vowels or between /s/ and / /?
Mueller: Related to the use of these specialized speech tests, I’d like to get back to something you talked about in your 20Q article, Susan. Let’s say an adult patient shows a significant benefit on the Plurals Test. Do we really know that this will have any impact on his everyday speech communication? I’ve heard some skeptics say that the results from these “special” speech tests really don’t matter much. Should we also be doing some type of speech test that has more real-world face validity? Something like the Connected Speech Test (CST), perhaps?
Scollie: Certainly speech measures that simulate real world conversations in both quiet and noise do have higher face validity and for that reason are better indicators of performance. However, with today’s technology, we have the opportunity to use either extended bandwidth fittings or frequency lowering to make sure that all of the phonemes in speech are available to the user. Nabbing those last few pesky high frequency speech sounds is a subtle increment in aided hearing capacity that may or may not show up on more global measures of performance. However, let’s turn the question on its ear: is there a reason to withhold certain phonemes? If we know from electroacoustic analysis that we are missing sounds like the /s/, / /, /f/ and /th/, should we just leave it at that? There are only 19% of the consonants in my favorite nonsense syllable test. That means that someone could score 0% for these sounds without frequency lowering and 100% for these sounds with it, but their overall score change will be small and may not be significant. It’s important to have both global and focused tests in a test battery aimed at frequency lowering (or bandwidth) evaluations so that we see the effects of the technology both with big-picture tests and with tests that may be sensitive to the effects of interest.
Alexander: I’m probably not as positive about these tests as Susan, and can be counted among the skeptics. Consider the study that Gus alluded to earlier, which compared frequency lowering from three manufacturers using the “S-Test.” At a pragmatic level, speech recognition depends on more than just detection; the ability to discriminate the difference between sounds is obviously crucial for effective communication.
Mueller: I recall that you and I talked about this at a meeting of the American Auditory Society a year or so ago—over a beverage I think. You had just finished some research related to this?
Alexander: Right—in fact I presented those findings at that meeting (Alexander, 2012). This was a study using nonlinear frequency compression in which I fixed the maximum frequency of nonsense speech stimuli after frequency lowering at one of two frequencies (around 3300 and 5000 Hz). For each of the two bandwidths, I systematically permutated the start frequency and compression ratio to create six different frequency lowering conditions. The point of the study was to find out what parameters worked best for each bandwidth of aided audibility. I tested consonants in a vowel-consonant-vowel context, vowels in an h-vowel-d context, and fricatives/affricates in a vowel-consonant context. Interestingly, I found out that the settings that tended to work best for fricatives and affricates (/s/, by the way, is a fricative) happened to be the same settings that made recognition of vowels and other consonants worse. In other words, if the entire basis for selecting the setting for frequency lowering is perception of /s/, then this could cause more harm than good when the entire inventory of phonemes is considered.
Mueller: Ok, let's get back to the probe-mic verification of frequency lowering. The Audioscan Verifit has special filtered LTASS (long term average speech spectrum) signals that help us determine if our lowering is adjusted correctly, but these seem to be somewhat softer than the level of these signals in normal conversation. So when using these signals, do we still want the lowered spectrum to exceed the patient’s threshold, or would that maybe be too much audibility?
Scollie: I definitely keep the differences between test signals in mind when interpreting a fitting result. With the Verifit test signals, you get a more conservative picture of high frequency audibility, so people can do a lot with just a little bit. If I am verifying with a true fricative, I expect to see more audibility because it is higher in level and broader in bandwidth. I also expect those measures to be more predictive of the listener’s perception of those same phonemes.
Mueller: I know one alternative, which would be an option with most any probe-mic system, is to use live voice to produce sounds such as the /s/ and /sh/. Using live voice always sounds risky to me. Anything clinicians need to think about if they use that approach? Approximately what overall SPL level would best represent the same sound in average speech?
Scollie: Using live voice speech is something that I discussed in my May 20Q paper, and I even showed how the real-ear output might look. This option has some strengths and some weaknesses, with the main weakness being that the level is not calibrated. In our lab test equipment, we extract calibrated /s/ and /sh/ from a train of syllables and are working on validation studies with this approach and simple pre-recorded /s/ and /sh/ signals. Some systems already offer stored calibrated fricatives for use as test signals. In the long run, I’d like to see development of better and more widely available solutions than what we have now. In the short run, it is possible to get a frequency lowering fitting into the ballpark using the verification strategies I discussed in my 20Q, and these can be used in combination with Josh’s various fitting assistants (he has one for each of several specific frequency lowering processors).
Alexander: Interestingly, several years ago when I was at the Boys Town Research Hospital, we developed recorded versions of /s/ and / / to be played through the Verifit. We found that isolated reproductions of these sounds were too short to analyze, so we lengthened them. But, this did not go very far because of the extra steps necessary to ensure proper calibration and because, unless we modified them a certain way, the noise reduction algorithms of the hearing aids tested tended to reduce the amplification of these steady state, noise-like signals.
