
From the Desk of Gus Mueller
![]() What’s the connection between the work of Colin Cherry and Don Jewett? Don’t shout out your answer right away, as some of our younger readers might be saying . . . who the heck are Colin Cherry and Don Jewett?—so let’s start there.
What’s the connection between the work of Colin Cherry and Don Jewett? Don’t shout out your answer right away, as some of our younger readers might be saying . . . who the heck are Colin Cherry and Don Jewett?—so let’s start there.
Edward Colin Cherry was a British cognitive scientist whose main contributions were in focused auditory attention. Specifically, in 1953 he was the first to define and name “the cocktail party problem.” The particular party problem he defined is indeed audiologic, and relates to our ability to follow a conversation when multiple talkers and background noise is present. The research interest at the time was not so much related to cocktail parties, but the problems faced by air-traffic controllers, who in their work setting, would hear the voices of several pilots simultaneously from a single loudspeaker in the control tower.
 If we then jump forward 17 years, we have the classic papers of Don Jewett and colleagues, defining what we now call the auditory brainstem response (ABR). These papers introduced us to an amazingly efficient way to assess the neural integrity of the brainstem. The ABR quickly became the go-to diagnostic test for audiologists, with the waveforms affectionately called “Jewett Bumps.”
If we then jump forward 17 years, we have the classic papers of Don Jewett and colleagues, defining what we now call the auditory brainstem response (ABR). These papers introduced us to an amazingly efficient way to assess the neural integrity of the brainstem. The ABR quickly became the go-to diagnostic test for audiologists, with the waveforms affectionately called “Jewett Bumps.”
So we have a fellow named Cherry, a cocktail party, struggling air-traffic controllers and “bumps.” You know we must be going to a good place! We are, and the person taking us there is our guest author this month, Dr. Nina Kraus. She will talk about some fascinating research that she is involved with regarding why some people do better than others understanding speech in background noise, and how we can objectively assess this difference with electrophysical measures such as the cABR. That’s of course the Cherry-Jewett connection.
Nina Kraus, PhD, is Professor of Neurobiology & Physiology, Otolaryngology, Hugh Knowles Chair, and the Director of the Auditory Neurosciences Laboratory at the Department of Communication Sciences and Disorders, Northwestern University. Dr Kraus’s research includes the investigation of learning-associated brain plasticity throughout the lifetime in normal, expert (musicians), clinical populations (dyslexia; autism; hearing loss) and animal models. Dr. Kraus is known to be a pioneering thinker and innovator whose work bridges multiple disciplines. While some researchers consider 20 publications a career, Nina has that many just for 2013, and it’s only July!
Dr Kraus’s research is not only recognized by audiologists and scientists, but is known internationally by the general public thanks to reports on NPR, BBC, Wall Street Journal, NY Times and articles in National Geographic, Nature and of course, AudiologyOnline.
In this article, Nina gives us a glimpse of some the research from her auditory neuroscience laboratory related to speech understanding. Many of her observations relate to our everyday clinical findings, and may help explain why some patients do better than others in background noise. To fully appreciate the breadth of the work she is doing I encourage you to visit her website: https://www.brainvolts.northwestern.edu.
Gus Mueller, Ph.D.
Contributing Editor
July 2013
To browse the complete collection of 20Q with Gus Mueller articles, please visit www.audiologyonline.com/20Q
20Q: Noise, Aging and the Brain - How Experience and Training Can Improve Communication
 |
| Nina Kraus |
1. I’m glad we’re talking about understanding speech in background noise. That has always been a really a big deal for me when fitting amplification devices.
Yes, amplification technology that is adequate for providing audibility in quiet has been around for a long time, ever improving, right up to today’s cochlear implant era. But as soon as background noise comes into play—whether it is the droning of an air conditioner, traffic noise, or worst of all, competing talkers that you might encounter at a restaurant—technological advances sometimes fall short for people with hearing loss. Even with today’s directional microphone technology and digital noise reduction, many individuals continue to have problems in these difficult listening situations.
2. And don't people without hearing loss have problems hearing in noise, too?
Yes, older people in particular, even in the absence of hearing loss, are notoriously affected by background noise. There is plenty of evidence, hearing status aside, that older adults suffer central processing declines that impact their ability to follow a speech stream in background noise. Humes and colleagues (2012) recently did a nice review of this.
3. Getting back to the patients I fit with hearing aids, if hearing aid technology isn’t completely up to the task, how then can we improve the ability to understand speech in noise?
That’s a good question. It turns out that there are several short- and long-term things that one can do to “train” your ears and brain to listen better in noise.