Mueller: That’s an important point for clinicians to remember—a prolonged / / will likely sound like noise to the hearing aid, and adjustments of frequency lowering normally are conducted with digital noise reduction “on.” While we all clearly favor the objective probe-mic fitting approach, it seems like it would be important to obtain information from the patient too. After all, “How does it sound?” just might be the most popular hearing aid verification tool in the U.S. Susan, I know you jokingly mentioned “Sally sells sea shells by the seashore” in your 20Q article, but I noticed the folks at the NAL did indeed use this very phrase in one of their frequency lowering research projects. What should we be looking for from the patient—do you find that patients are pretty good at identifying when the signals are lowered too much or too little?
Scollie: I think it just depends on the patient. We’ve had reactions all the way from not noticing that it is on, to being very accurate and responsive in providing feedback about the frequency lowered signal. This is the reason why I believe we need good electroacoustic tools to help us fit and fine tune to a good place – we are not all the way there yet but if the person you are fitting can’t tell you if it is okay, an electroacoustic test of the frequency lowering will certainly get the fitting into the ballpark. Hey, after two hours of talking, we’re back to Roger Maris again!
Alexander: I think it’s pretty risky to rely on the patient’s comments. I remember a few years ago when I had just developed my first frequency lowering fitting assistant, the clinical audiologists I worked with brought back the patients they had fit with the default frequency lowering setting. In many cases, frequency lowering set by the default was out of the audibility range of the patient and in a few cases the frequency lowering setting was too strong and restricted the audible bandwidth by at least 1000 Hz. For the former, patients failed to mention that the ‘new feature that was supposed to help them better understand high frequency sounds’ did not offer benefit compared to their old hearing aids. No complaints were lobbied by the latter group either. Anecdotally, listeners immediately preferred the new settings recommended by the fitting assistant.
Mueller: Sticking with the topic of patient comments—I’ve heard clinicians say that their patients report that frequency lowering helps them enjoy the environment—it sounds fuller, they hear different sounds they hadn’t heard, etc. Of course, this could be just a placebo effect if the clinician set them up. Would either of you ever implement frequency lowering for just the upper range, say 6000 Hz and above, maybe in a second program, for this purpose?
Scollie: In the Glista et al. (2009) trial, we had one patient who missed hearing the sounds of crickets and other sounds of nature while hiking. He used a strong frequency lowering program for daily use, and the same settings that he preferred for speech were also sufficient for hearing crickets again. He was pretty happy about this. In that case, we didn’t need to create a special program.
Mueller: And of course, an added benefit is that now he could predict the temperature simply by listening to cricket chirps (Mueller, 2010).
Scollie: What?
Mueller: Sorry, go on . . .
Scollie: In terms of only using frequency lowering for just the very high frequencies, such as 4000 Hz and up or 6000 Hz and up, you certainly can do that and might get a very subtle sound quality change. I’ve not tested a 6000 Hz and up fitting, but on blinded sound quality evaluations, we see sound quality changes for settings as mild as 4000 Hz and up (see Parsa, Scollie, Glista, & Seelisch, 2013). I recently did a bilateral mild fitting with an open slim tube and activated frequency lowering at just the high frequencies to compensate for the slim tube roll-off. The user preferred to have it on because speech sounded clearer. That said, I had another open fitting recently which was monaural as the other ear was normal. In that case, the user didn’t prefer it to be active. He may have been noticing the frequency mismatch between ears. I turned it off.
Mueller: Since we don’t have very good tools to determine who are good candidates for frequency lowering, it’s reasonable to assume that despite our best fitting and verification techniques, there will be times when it simply does no good. Do you ever just “give up” and turn it off? If so, how long should we wait? Weeks? Months?
Scollie: So assuming you’d leave it on for a trial period, how long should you wait? Our data have shown up to 6 to 8 weeks in older kids who were already hearing aid users (Glista, Scollie, & Sulkers, 2012). I’ve not seen any published acclimatization data in adults, but I would think it would be similar.
Mueller: If you know it’s not doing any harm, then I guess it doesn’t matter much if you leave it on. Although—if this algorithm is unnecessarily continuously running, does that reduce battery life? Josh, I know you were locked in your lab for days testing these instruments—let me guess, battery drain is one of the things you measured?
Alexander: Right you are. We leave no stone unturned at Purdue! Using the same five hearing aids that we had used for the group delay measures, we examined battery drain with frequency lowering on versus off. With one exception, no significant changes in battery drain were associated with activation of the frequency lowering feature. There was no difference for two hearing aids, a small increase for one, and a small decrease for another. One product did show a difference that could be considered significant—battery drain increased by about 10%. In other words, if you normally would have 10 days of use from the battery with frequency lowering deactivated, you would only get about 9 days with it activated. Over the course of a year, this translates into about 4 extra batteries/hearing aid—probably not something to be too concerned about.
Mueller: You know, this sure is fun and it could go on forever, but our readers have probably had enough—if they even made it this far! How about a big ending? There doesn’t seem to be many studies with frequency lowering that have looked at real-world benefit. I know at the recent meeting of the American Auditory Society, Ruth Bentler presented data from a large three-site study (Bentler, Walker, McCreery, Arenas, & Rousch, 2013). The findings weren’t especially exciting. What are your thoughts on that research, and other studies examining real-world benefit? Either one of you want to jump in here?