4. Let’s start with long-term. How long is long? Do you mean lifelong activities?
Yes. A perfect example is playing a musical instrument. It turns out that musicians, on the whole, are better at hearing in noise than non-musicians, everything else being equal. In fact, we have some evidence that hearing-impaired musicians understand speech in noise better than otherwise-matched normal-hearing nonmusicians (Parbery-Clark, Anderson, & Kraus, 2013). This hearing in noise advantage is seen in a number of domains: perceptual testing, questionnaires, and physiology. Bharath Chandrasekaran and I published a review article on the effects of music training a couple years ago (Kraus & Chandrasekaran, 2010). We review literature showing music training’s effect on speech, language, emotion, auditory processing, attention and memory. In fact, it is the cognitive workout that music provides that brings about improvements in speech perception and other domains (Anderson, White-Schwoch, Parbery-Clark, & Kraus, 2013a; Kraus, Strait, & Parbery-Clark, 2012). Ani Patel has proposed a compelling model for how music training would affect speech perception in particular (Patel, 2011). Among other things, music places a high demand on the sound processing centers of the brain, thus priming those areas for the perception of speech. Oh, and by the way, before you ask, it seems like active engagement with music—that is playing and performing music—is necessary to see these effects. Simply listening to music does not seem to have an impact on listening, language and cognitive skills. You don’t get physically fit watching spectator sports.
5. Could it be that musicians simply had above-average brain processing for auditory signals to begin with, and that is related to why they became musicians?
Great question. The “chicken or egg” question is a longstanding conundrum that can be addressed in at least two ways. The first is to examine musicians longitudinally. That is, did speech perception improve after beginning to play an instrument compared to before they started? And does it continue to improve with playing? The second is to look at a cross section of musicians and see if there is a relationship between the duration of musical training and the skill in question. So, do people that have been playing piano for ten years hear in noise better than those that have played three years? Using both of these approaches, there is evidence that a brain with a priori superior processing skills is not the root of the musician advantage.
6. That’s all extremely interesting. So being a musician can help speech perception? What other lifelong activities might help someone hear speech in noise?
Well, speaking a second language, especially if you’re fluent at it. If, for example, you speak one language with your family and another at work or school, you will be constantly switching back and forth between the two languages. This mode-switching requires attention; the attention you are constantly exercising and honing as a bilingual enables you to focus on a speech stream in a noisy environment. And we have found evidence of the biology underlying this phenomenon (Krizman, Marian, Shook, Skoe, & Kraus, 2012).
7. Well, that is certainly a motivation to have my patients dust off their old “Learn Spanish in a Week” CDs. But, the sad fact is I doubt that many of them are bilingual, and their musical experience is probably not much more than a losing battle with a squawking clarinet in the fifth grade. Is there any hope for them tuning up their hearing in noise ability?
You’re right, it might be too late for them to have a long-term effect. But short-term training can help with hearing in noise, too. There have been studies in experimental animals verifying this. And with the right training, including some commercially available “brain training” products, working memory and speed of processing can be improved in older adults (Berry et al., 2010) and outcomes may include increased ability to hear in noise. One of the chief bugaboos of hearing in noise, of course, is getting the consonants. The vowels usually come through just fine, in addition to things like intonation. But consonants are especially tricky. They are low in amplitude and, compared to vowels, they are extremely short. And, related to your hearing aid patients, there often is less gain available for these higher frequencies, which may occur at 4000 Hz and above. This is a well-known issue and there are training programs that focus on training consonant distinctions. We have seen, in studies of both younger and older adults, that hearing in noise ability does in fact improve with short-term software-based training. We have seen biological evidence, too (Anderson, White-Schwoch, Parbery-Clark, & Kraus, 2013b; J.H. Song, Skoe, Banai, & Kraus, 2012). An exciting line of research that we would like to pursue is what happens when older people take up music lessons. I suspect that because playing an instrument is more inherently rewarding than brain-training computer programs, it should be even more effective.
8. Okay, so maybe there is hope. But, what exactly is going on? Training or music or speaking multiple languages does not make someone’s ears hear any better.
We, as a field, are moving away from an antiquated idea of hearing as strictly peripheral processing of sound. More and more attention is being given to the idea of a “cognitive auditory system” which involves central processing, cognition, attention, memory, etc., as well as life experiences. All of these higher-level functions operate as part of a dynamic circuit, deeply affecting the ability to hear in noise. In fact, in a group of older individuals, we have modeling data that peripheral hearing plays only a minor role in hearing in noise success (Anderson et al., 2013a).
9. This all sounds good, but I deal with real patients, not computer modeling—what about proof? Can these brain changes that go on with training and experience be quantified?
They certainly can. Now you’re getting into my wheelhouse! We have an exquisitely sensitive neurophysiological measure of the cognitive auditory system.
10. What part of the auditory system are you referring to?
Well, the short answer is the auditory brainstem. But, it is much more nuanced than that. Most of our readers are familiar with the auditory brainstem response (ABR). It has been in clinical use for many decades and when used with click or pure-tone stimulation is a terrific measure of peripheral processing.
11. Oh sure, like everyone, I’ve done my share of ABRs, but where does the nuance come in?
The click- or tone-evoked ABR is really a good metric of “upstream” auditory function. The click activates the hair cells in the cochlea and the electrical signal is propagated through the auditory brainstem, culminating in activity that can be picked up at the scalp with a few electrodes. But, and this is the key… the brainstem has just as many “downstream” connections as upstream. It is enervated by structures including the auditory cortex and beyond. Clicks or pure tones, in and of themselves, are not very meaningful. They are rarely encountered outside of a lab or clinic setting, so the patient does not have any real experience with them. But what about a word or a syllable or a musical note? These sounds are complex acoustically and have inherent meaning because people have vast experience with speech and music. So there is much more going on when you record an ABR to a complex sound (we call it “cABR;” the “c” is for complex). The downstream connections are kicking in and shaping what the electrodes are picking up; it is not a simple case of sound-in, brainwave-out upstream encoding.
12. So it’s more than just a brainstem response?
Right—we’re back to the “cognitive auditory system” that I mentioned earlier. Although yes, it is a “brainstem” response, I want to emphasize that where the response comes from is far less important than the fact that the response is a consistent and rich metric of the auditory system as a glorious whole. With cABR, my lab and others have shown the profound impact that experience and training have on the auditory system (Anderson et al., 2013b; Bidelman & Krishnan, 2012; Krizman et al., 2012; Xu, Krishnan & Gandour, 2006). It can be reliably measured in individuals, and is relatively accessible and affordable, compared to MRI, for example, which has revealed cortical activity covaries with hearing in noise ability in older adults (Wong et al., 2009).
13. What does a cABR look like? Is there more to it than the familiar waves I through V that I’m used to seeing?
The cABR looks very much like the stimulus. If you present a speech syllable as the stimulus, the response looks like the syllable. A musical note looks like a musical note. And my favorite parlor trick: if you play back a brainstem response to speech or music through a speaker, it sounds more-or-less like the sound that evoked it. Figure 1 shows speech and music examples of this and there are some auditory demonstrations on my lab’s website, www.brainvolts.northwestern.edu. Click the “demonstration” link on the home page and make sure your speakers are on. While there, please look around. We are always updating the website, on an almost daily basis. We have several slideshows that provide a good overview of my lab’s research under each project.
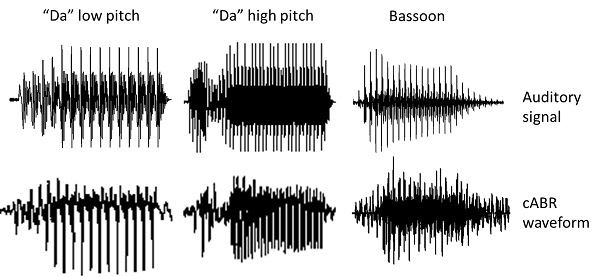
Figure 1. The cABR waveform looks like the signal used to evoke it. The top row shows the auditory signals for "da" (low pitch voice, left column; high pitch voice, center column) and a bassoon (right column), each with the corresponding cABR waveform below it in the bottom row.
14. Sounds cool. I’ll take a look at your website. So I take it we are not just interested in a handful of discrete peak latencies like we are for the click ABR?
Peak latencies remain important. But rather than just a couple peaks, as with a click stimulus, there can be dozens and dozens depending on the sound. For example, a typical voiced speech sound has a periodicity to it—the tone of voice or the fundamental frequency. Someone with a deep voice will have a voice pitch of 80 Hz or so and someone with a high voice, like a child, might be in the hundreds of Hz. Each cycle of the voicing will elicit a peak, as can be seen in Figure 1. The left and center columns depict “da” spoken with a low voice and a high voice and their respective resulting cABR waveforms. Additionally, as you may know, there is a whole world of digital signal processing routines that can be applied to sounds like speech. Everything from spectral and autocorrelation analyses to investigate spectral and periodic aspects of the signal, to phase analyses to examine subtle timing differences between two signals. Each of these techniques can be used with good results on cABR waveforms as well as the evoking sounds. In fact, the similarity between stimulus and response enables a direct comparison of the two, a valuable technique that is not possible with a click because of the dissimilarity of response to stimulus. The cABR provides a wealth of information that transcends the limited repertoire of analysis techniques available to a classic click ABR waveform. Erika Skoe and I wrote a tutorial that covers a bunch of these analysis techniques as well as data collection concerns (Skoe & Kraus, 2010), and the “technologies” link on my lab’s website has a short slideshow that covers some of this ground.