Alexander: I have three thoughts about the results from the study you mention, which looked at many more variables than just frequency lowering. The first is that on average, they found no difference in outcome measures between those fit with nonlinear frequency compression and those fit with conventional processing. So, while the mean results did not show overall benefit, they did not show that it hurt outcomes either – agreed, not a very enthusiastic vote of confidence. Which brings me to my second thought: averages being what they are, there must have been a subset of subjects (how large I don’t know) who had better outcomes with frequency lowering compared to those without and another subset who had worse outcomes. This was a nonintervention, between-subjects design, so we really don’t know how each individual would have performed with the alternative processing. What I would want to know is what makes one group different from the other. I believe that they looked at a bunch of predictor variables but found no significant relationships. This brings me to my third thought. Perhaps, the difference between groups was in terms of the frequency lowering settings and/or the method by which they were chosen for each individual. Again, this being a nonintervention study, there were likely different approaches to selecting the final frequency lowering setting for each individual that varied by site and by audiologist. There are several possible explanations for individual variability in outcomes with frequency lowering (Alexander, 2013a). I hypothesize that one of the biggest sources of variability is how the frequency lowering settings interact with the individual hearing loss. I think that we can all agree that much research remains to be done on this topic.
Scollie: You certainly have my agreement.
Mueller: And me too. And with all that agreement, it just might be time to bring our little discussion to a close. Susan and Josh, thanks for doing your 20Q articles, and agreeing to provide even more of your insights for this final article of the trilogy. I think we now have—The Whole Shebang.
References
Aazh, H., Moore, B. J. C., & Prasher, D. (2012). The accuracy of matching target insertion gains with open-fit hearing aids. American Journal of Audiology, 21(2), 175-180.
Alexander, J. M. (2012, March). Nonlinear frequency compression: balancing start frequency and compression ratio. Presented at the annual meeting of the American Auditory Society, Scottsdale, AZ.
Alexander, J. M. (2013a, April). 20Q: The Highs and lows of frequency lowering amplification. AudiologyOnline, Article 11772. Retrieved from: https://www.audiologyonline.com/
Alexander, J. M. (2013b). Individual variability in recognition of frequency-lowered speech. Seminars in Hearing, 34(2), 86-109.
Alexander, J. M., Lewis, D. E., Kopun, J. G., McCreery, R. W., & Stelmachowicz, P. G. (2008, August). Effects of frequency lowering in wearable devices on fricative and affricate perception. Presented at the International Hearing Aid Conference, Lake Tahoe, CA.
Bentler, R., Walker, E., McCreery, R., Arenas, R., & Roush, P. (2013, March). Frequency compression hearing aids: impact on speech and language development. Presented at the annual meeting of the American Auditory Society, Scottsdale, AZ.
Cox, R. M., Alexander, G. C., Johnson, J., & Rivera, I. (2011). Cochlear dead regions in typical hearing aid candidates: prevalence and implications for use of high-frequency speech cues. Ear and Hearing, 32(3), 339-348.
Glista, D., Scollie, S., & Sulkers, J. (2012). Perceptual acclimatization post nonlinear frequency compression hearing aid fitting in older children. Journal of Speech, Language, and Hearing Research, 55(6), 1765-1787. Doi: 10.1044/1092-4388(2012/11-0163)
Glista, D., Scollie, S., Bagatto, M., Seewald, R., Parsa, V., & Johnson, A. (2009). Evaluation of nonlinear frequency compression: Clinical outcomes. International Journal of Audiology, 48(9), 632-644.
Mueller, H. G., & Ricketts T. (2006). Open-canal fittings: Ten take-home tips. Hearing Journal, 59(11), 24-39.
Mueller, H. G. (2010). Crickets, audibility and verification of hearing aid performance. ENT and Audiology News, 19(3), 84-87.
Mueller, H. G., & Picou, E. M. (2010). Survey examines popularity of real-ear probe-microphone measures. The Hearing Journal, 63(3), 27-32.
Parsa, V., Scollie, S., Glista, D., & Seelisch, A. (2013). Nonlinear frequency compression: effects on sound quality ratings of speech and music. Trends in Amplification, 17, 54-68. doi:10.1177/1084713813480856
Rodemerk, K., Galster, J., Valentine, S., & Fitz, K. (2012, March). Detection of word final /s/ and /z/ with three modern frequency lowering technologies. Presented at the annual meeting of the American Auditory Society, Scottsdale, AZ.
Scollie, S. (2013, May). 20Q: The Ins and outs of frequency lowering amplification. AudiologyOnline, Article 11863. Retrieved from: https://www.audiologyonline.com/
Cite this content as:
Mueller, H.G., Alexander, J.M., & Scollie, S. (2013, June). 20Q: Frequency lowering - the whole shebang. AudiologyOnline, Article 11913. Retrieved from https://www.audiologyonline.com/