15. So I understand—You are saying these techniques can be used to contrast the response of someone who can easily understand speech in noise with someone who has difficulty with it?
Sure. That’s one reason I’m so fond of this approach. There is something of a signature response to speech in a poor listener in noise. A stimulus we frequently use is “da.” It is a male voice, with a fundamental frequency of 100 Hz. The waveform is very complex for the first 50 ms or so, as the sound changes from the acoustically complex consonant “d” to the vowel “a.” Then, from 50 ms to the end of the utterance, the “a” is a reasonably simple periodic wave. There are two things that stand out in the cABR to “da” of a person who has difficulty hearing in noise. First, the peaks within the initial complex 50-ms region of the syllable are delayed relative to an otherwise matched “good” listener in noise. Second, in the frequency domain, the 100 Hz representation—that is, the voice pitch—is diminished (J. Song, Skoe, Banai, & Kraus, 2011). This is notable because the fundamental frequency is one of the most crucial cues to following speech in a noisy background. It has to do with concepts you might be familiar with like auditory object formation, stream segregation, and the ability to “tag” a voice as unique from other competing voices. The relationship between voice pitch encoding and speech in noise perception is shown in Figure 2, left. The larger the fundamental frequency of the response to “da,” the better the behavioral speech in noise (SIN) perception. Interestingly, the latter part of the response, to the vowel “a,” in a poor listener in noise is relatively unaffected—looking very much like that of a good listener in noise. Vowels are “easy.”
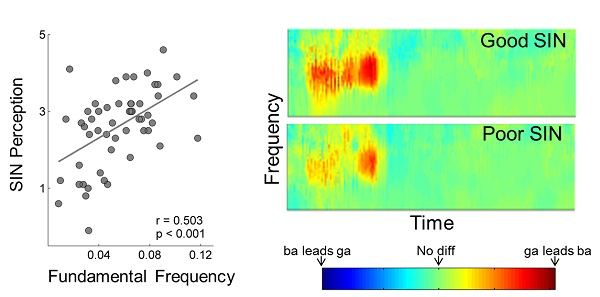
Figure 2. The relationship between voice pitch encoding and speech in noise perception is shown in the left panel. The panel on the right shows that the larger the fundamental frequency of the response to “da,” the better the behavioral speech in noise (SIN) perception. Note that the latter part of the response, to the vowel “a,” shows little difference between a poor listener in noise and a good listener in noise.
16. So the vowel serves as a kind of built-in control?
You could say that, yes. One of the attractive things about cABR is that neither enhancements nor decrements are monolithic. Different aspects of the response are selectively affected by training, experience, communication ability, etc; it is not like turning a volume knob. This is what makes the idea of signature responses possible. Figure 2, right, demonstrates both the selective nature of the speech-in-noise cABR signature and further illustrates the importance of consonants. This color graph is a depiction of the cABR timing differences between a “ba” and and “ga” stimulus. Typically, a “ga” response will be slightly earlier in phase than a “ba” response and this is shown in red in the left portion of the pictures. If “ba” were earlier than “ga” it would be blue. When there is no phase difference, it is green. In the consonant portion of the response, people who are good at listening to speech in noise have greater phase differences (deeper reds). But there is no difference between groups in the vowel (rightmost green)—an example of selective enhancement.
17. If someone has a “poor hearing in noise” cABR signature, might his signature change to a “good hearing in noise” signature following training?
We have seen evidence of that. In the short-term brain training studies I mentioned before, the cABR following training took on a “good listening in noise” signature: robust fundamental frequency representation and fast timing in the consonant-vowel transition.
18. Are there cABR signatures for things other than “poor listening in noise?”
This is something that my lab is hotly investigating right now. We are beginning to discern signatures of aging, autism, bilingualism, and even reading ability (Kraus & Nicol, 2013).
19. It sounds like you indeed have “proof” that training works, so let’s get practical. Can old dogs be taught new tricks? If some of my hearing aid patients start studying piano now as an adult, do you think they might begin hearing in noise better as a side effect?
My guess is yes. That is an important question that needs answering. What kind of training works? Computer training games might be effective, but they are not very motivating in the long term. And, in our studies comparing and contrasting lifelong effects of music with short-term computer-based activities, the musicians always come out on top. So, although it was hard to disambiguate music training from computer training on a level playing field, it is certainly the case that due to its inherently more emotionally and intellectually satisfying nature, music training is more likely to engage an adult for a longer period of time than a brain-training game.
 20. I’m on my last question so I have to ask—Are you a musician? A bilingual? And how is your hearing in noise?
20. I’m on my last question so I have to ask—Are you a musician? A bilingual? And how is your hearing in noise?
I am both. I play guitar and piano and speak English, Italian and German. And can you repeat the last question please? There was some noise in the background and I didn’t understand you.
References
Anderson, S., White-Schwoch, T., Parbery-Clark, A., & Kraus, N. (2013a). A dynamic auditory-cognitive system supports speech-in-noise perception in older adults. Hearing Research, 300C, 18-32. doi: 10.1016/j.heares.2013.03.006
Anderson, S., White-Schwoch, T., Parbery-Clark, A., & Kraus, N. (2013b). Reversal of age-related neural timing delays with training. Proceedings of the National Academy of Sciences of the United States of America, 110(11), 4357-4362.
Berry, A. S., Zanto, T. P., Clapp, W. C., Hardy, J. L., Delahunt, P. B., Mahncke, H. W., & Gazzaley, A. (2010). The influence of perceptual training on working memory in older adults. PLoS ONE, 5(7), e11537. doi: 10.1371/journal.pone.0011537
Bidelman, G. M., & Krishnan, A. (2010). Effects of reverberation on brainstem representation of speech in musicians and non-musicians. Brain Research, 1355, 112-125. doi: 10.1016/j.brainres.2010.07.100
Humes, L. E., Dubno, J. R., Gordon-Salant, S., Lister, J. J., Cacace, A. T., Cruickshanks, K. J., . . . Wingfield, A. (2012). Central presbycusis: A review and evaluation of the evidence. Journal of the American Academy of Audiology, 23(8), 635-666. doi: 10.3766/jaaa.23.8.5
Kraus, N., & Chandrasekaran, B. (2010). Music training for the development of auditory skills Nature Reviews Neuroscience, 11, 599-605.
Kraus, N., & Nicol, T. (2013). The cognitive auditory system. In R. Fay & A. Popper (Eds.), Springer handbook of auditory research (Vol. 50, pp. in press.). Heidelberg, Germany: Springer-Verlag.
Kraus, N., Strait, D., & Parbery-Clark, A. (2012). Cognitive factors shape brain networks for auditory skills: Spotlight on auditory working memory. Annals of the New York Academy of Sciences, 1252, 100-107.
Krizman, J., Marian, V., Shook, A., Skoe, E., & Kraus, N. (2012). Subcortical encoding of sound is enhanced in bilinguals and relates to executive function advantages. Proceedings of the National Academy of Sciences of the United States of America, 109(20), 7877-7881. doi: 10.1073/pnas.1201575109
Parbery-Clark, A., Anderson, S., & Kraus, N. (2013). Musicians change their tune: How hearing loss alters the neural code. Hearing Research, in press. doi: 10.1016/j.heares.2013.03.009
Patel, A. D. (2011). Why would musical training benefit the neural encoding of speech? The OPERA hypothesis. Frontiers in Psychology, 2, 142. doi: 10.3389/fpsyg.2011.00142
Skoe, E., & Kraus, N. (2010). Auditory brainstem response to complex sounds: A tutorial. Ear & Hearing, 31(3), 302-324.
Song, J., Skoe, E., Banai, K., & Kraus, N. (2011). Perception of speech in noise: Neural correlates. Journal of Cognitive Neuroscience, 23(9), 2268-2279.
Song, J. H., Skoe, E., Banai, K., & Kraus, N. (2012). Training to improve hearing speech in noise: Biological mechanisms. Cerebral Cortex, 22(5), 1180-1190. doi: 10.1093/cercor/bhr196
Wong, P. C., Jin, J. X., Gunasekera, G. M., Abel, R., Lee, E. R., & Dhar, S. (2009). Aging and cortical mechanisms of speech perception in noise. Neuropsychologia, 47(3), 693-703.
Xu, Y., Krishnan, A., & Gandour, J. T. (2006). Specificity of experience-dependent pitch representation in the brainstem. Neuroreport, 17(15), 1601-1605.
Cite this content as:
Kraus, N. (2013, July). 20Q: Noise, aging and the brain - how experience and training can improve communication. AudiologyOnline, Article 11990. Retrieved from: https://www.audiologyonline.com/

